Nvidia's New Patent Teaches Its Voice AI to Grade Its Own Work
Teaching an AI to understand speech and generate speech at the same time — and letting each half grade the other's homework — is one of the harder problems in voice AI. Nvidia just filed a patent for a system that does exactly that.
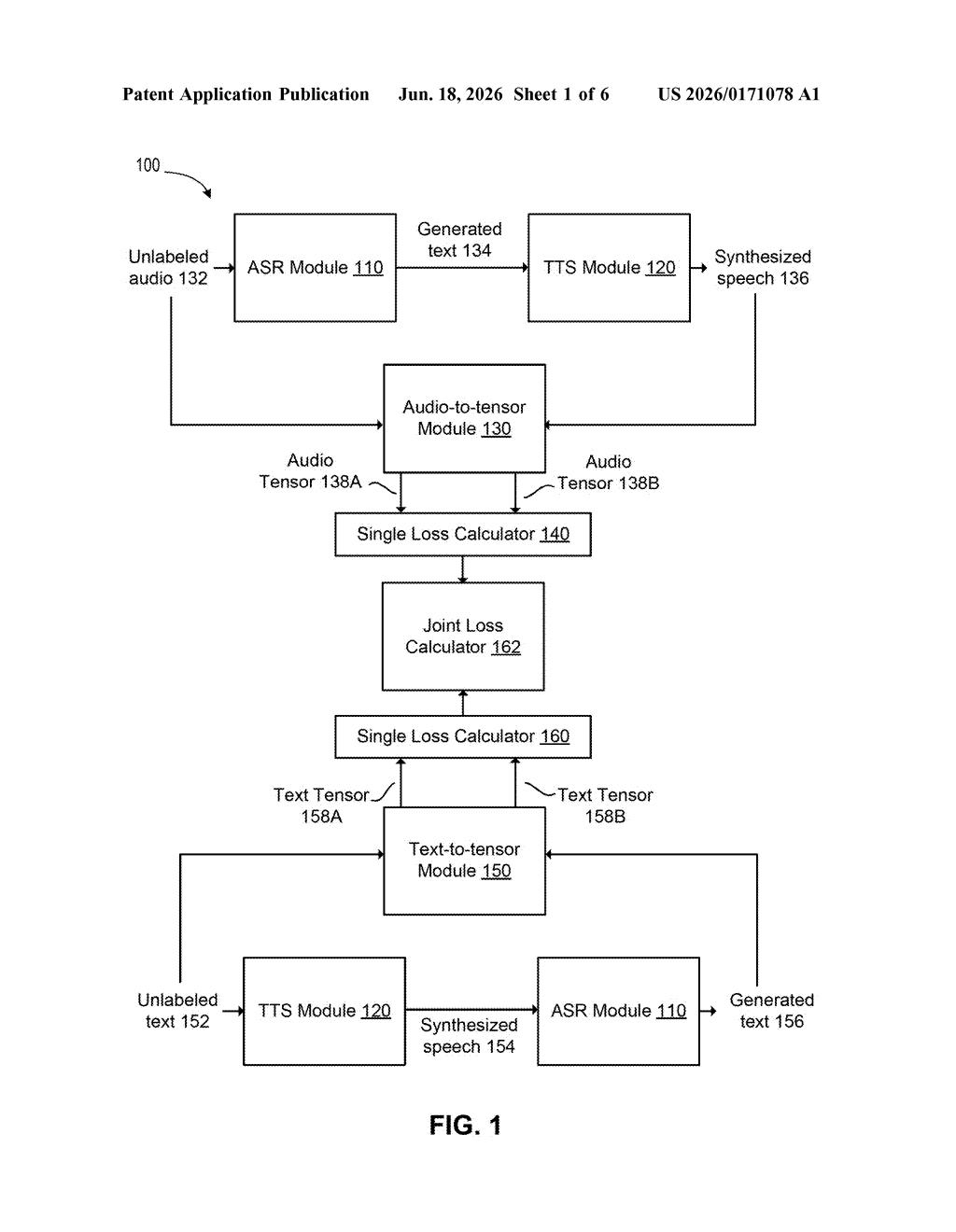
How Nvidia's speech AI learns without labeled data
Imagine a student who learns a foreign language by constantly translating sentences back and forth: from English to French, then back to English, checking whether the round-trip produces something that matches what they started with. Nvidia's patent applies the same idea to voice AI. A speech-to-text model and a text-to-speech model are trained together, each one correcting the other in a loop.
Here's the clever part: the system doesn't need a massive library of human-labeled recordings to learn. Instead, it generates its own training examples, scores how believable they sound or read, and only adds the good ones to its training set. A separate component called a discriminator acts like a quality inspector, rejecting samples that don't pass muster.
The goal is a voice AI that can transcribe what you say and speak back to you more naturally — without requiring thousands of hours of hand-labeled audio to get there.
How the cycle-consistency loop and diffusion-GAN fit together
The patent describes a training framework that links two AI models in a feedback loop. The first is an automatic speech recognition (ASR) model — the kind that turns spoken words into text. The second is a text-to-speech (TTS) model — the kind that converts written text into spoken audio. Instead of training each one separately on labeled datasets, Nvidia trains them together using what researchers call a cycle-consistency objective (the idea that if you convert audio → text → audio, the final audio should closely match the original).
The system measures that match by comparing tensor representations — essentially numerical fingerprints of the audio — and penalizes the models when those fingerprints don't match closely enough. That penalty is built into the loss function, the mathematical signal that tells the AI how badly it performed during training.
At the core of the architecture is a diffusion-GAN (diffusion generative adversarial network), a type of AI model that combines two popular approaches to generating realistic audio:
- Diffusion models, which learn to reconstruct clean signals from noisy ones
- GANs (generative adversarial networks), where a generator tries to fool a discriminator that judges whether outputs are real or fake
Nvidia's discriminator is unusual in that it uses multiple timestep-dependent sub-discriminators — meaning different judges evaluate the audio at different stages of the generation process, making quality control more fine-grained.
What this means for voice assistants and conversational AI
The practical payoff here is that Nvidia could build voice AI systems that need far less human-annotated training data — a major cost and bottleneck in the industry. If the models can generate and self-validate their own training examples, you can scale up without hiring armies of transcriptionists.
For conversational AI — think voice assistants, call-center bots, or real-time translation earbuds — better joint training of speech-in and speech-out models could mean more natural back-and-forth interactions. Nvidia's GPU and AI inference businesses make this directly relevant to their data-center customers building voice products, not just a research curiosity.
This is solid AI infrastructure work, not a consumer product announcement. The cycle-consistency approach isn't a new idea in machine learning, but combining it with a diffusion-GAN architecture and a self-curating training loop is a meaningful engineering contribution. If Nvidia ships this into its NeMo speech toolkit or inference platforms, it could quietly reduce the cost of building production-grade voice AI by a meaningful margin.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.