Google Patents a Teacher-Student Framework for Training Smaller AI Models
This Google patent, co-invented by Geoffrey Hinton and Oriol Vinyals, covers one of the most influential ideas in modern AI: knowledge distillation — training a compact model to behave like a much larger one. The catch? This technique has been public since at least 2015.
How Google's 'student' AI learns from a bigger 'teacher' model
Imagine you have a brilliant, slow professor who can ace any exam, and a quick student who needs to graduate in half the time. Instead of having the student memorize a textbook, you have them shadow the professor — watching how confident the professor is about every possible answer, not just which answer they pick. The student learns not just the right answer, but the professor's entire reasoning pattern.
That's exactly what Google is describing here. You train a big, expensive AI model first (the 'teacher'), then train a smaller, faster model (the 'student') to reproduce the teacher's probability distributions — not just its final answers. Those distributions carry richer information, like how close a wrong answer was to being right.
The end result is a smaller model that punches above its weight — nearly as accurate as the giant one, but cheap enough to run on real products at scale.
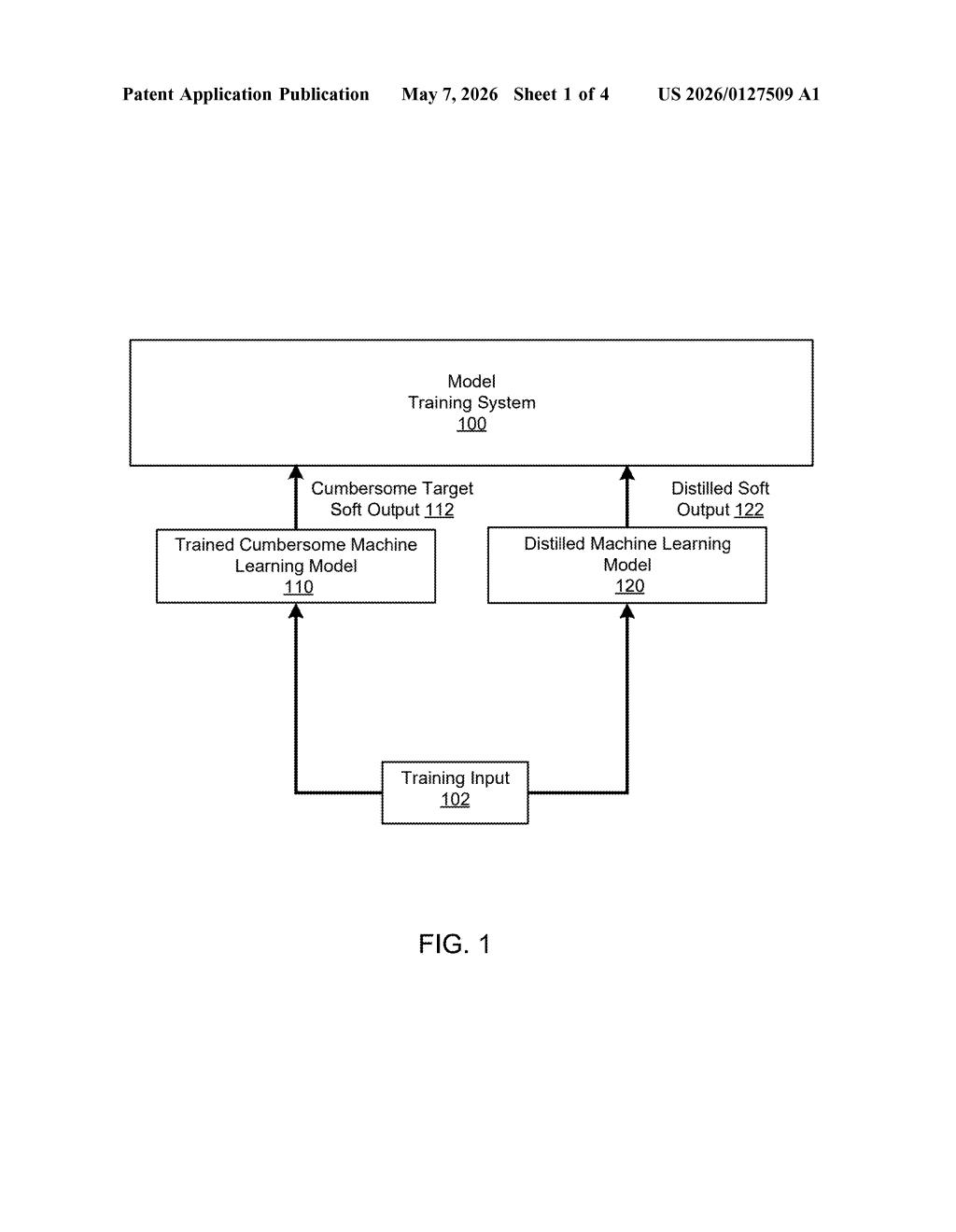
How the student model matches the teacher's soft output scores
The patent describes a two-phase training process. First, a large teacher model (called a 'cumbersome model' in the original abstract) is trained normally — it learns to classify inputs across many categories. Then a smaller student model is trained using the teacher's outputs as targets.
The key insight is in what kind of output the student learns from. Rather than hard labels ('this is a cat'), the student learns from soft outputs — the full probability distribution the teacher produces across all classes ('67% cat, 20% dog, 13% fox'). These soft outputs contain significantly more information than a binary correct/incorrect signal.
The student's training objective includes a term that measures the discrepancy between its own output distribution and the teacher's output distribution — essentially a divergence loss. Minimizing this discrepancy forces the student to replicate the teacher's internal knowledge, not just its top-1 prediction.
The claim also mentions that the teacher is drawn from a plurality of teacher models, suggesting ensemble distillation — a setup where multiple specialized teachers collectively supervise a single student.
What this means for running AI cheaply at Google's scale
Knowledge distillation is how companies like Google compress massive models — think large language models or image classifiers — into versions that can run on phones, edge devices, or serve millions of requests without burning a data center. If you've ever used an on-device Google feature that feels smarter than it has any right to be given your phone's hardware, distillation is likely part of why.
The strategic angle here is cost and latency: inference at scale is expensive, and distilled models cut that bill dramatically. For Google, which runs AI across Search, Photos, Assistant, and Gemini, even modest efficiency gains at this layer translate into enormous savings — and faster responses for you.
Let's be direct: this patent covers knowledge distillation, a concept Hinton and collaborators published openly in 2015 and that has since become a cornerstone technique across the entire AI industry. Filing this in late 2025 is a defensive IP move, not a new invention. The inventor list — Hinton, Vinyals, Dean — is a who's-who of Google Brain royalty, but the underlying idea is a decade old and widely practiced. This is legal strategy, not a technical breakthrough.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.