Google Patents a Geometry-Free Neural Renderer That Skips 3D Reconstruction
Most 3D scene synthesis systems spend enormous effort building an explicit map of the world — depth, meshes, NeRFs — before they can render a new viewpoint. Google's new patent skips that step entirely, letting a transformer figure out the geometry implicitly from just a handful of photos.
What Google's geometry-free scene rendering actually does
Imagine you take three photos of a living room from different angles, and an AI instantly generates what that room would look like from a completely new angle you never photographed — without ever building a 3D model of the furniture. That's the core idea here.
Most existing systems need to first reconstruct the geometry of a scene (think depth maps, point clouds, or volumetric grids) before they can synthesize a new view. Google's approach trains a transformer to learn the 3D structure implicitly, encoding it as abstract numbers (latent representations) rather than explicit coordinates. The decoder then figures out what each pixel should look like by asking: 'if a ray of light passed through this pixel from a new camera angle, what would it hit?'
The result is a system that handles parallax (things shifting differently based on distance), occlusions (objects hiding behind other objects), and even object identity — all without ever explicitly computing geometry.
How the transformer decodes rays into pixel colors
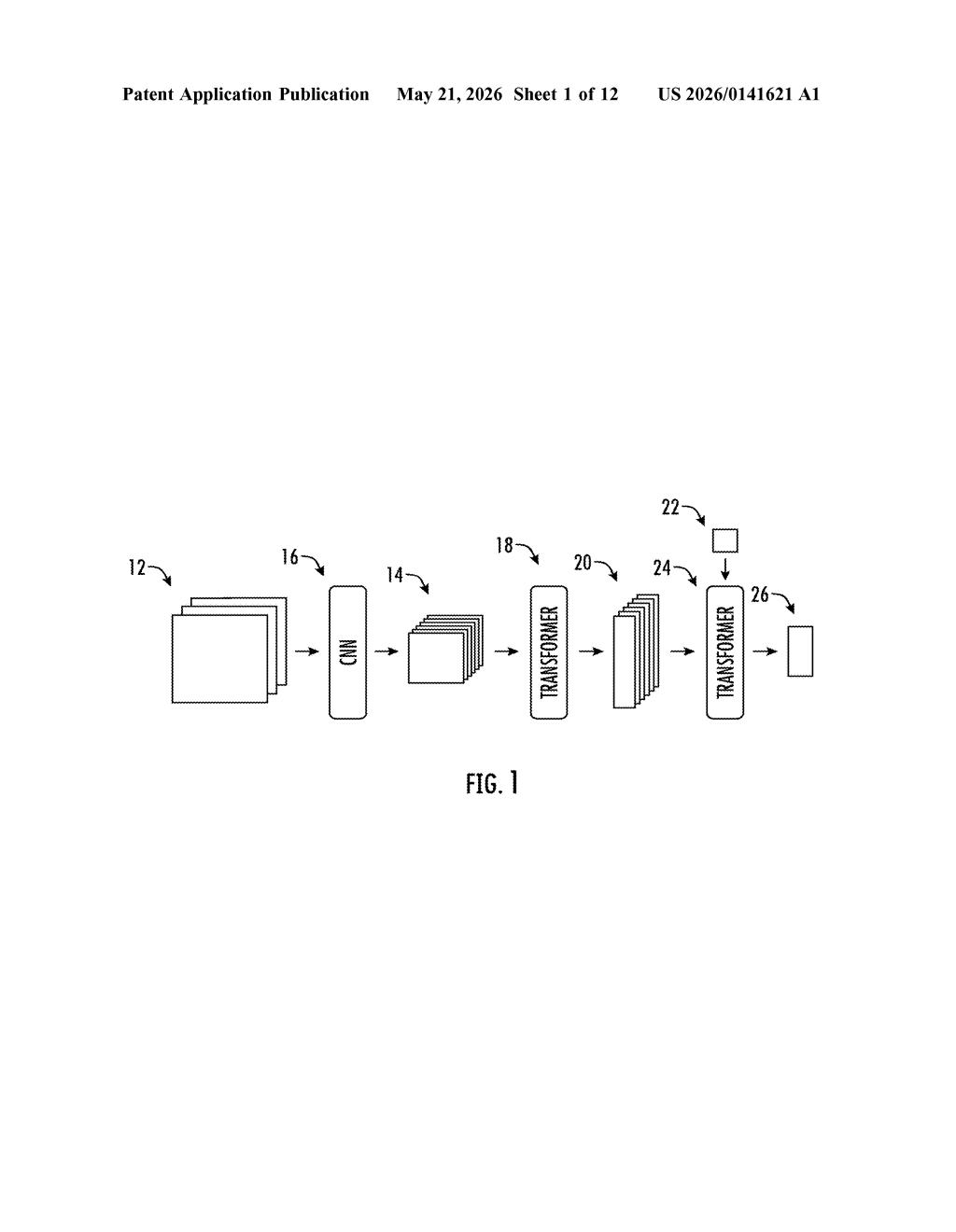
The system has two main components: an encoder transformer and a decoder transformer.
The encoder takes one or more RGB images of a scene — with or without camera pose information — and produces a set of latent representation encodings. These are compact, abstract vectors that capture what the scene looks like, how objects relate spatially, and implicitly encode 3D structure. Crucially, these encodings are object-centric, meaning different slots in the latent space tend to correspond to different objects in the scene.
The decoder then synthesizes novel views in a single forward pass using three sub-components:
- Transformer submodel: For each pixel in the target image, it casts a query ray (a line from the new camera position through that pixel into the scene) and cross-attends it against all the latent encodings to produce a feature embedding.
- Weighting submodel: Takes that embedding and computes a weighted average over the latent encodings — essentially asking 'which parts of the scene are relevant to this ray?'
- Rendering submodel: Combines the ray direction with the weighted latent average to predict the final RGB color for that pixel.
Because transformers can learn flexible attention patterns, the model figures out parallax, depth ordering, and occlusion handling entirely from training data — no explicit geometry pipeline required.
What this means for AR, robotics, and 3D content creation
The practical upside is efficiency and flexibility. Traditional novel-view synthesis methods like NeRF (Neural Radiance Fields) require per-scene optimization that can take minutes to hours. A generalizable transformer-based system like this, once trained, can render new scenes in a single forward pass — a potentially massive speedup for applications like AR content creation, robotics scene understanding, and video game asset generation.
The object-centric design is also notable. Because the latent space carves the scene into objects, the system could — in principle — support tasks like 'remove that chair and show me the room' or 'move that object and re-render.' For Google, this fits squarely into ongoing work on generalizable 3D perception for products like Google Maps immersive view, AR glasses, and multimodal AI systems.
This is a legitimately interesting research-grade patent from a team that includes well-known ML researchers. The geometry-free angle is a real architectural bet — it trades interpretability and explicit 3D control for speed and generalization. Whether this architecture proves more practical than NeRF variants or Gaussian Splatting in production settings is an open question, but the direction is worth watching closely.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.