Nvidia Patents an AI Audio Model That Restores and Separates Speech Without Labeled Training Data
Teaching an AI to clean up audio is hard partly because you need huge amounts of labeled examples showing 'dirty' audio next to 'clean' audio. Nvidia's new patent describes a way to skip that step entirely.
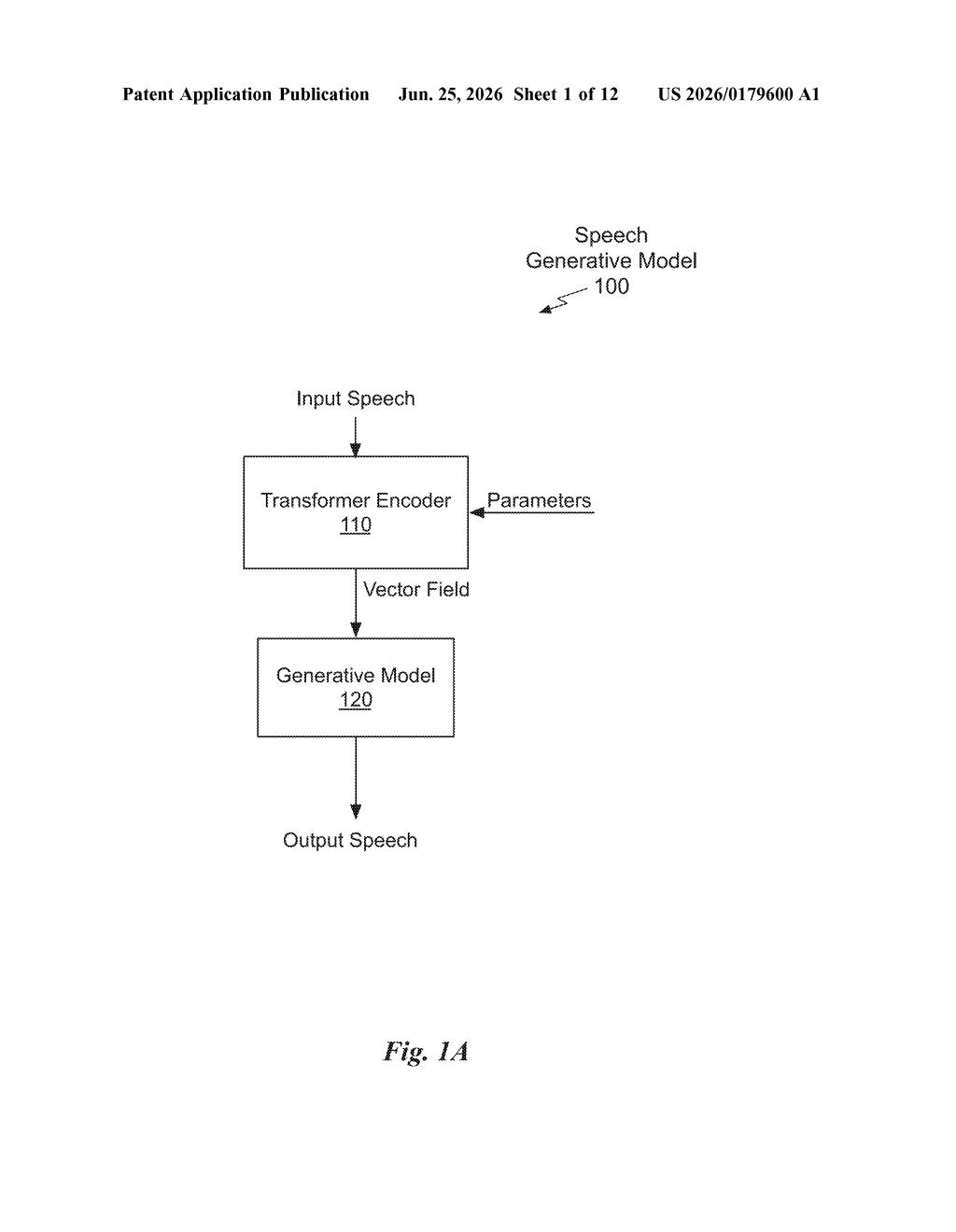
What Nvidia's AI audio cleanup model actually does
Imagine you're on a video call and your voice is getting drowned out by a loud fan, a barking dog, or background chatter. Today's noise-removal tools are trained on thousands of pre-labeled examples of noisy versus clean audio, which is expensive and time-consuming to produce. Nvidia's patent describes an AI model that learns to clean up audio without needing those labels at all.
The system works a bit like a fill-in-the-blank exercise. It intentionally hides parts of an audio signal, then trains itself to predict what was missing, building up a general understanding of how speech and sound are structured. Once it has that foundation, you can quickly tune it for specific jobs: removing background noise, isolating a single speaker in a crowd, or doing both at once.
The practical upside is that this kind of model is cheaper to build and easier to adapt. Instead of training a brand-new AI from scratch every time someone needs a different audio task, you start from one solid base and adjust from there.
How the transformer maps and restores masked audio signals
The patent describes a generative signal foundation model designed to handle two closely related audio jobs: restoration (cleaning up a degraded signal) and extraction (pulling out one specific sound, like a voice, from a mix).
The core technique works in three steps:
- Masking: The system takes an incoming audio signal and deliberately blanks out portions of it, much the way a masked language model like BERT hides words in a sentence before asking the AI to guess them.
- Transformer processing in a latent space: The masked signal is converted into a mathematical representation (called an invertible domain), where a transformer-based neural network predicts a "vector field of coefficients" to fill in what was removed. A transformer here is the same class of AI architecture behind large language models, applied to audio instead of text.
- Inverse transform: The predictions are converted back into a real audio waveform, producing either a cleaned-up version of the original signal or a version with a specific sound removed.
Critically, the model is pretrained on unlabeled data, meaning it doesn't need pre-paired examples of noisy and clean audio. After pretraining, it can be fine-tuned for specific tasks with far less additional training data than a purpose-built model would require.
What this means for real-time voice and audio tools
The expensive part of training audio AI has always been the data: someone has to record or curate matched pairs of clean and noisy audio, which is slow and costly to do at scale. A foundation model that learns from unlabeled audio sidesteps that bottleneck entirely, opening the door to better noise cancellation, voice isolation, and audio cleanup tools that can be built and adapted faster.
For you as an end user, the downstream effect could show up in video conferencing, gaming headsets, hearing aids, podcast editing tools, and real-time translation software. Nvidia already sells audio AI products through its RTX hardware and Maxine platform, so this kind of research fits directly into products that developers and consumers are already using.
This is solid, practical AI research rather than a flashy product announcement. The shift toward foundation models in audio mirrors what already happened in language and image AI, and Nvidia filing in this space signals they want to own the infrastructure layer for audio the same way they've come to own it for graphics and general AI compute. The unlabeled pretraining angle is the genuinely interesting part here.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.