Nvidia Patents a Domain-Specific Retrieval System That Learns Your Vocabulary
Most AI search tools stumble on jargon — medical codes, internal product names, legal shorthand. Nvidia's latest patent describes a system that trains itself on the specific vocabulary inside your private document collection before it ever tries to search it.
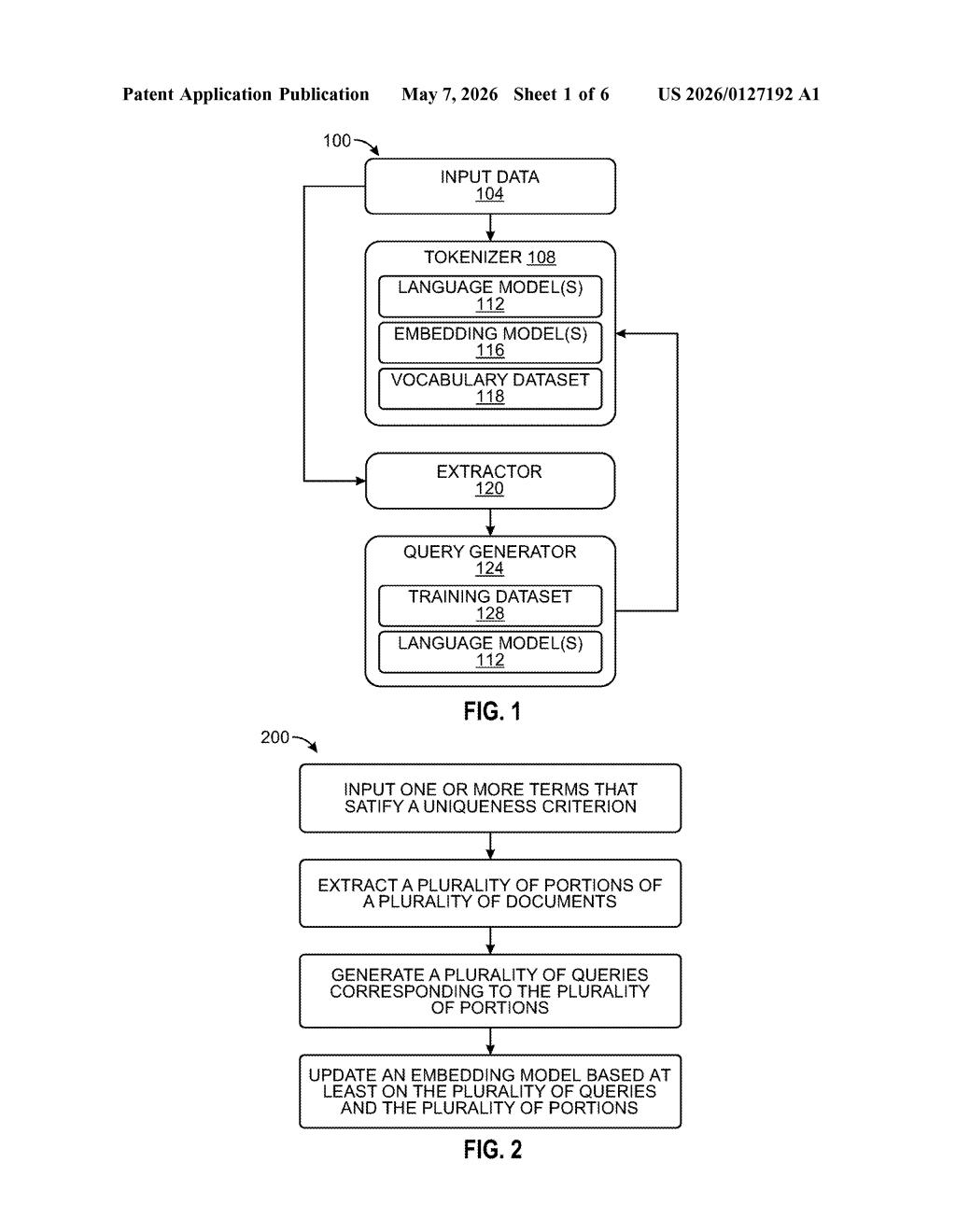
What Nvidia's custom-vocabulary retrieval system actually does
Imagine you work at a biotech company with thousands of internal research documents full of proprietary compound names and internal shorthand. You build an AI assistant to search those docs — but it keeps missing results because it doesn't recognize your terminology. That's the problem this patent is trying to fix.
Nvidia's system starts by scanning your document collection and pulling out terms that are uniquely specific to that domain — words a general-purpose AI wouldn't know. It feeds those terms into a tokenizer (the piece of software that breaks text into units the AI understands), then uses them to retrain a search model so it actually knows what those terms mean in context.
The end result is a retrieval model that's been tuned to your specific world — whether that's aerospace engineering, internal legal briefs, or pharmaceutical research. When you ask it a question, it knows the vocabulary well enough to find the right documents, not just documents that look superficially similar.
How Nvidia's embedding model learns domain-specific terms
The patent describes a pipeline with four main components working in sequence:
- Uniqueness filtering: The system scans a corpus of documents and identifies terms that meet a "uniqueness criterion" — essentially, words or phrases that are domain-specific and wouldn't appear in a general training set. Think proprietary chemical names, internal SKU codes, or field-specific acronyms.
- Tokenizer update: Those unique terms are fed into a tokenizer, which adds them to a vocabulary dataset. A tokenizer is the front-end of any language model — it converts raw text into numerical tokens the model can process. Without knowing a term, the model can't reason about it properly.
- Synthetic query generation: The system extracts document segments containing those terms and automatically generates queries that correspond to each segment — essentially creating question-answer pairs for training without human labeling.
- Embedding model fine-tuning: Using the vocabulary dataset, the document segments, and the generated queries together, the system updates an embedding model (a neural network that converts text into numerical vectors for semantic similarity search). This makes the model better at understanding and retrieving domain-specific content.
The approach is directly relevant to RAG (Retrieval-Augmented Generation) pipelines — systems where an LLM answers questions by first retrieving relevant documents. A better retrieval model means more accurate answers.
What this means for enterprise AI search and RAG pipelines
Enterprise AI is increasingly built on RAG — companies want to ask questions of their own internal knowledge bases rather than rely solely on what a model learned during pre-training. The weak link is almost always retrieval quality: if the search layer doesn't find the right documents, the LLM generates a confident but wrong answer.
Nvidia's approach targets that weak link directly by making the embedding model learn your vocabulary before you deploy it. For companies in specialized fields — pharma, defense, finance, legal — this could meaningfully close the gap between a generic retrieval model and one that actually understands what your documents are talking about. Given Nvidia's position selling AI infrastructure to enterprises, this also slots neatly into the kind of tooling they'd want to bundle with their data center offerings.
This is solid, unglamorous AI infrastructure work — the kind of thing that doesn't generate headlines but quietly makes enterprise AI deployments much more reliable. The synthetic query generation step is the most interesting piece: automating the creation of training pairs from domain documents sidesteps one of the biggest bottlenecks in fine-tuning, which is the need for expensive human-labeled data. Worth watching if you're building or evaluating RAG systems.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.