Nvidia Patents a 3D-Grounded Video Generation System for Precise Camera Control
Generating video with AI is easy — generating video where the camera can actually move through a consistent 3D world is the hard part. Nvidia's new patent tackles exactly that.
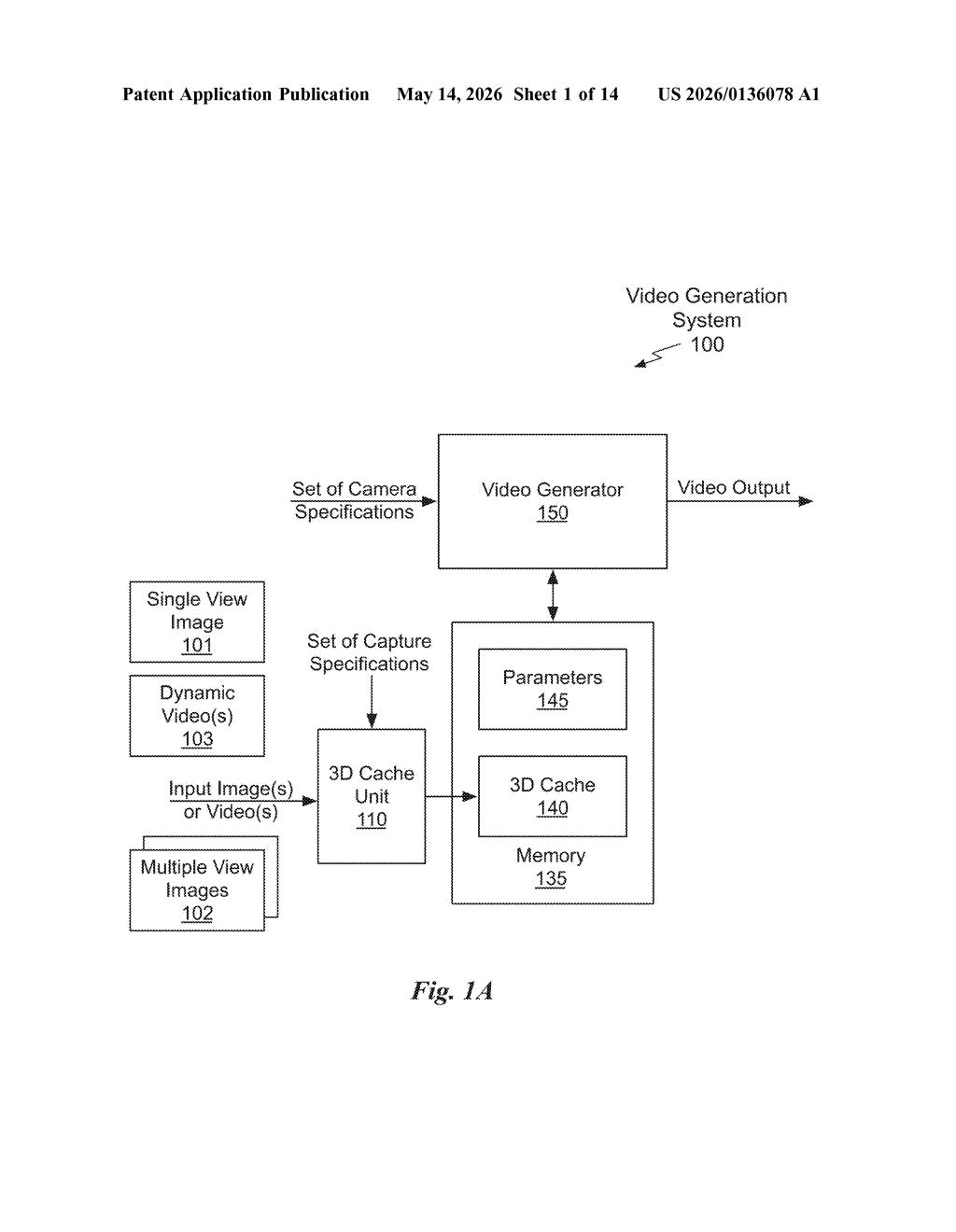
What Nvidia's 3D-grounded video generation actually does
Imagine you take a few photos of a room, and then ask an AI to generate a video that smoothly pans across it — without any weird floating objects, walls that flicker, or geometry that shifts as the camera moves. That's the problem this patent is trying to solve.
Nvidia's system first builds a 3D representation of your scene from one or more regular 2D images. Think of it like reconstructing a dollhouse from photographs. Once that internal 3D model — the "3D cache" — exists, the system can virtually position a camera anywhere inside it and render what that camera would see, frame by frame.
The clever bit is that this 3D render gets handed to a standard AI video diffusion model as a guide. Wherever the 3D render has gaps (spots the original photos never captured), the AI fills them in intelligently. The result is video that stays spatially consistent as the camera moves — something current text-to-video tools notoriously struggle with.
How Nvidia's 3D cache drives the diffusion video pipeline
The patent describes a pipeline with four main stages that work together to produce 3D-grounded video output.
- 3D cache construction: One or more input images (or a short video clip) of a scene are used to compute a 3D cache — a compact geometric representation of the scene. This is essentially a point cloud, neural radiance field, or similar structure that encodes where things are in three-dimensional space.
- Camera-aware rendering: The system takes a set of camera specifications — position, orientation, focal length, motion path — and renders the 3D cache from those viewpoints to produce a frame sequence. Simultaneously, a mask sequence is generated that flags every pixel in each frame that the original images never captured (i.e., regions outside the original camera's field of view).
- Latent encoding: Each rendered frame is passed through an encoder (the compression stage of a standard video diffusion architecture) to produce a latent frame sequence — a compressed, abstract representation the diffusion model can work with.
- Masked video diffusion: The latent frames and the mask sequence are fed into a video diffusion model (an AI that generates video by iteratively denoising). The masks tell the model exactly where it needs to invent plausible content rather than just refine what's already there.
This design means the AI's creative freedom is deliberately constrained to only the unknown regions — preserving geometric consistency in areas that are already grounded by real data.
What this means for AI video and virtual production
For AI video generation, spatial consistency has been the Achilles heel. Tools like Sora or Runway can produce stunning footage, but ask them to orbit a stationary object and the geometry often drifts or warps. Nvidia's approach borrows the discipline of traditional 3D rendering and uses it as a hard constraint on what the diffusion model is allowed to hallucinate — which is a fundamentally sounder architecture than hoping the model learns geometry from data alone.
For virtual production, game cinematics, and digital twins, this is directly relevant. If you can hand the system a few reference images of a real set or location, and then define a camera move, you get temporally stable video without a full 3D scan pipeline. That's a meaningful reduction in friction for content creators, and it maps neatly onto Nvidia's existing strengths in real-time 3D rendering, Omniverse, and its growing suite of generative media tools.
This is one of the more technically coherent AI video patents to come out of a major lab recently — it doesn't try to solve everything with a bigger model, it imposes geometric structure as a prior. The team includes serious researchers (Sanja Fidler, Jun Gao, Thomas Müller-Höhne) who have published foundational work in neural rendering, so this isn't a speculative filing from a corporate legal team; it reflects real research direction. Keep an eye on Nvidia's Cosmos and Omniverse pipelines for where this lands.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.