Nvidia Patents a Self-Checking Neural Network That Catches Its Own OCR Errors
What if an AI could catch its own reading mistakes — not by re-reading the document, but by noticing that its own notes about the document don't make grammatical sense? That's the core idea behind this Nvidia patent.
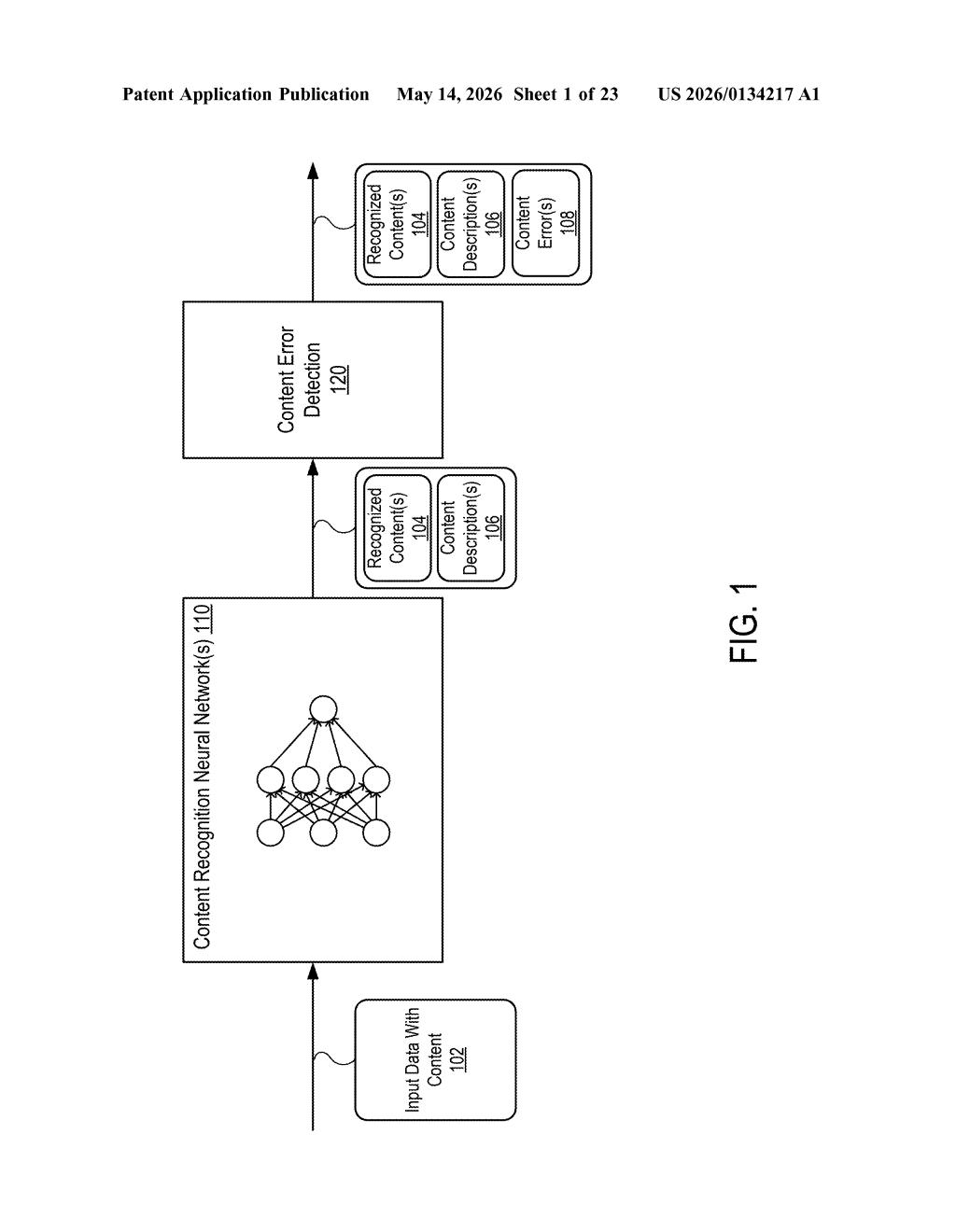
How Nvidia's document AI catches its own mistakes
Imagine handing a stack of scanned invoices to a document-reading AI. It transcribes the text — but sometimes it gets things wrong, misreading a number, garbling a date, or confusing one word for another. Normally you'd need a human to spot those errors, or a second AI pass.
Nvidia's approach is cleverer: when the AI reads a document, it doesn't just produce the transcribed text — it also generates a short descriptive label for each piece of content it found (something like "this is a dollar amount" or "this is a company name"). If that label has a syntax error — meaning its grammar or structure doesn't hold together — Nvidia's system flags the underlying content as likely wrong too.
Think of it like a spell-checker for the AI's own annotations. You get error detection essentially for free, without needing a separate verification model or a human reviewer for every document.
How label syntax flags bad transcription content
The system processes one or more document images through a neural network that produces document transcriptions. Each transcription has two layers: the actual document content (the transcribed text, numbers, or data) and descriptive information — structured labels that characterize what each piece of content is supposed to be.
The key insight is that errors in the underlying content recognition often manifest as malformed or syntactically broken labels. If the neural network misreads a field, its generated description of that field tends to be grammatically or structurally inconsistent — a kind of semantic tell. The system watches for these syntax errors in the descriptive layer as a proxy signal for content-level mistakes.
- Token-level evaluation: Content and label tokens are evaluated together, so errors can be pinpointed to specific bounding boxes or fields within a document.
- No ground truth needed: Error detection happens without comparing against a known-correct version — the AI's own metadata is the signal.
- Generalizable: The abstract references "object recognition inferences" broadly, suggesting the approach could extend beyond text documents to other visual recognition tasks.
The architecture essentially uses the model's self-generated annotations as a consistency check on its primary output — a lightweight form of internal audit.
What this means for AI-powered document processing
Document understanding AI — used in everything from enterprise data extraction to medical record digitization — is only as good as its error rate. Today, catching mistakes typically means either expensive human review or running a second verification model. Nvidia's approach bakes error detection into a single inference pass, which matters a lot at scale when you're processing millions of documents.
For Nvidia, this fits squarely into its push to make data-center AI workloads more reliable end-to-end — not just faster. If this technique ships in something like NeMo or a document-AI SDK, it could meaningfully reduce the cost of deploying OCR and document-intelligence pipelines in production. That's a real operational win for enterprise customers.
This is a genuinely smart idea — using the model's own generated metadata as a diagnostic signal is elegant and doesn't require extra compute or a separate verifier model. It won't make headlines, but it's the kind of practical reliability work that separates production-grade AI systems from demos.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.