Nvidia Patents ML System That Automatically Maps Road Markings for Self-Driving Cars
Building accurate maps for self-driving cars is brutally labor-intensive — someone has to label every lane line, edge, and marking. Nvidia's latest patent describes a machine learning system that automates a big chunk of that job.
How Nvidia teaches AI to read road markings on maps
Imagine you're trying to build a map for a self-driving car. You don't just need roads — you need to know exactly where the lane lines, stop bars, and road edges are. Right now, a lot of that work involves humans staring at images and drawing labels by hand. That's slow and expensive.
Nvidia's patent describes a smarter approach: give an AI model a camera image of a road and a few seed points — just rough hints about where a road marking might be — and let the model figure out the rest. It traces the full shape of the marking, generates a clean line representation, and writes that label directly into the map.
The system works like an image-aware autocomplete. You nudge it with a couple of points, and it fills in the complete picture. The goal is to make map annotation — a notoriously tedious pipeline step — much faster and more consistent, which ultimately means safer, more reliable navigation for self-driving systems.
How the token-and-embedding pipeline traces road lines
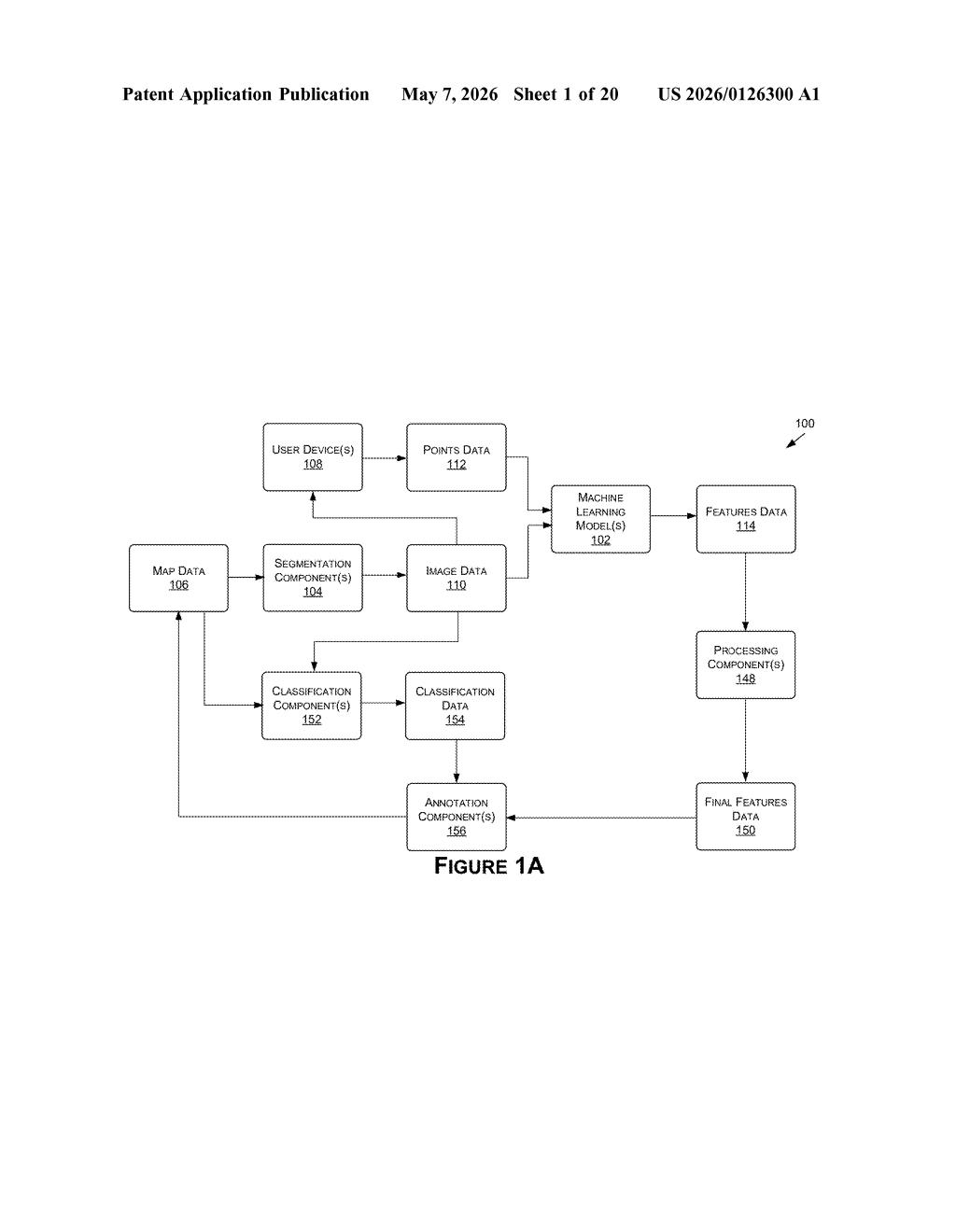
The method works in a few coordinated steps. First, the system takes an image tied to a map — think a bird's-eye or front-facing camera frame — and a handful of input tokens (structured representations of known points along a road marking, like a lane line or road edge).
At the same time, the model generates embeddings from the image itself — a dense numerical encoding that captures visual context like texture, color gradients, and geometry. Think of embeddings as a compressed, math-friendly description of everything the camera saw.
Those two inputs — the point tokens and the image embeddings — are fed into one or more machine learning models (the patent doesn't pin down a specific architecture, but transformer-style models are the natural fit here). The models output output tokens representing additional points that complete the shape of the road marking.
From those points, the system constructs a line representation of the marking — essentially a vectorized path — and uses it to annotate the map with a structured label. A classification step can also categorize what kind of marking it is (dashed lane line vs. solid edge, for example), producing final feature data ready for downstream navigation use.
What this means for autonomous vehicle map pipelines
For autonomous vehicle companies, map quality is a safety variable, not just a convenience one. Self-driving systems often rely on high-definition maps to know where to stay in a lane or when a road edge drops off. Annotating those maps at scale — across thousands of miles of road — is one of the most resource-intensive parts of the pipeline.
A system that can take sparse human input (just a few seed points) and reliably complete a road marking label could dramatically cut the cost and time of that process. For Nvidia, whose DRIVE platform powers AV development for dozens of automakers and robotaxi companies, tooling that accelerates map production is a genuine competitive lever — not just internal efficiency.
This is quiet but real infrastructure work. It won't show up in a product announcement, but the companies building self-driving stacks care deeply about map annotation throughput. Nvidia filing in this space signals they're investing in the full AV toolchain, not just the inference chips.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.