Microsoft Patents a Rare-Term Index to Surface Niche Web Content
Most search indexes are optimized for popular content — but that leaves a long tail of niche, specialized pages effectively invisible. Microsoft's new patent targets exactly that blind spot by building a dedicated index around rare and infrequent terms.
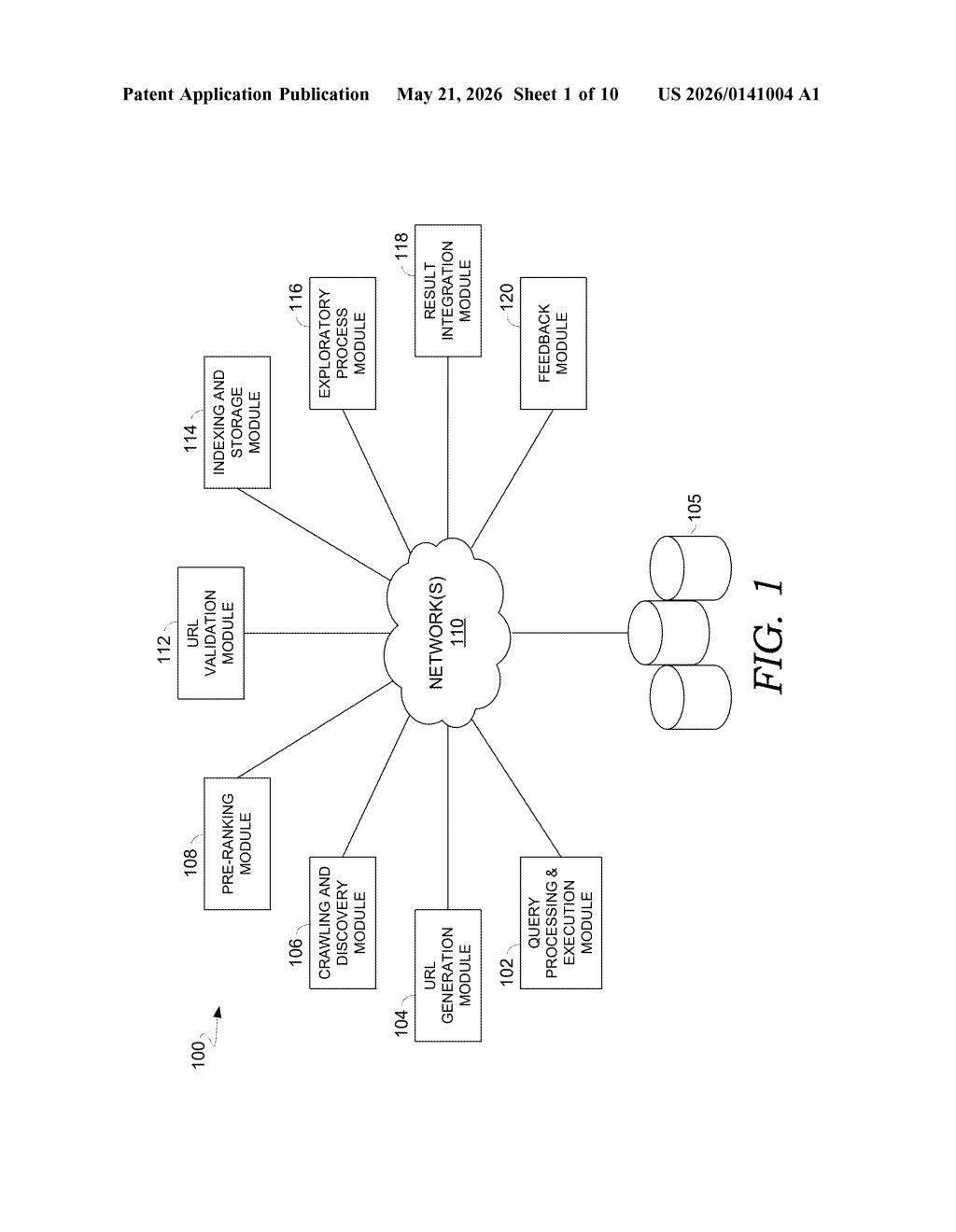
What Microsoft's rare-term search index actually does
Imagine you're searching for a very specific technical term, an obscure place name, or a piece of jargon that only a small community uses. Most search engines are tuned to handle popular queries well, so your niche search either returns nothing useful or gets buried under generic results. That's the gap this patent is trying to close.
Microsoft's approach is to crawl the web and specifically pull out rare or infrequent terms from three places: the URL of a page (like the words in a web address), the anchor text (the clickable link text on other pages pointing to it), and the page title. Those rare terms get stored in a dedicated index that maps them directly to the relevant web addresses.
When you run a search, the system can consult this "bottomless index" alongside a regular index for common terms, blending niche and mainstream results into a single balanced output. The goal is that your oddly specific query gets a fighting chance right alongside everyday searches.
How the crawler extracts and maps infrequent terms
The patent describes a two-track indexing architecture. A standard index handles common terms the way search engines always have. A second, separate index — called a "bottomless index" in the patent's own diagrams — is purpose-built for infrequent or rare terms.
During web crawling, the system extracts rare terms from three specific sources:
- The URL itself — words embedded in the web address (e.g., /obscure-widget-model-x44)
- Anchor text — the visible, clickable text on other pages that link to the target page
- Page title — the main heading or label of the page or the linking page
The rarity of a term is the key trigger: only infrequent terms get routed into the dedicated rare-term index. Each entry maps a representation of the rare term (likely a normalized or encoded form) to a representation of the URL. This design keeps the rare-term index lean and fast to query without polluting it with high-frequency noise.
At query time, an orchestration layer — the patent references an LLM-driven real-time indexing component alongside classic indexing — pulls from both indexes and hands results to a ranking component that merges and orders them. The "on-demand crawl and indexing" path in the diagrams also suggests the system can fetch and index new rare-term content in near-real-time when a query demands it.
What this means for Bing's long-tail search coverage
For Bing, this is about closing the gap with niche and long-tail queries where Google has historically dominated through sheer index depth. If you're searching for something highly specific — a rare medical term, an obscure product code, a regional dialect word — a search engine that explicitly indexes rare terms has a structural advantage over one that doesn't.
The patent also hints at an LLM-driven indexing layer, which is the more forward-looking angle. Combining a dedicated rare-term index with a large language model that can interpret and generate index entries on demand could let Bing handle queries for concepts that haven't even been explicitly crawled yet. That's a meaningful capability gap to close, and it signals Microsoft is thinking about search indexes as something more dynamic than a static crawl-and-store pipeline.
This is quiet but genuinely useful infrastructure work. Building a dedicated index for rare terms sounds mundane, but it directly addresses one of the most persistent frustrations with search — the invisibility of niche content. The LLM-driven real-time indexing component tucked into the patent diagrams is the actually interesting part, and it's worth watching whether this shows up as a measurable Bing improvement for specialized professional queries.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.