Samsung Patents an AI That Answers Questions About Charts and Diagrams in Your Documents
Most AI document assistants are good at reading text but fall apart the moment a page has a chart, a diagram, or an infographic. Samsung's new patent describes a system that specifically hunts down those visual elements to answer your questions.
What Samsung's document-reading AI actually does
Imagine you upload a 40-page annual report and ask, 'What were the Q3 sales figures?' Most AI tools scan the written text and miss the bar chart on page 22 that actually answers your question. Samsung's patent describes a system built to fix that.
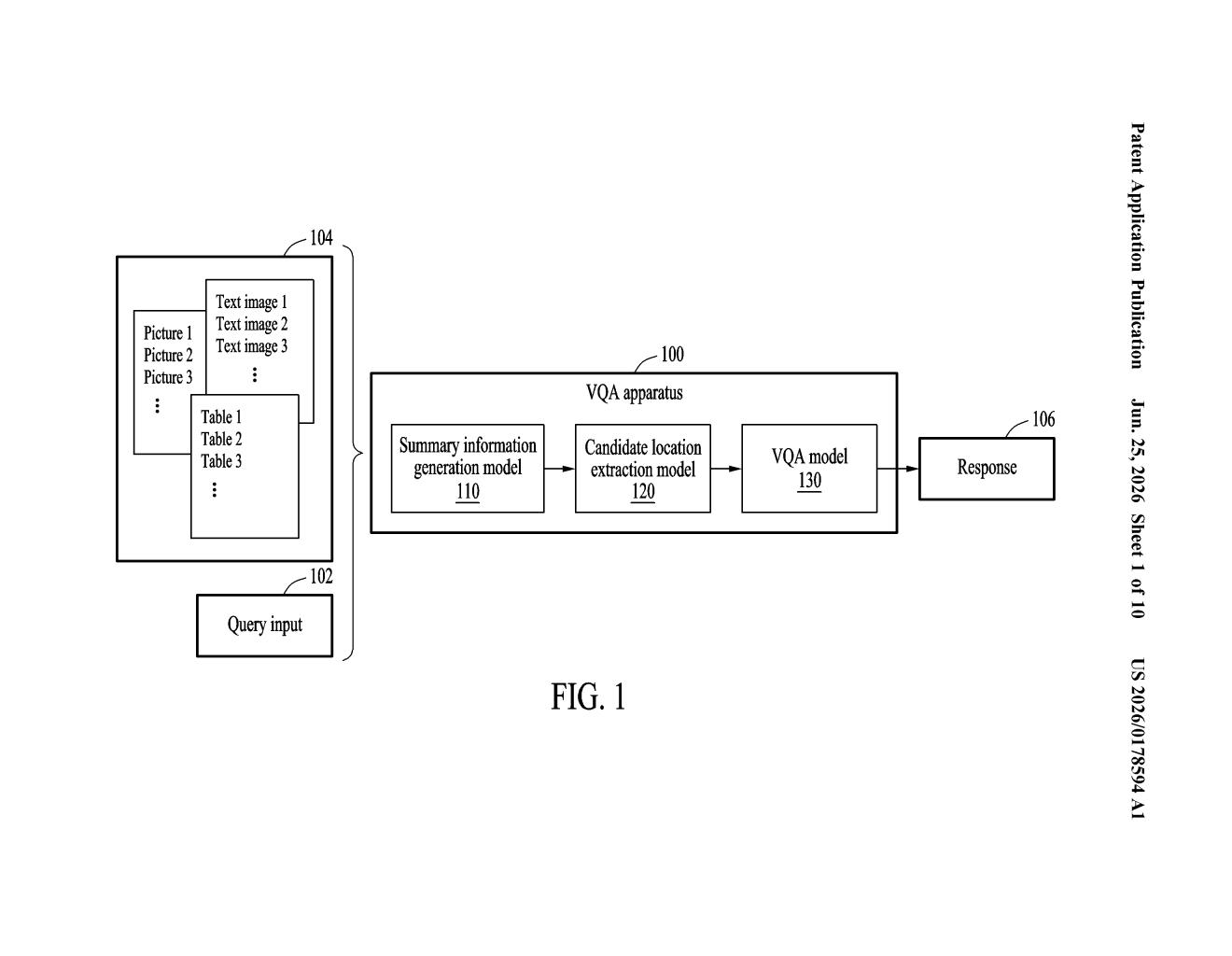
The system first reads your whole document and makes a kind of map: a summary of each section along with a note about where that section lives in the document. When you ask a question, a second AI uses that map to figure out which part of the document is most likely to hold the answer. Then a third, specialized AI looks directly at the visual content in that specific spot, whether that's a graph, a table, or an image, and answers your question based on what it sees.
The result is an assistant that can handle the kinds of documents real businesses actually use, ones where the most important information is often in a picture, not a paragraph.
How the three-model pipeline finds and reads visual content
The patent describes a three-stage pipeline for Visual Question Answering (VQA), the task of answering questions about images or image-containing documents.
- Stage 1 - Summary map generation: A model reads the entire document and produces two things for each section: a text summary of its content and a location tag (think page number or bounding-box coordinates) pinpointing where that section sits. These are bundled into what the patent calls context data.
- Stage 2 - Candidate location extraction: When the user submits a question, a second model receives the question plus the full context data as a prompt. It infers which location (or locations) in the document are most likely to contain a relevant answer. This is essentially a retrieval step, narrowing the search space before any heavy visual processing happens.
- Stage 3 - VQA model response: A dedicated visual question answering model receives the graphic content (charts, diagrams, images) at the candidate location alongside the original question and produces a final answer.
The key architectural choice is separating the where-to-look problem from the how-to-read-visuals problem. Rather than feeding an entire document into one large model (expensive and often inaccurate), the system pre-filters to the relevant visual region before invoking the costlier VQA step.
What this means for AI assistants handling real business documents
Enterprise documents, financial reports, scientific papers, engineering specs, are full of charts and diagrams that carry critical information. Current AI assistants that rely on plain-text extraction routinely skip or misread that content. A pipeline that explicitly locates and then reads the visual portions of a document would make AI assistants meaningfully more reliable for real work tasks.
For Samsung, this filing fits a broader push to make its Galaxy AI features more capable with productivity documents on phones and tablets. If this approach ships in a product, it would let you point your device at a document and ask a question about a graph and actually get a useful answer, rather than a hallucinated one drawn from the surrounding text.
This is a genuinely practical patent. The three-stage design (summarize, locate, then visually read) is a sensible engineering answer to a real limitation in current AI document tools. It won't make headlines, but it's the kind of plumbing work that separates a useful AI assistant from a frustrating one.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.