Qualcomm Patents an On-Device System That Trains TTS on Your Own Voice
What if your phone's text-to-speech gradually started sounding more like you — without ever uploading your voice to a server? That's the core idea behind this Qualcomm patent.
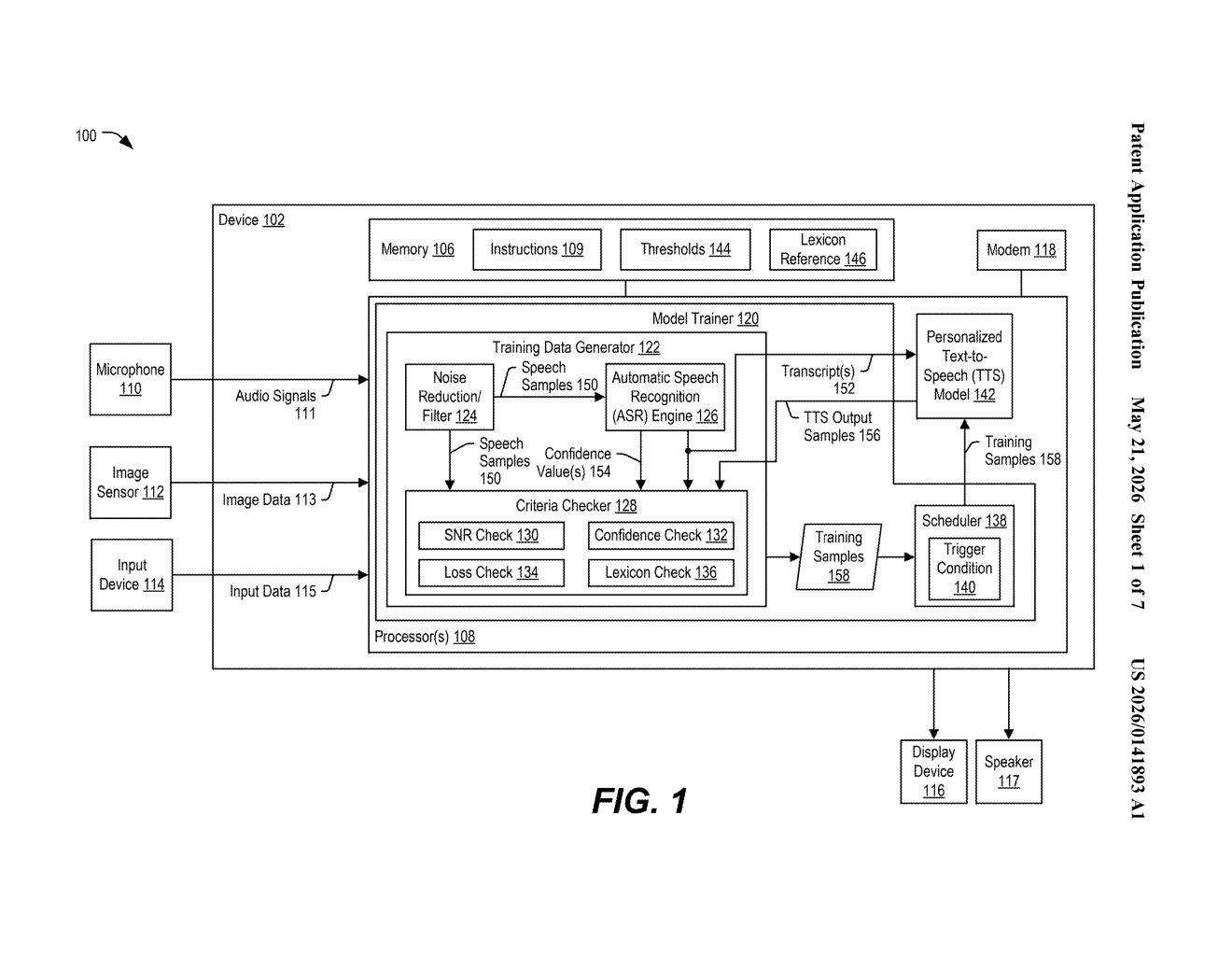
How Qualcomm's TTS learns your voice on your device
Imagine your phone reads out a message and the voice sounds robotic and generic. Now imagine it slowly adapts to match your voice over time, just by listening to you talk normally throughout the day. That's what Qualcomm is describing here.
The system quietly collects snippets of your speech while you're using your device — not in a creepy always-on way, but by tapping audio that's already flowing through normal interactions. It then runs those samples through a quality filter to make sure they're actually worth learning from before using them to fine-tune a text-to-speech (TTS) model stored entirely on your device.
The key word is on-device. Your voice data never has to leave your phone. The model trains locally, which is both a privacy win and a practical one — no cloud dependency means it works even offline.
How the sample quality pipeline filters your speech
The patent describes a pipeline that sits on the device and continuously evaluates incoming audio for training worthiness before touching the TTS model. It's not grabbing every word you say — it's highly selective.
Here's how the filtering sequence works:
- ASR confidence check: The device first runs an Automatic Speech Recognition (ASR) engine — basically a speech-to-text transcription system — on the audio sample. If the transcription confidence score is too low (meaning the system isn't sure what you said), the sample gets dropped. Garbage in, garbage out.
- TTS loss check: The system then generates a TTS output from that transcription and measures the loss value — a number representing how far the synthesized speech is from matching your real voice. High loss means the model still has a lot to learn from this sample, making it useful for training.
- Lexicon diversity check: The system also checks whether the transcription adds new vocabulary variety (words or phoneme patterns not well-represented in existing samples). This prevents the model from over-training on a narrow slice of your speech habits.
Samples that pass these checks get queued by a Scheduler, which manages when and how training actually runs — presumably during idle periods to avoid impacting battery or performance.
What this means for on-device voice assistants
On-device AI personalization is a real battleground right now. Most TTS personalization today either requires you to record a dedicated voice sample session (cumbersome) or relies on cloud-based processing (privacy trade-off). Qualcomm's approach tries to thread that needle: passive collection, strict quality filtering, and fully local training. For chipmakers like Qualcomm, this is also a direct argument for why you need a powerful, efficient on-device AI processor — the Snapdragon NPU family being the obvious beneficiary.
For you as a user, the practical upside is a voice assistant or screen reader that sounds progressively more natural and personalized over time, without requiring any deliberate setup. The filtering pipeline is the real engineering story — making sure low-quality audio doesn't corrupt the model is harder than it sounds.
This is genuinely thoughtful work on a problem that matters: making TTS personalization private-by-default and low-friction. The three-stage quality filter — ASR confidence, TTS loss, and lexicon diversity — is an elegant design that prevents the obvious failure mode of a model that learns your bad microphone days as much as your good ones. It's not flashy, but this is the kind of infrastructure-level patent that shows up in real products.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.