Nvidia Patents a Self-Teaching Neural Renderer That Reconstructs 3D from 2D Images
Nvidia has patented a clever feedback loop where two AI networks teach each other — one generates realistic 2D images of 3D scenes, and the other learns to reverse-engineer the 3D geometry back out. The trick: almost no hand-labeled training data required.
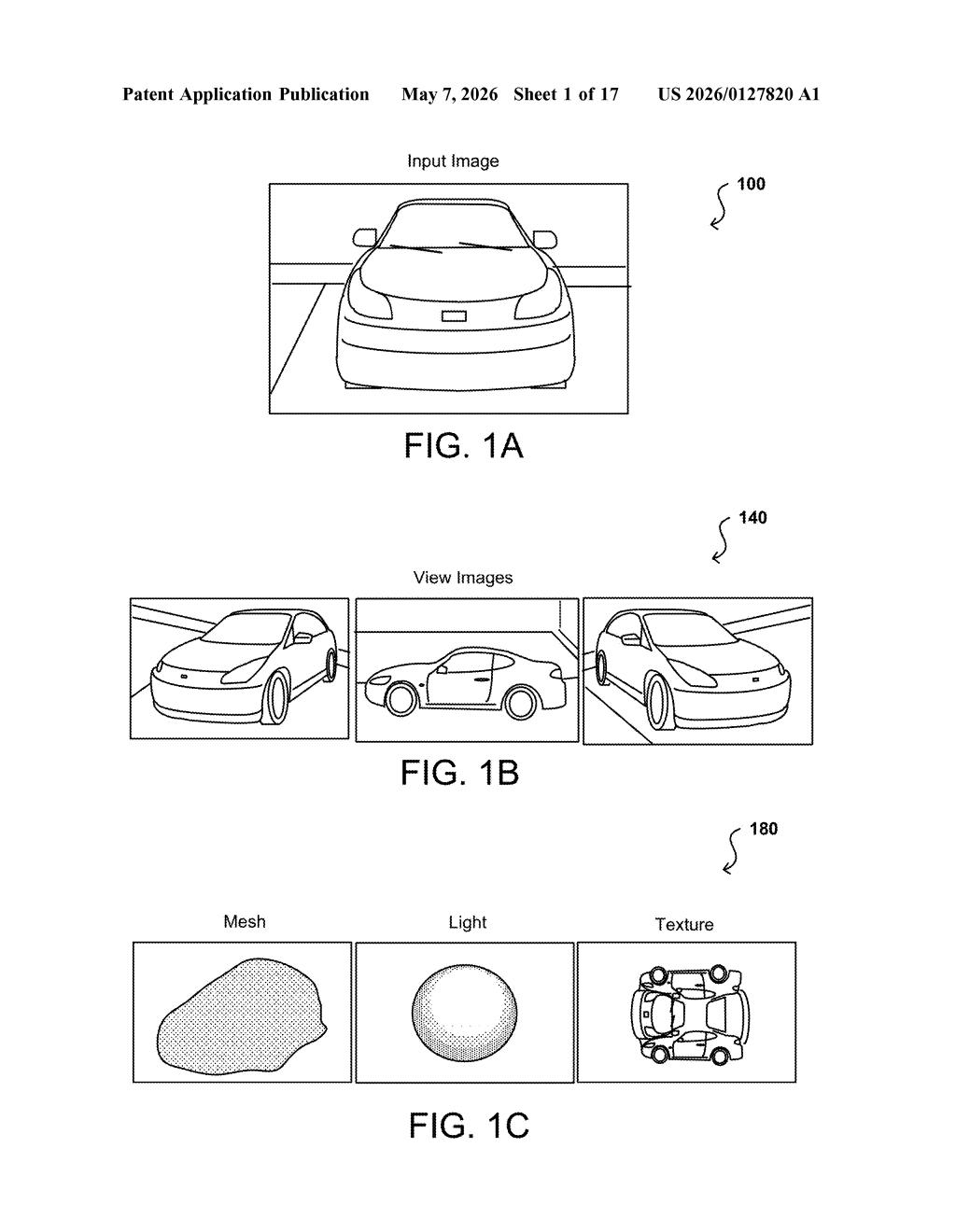
What Nvidia's inverse graphics AI actually does
Imagine you hand an AI a single photograph of a car and it figures out what that car looks like from every angle — without anyone ever drawing the car in 3D or telling the AI where the wheels are. That's the core idea here.
Nvidia's system trains two networks in tandem. One network is a generator — it's already good at making convincing 2D images. The second is an inverse graphics network, which learns to work backward from those images and recover the underlying 3D structure, like camera angle, shape, and lighting. These two networks essentially quiz each other until both get sharper.
The big payoff is that you don't need a warehouse of 3D-annotated training data to make this work. The generator supplies synthetic views of an object from different angles, and the inverse network uses those to learn 3D without ever seeing a labeled 3D model. Less human labor, more capable AI.
How the generator and inverse network teach each other
The patent describes a mutual training loop between two neural networks: an image synthesis network (a generative model that produces 2D images) and an inverse graphics network (which infers 3D parameters from those images).
Here's the flow:
- The system takes a 2D training image of an object and a set of camera poses (virtual viewpoints — think of specifying "look at this object from 30 degrees to the left and slightly above").
- The generator network renders the object from those poses, producing multiple synthetic 2D views.
- Those synthetic views, tagged with their camera pose metadata, are fed to the inverse graphics network as training signal.
- The inverse network learns to extract disentangled 3D properties — meaning it separates shape, texture, and viewpoint into independent variables rather than treating the image as one blob.
The key technical ingredient is a differentiable renderer (a rendering engine that can pass gradients back through the image-formation process, letting the networks learn from rendering errors rather than just classification labels). This lets the generative model act as a controllable neural renderer that complements traditional graphics engines.
Because the two networks reinforce each other, the system requires little manual annotation — a significant practical advantage over supervised 3D reconstruction pipelines.
What this means for 3D content pipelines and AI simulation
For Nvidia, this patent sits squarely in the intersection of generative AI and 3D graphics — two areas the company has been aggressively investing in through Omniverse and its research labs. A system that can lift 3D understanding out of 2D image generators without expensive labeled datasets could dramatically cut the cost of building synthetic data pipelines for robotics, autonomous vehicles, and digital twins.
For you as a developer or researcher, this matters because the bottleneck in 3D AI today is annotated training data — building 3D datasets is slow and expensive. A technique that bootstraps 3D reconstruction from widely available 2D imagery and existing generative models could unlock a lot of applications that currently aren't practical.
This is genuinely interesting research from a team that includes MIT's Antonio Torralba and Nvidia's Sanja Fidler — not a routine filing. The mutual-teaching loop between a generator and an inverse graphics network is an elegant solution to the annotation bottleneck, and the differentiable rendering angle gives it real technical teeth. The fact that it's a continuation of a 2021 patent (now granted) with a 2020 provisional suggests this approach has been maturing for a while and Nvidia is still building on it.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.