Nvidia Patents a System for Writing Captions About Specific Parts of an Image
Describing a whole photo is one thing — but describing exactly what's happening inside a specific bounding box, while still 'knowing' the broader scene, is a genuinely hard problem for vision AI. Nvidia's new patent tackles it with a two-pass captioning pipeline that fuses local and global context into a single, rich description.
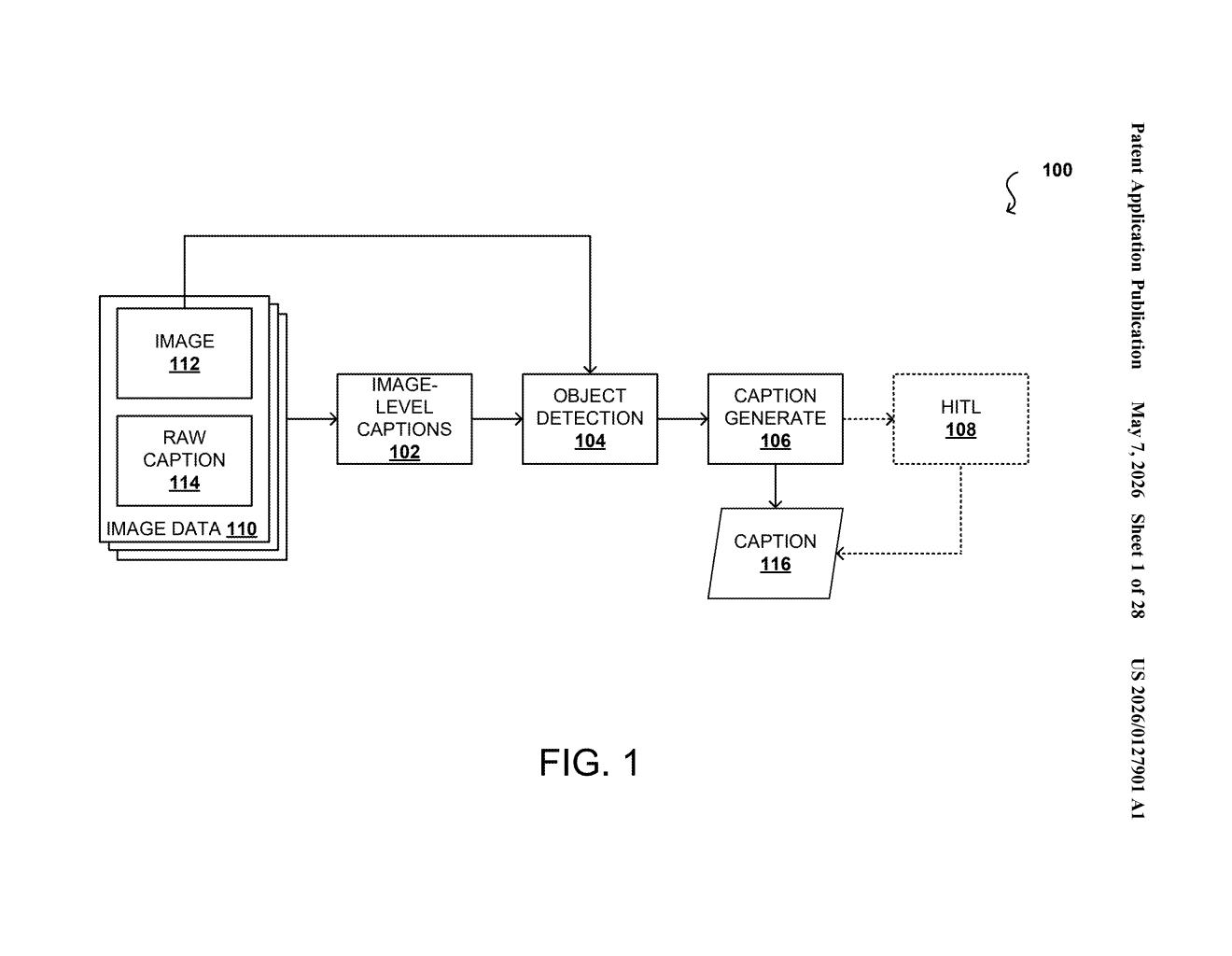
How Nvidia's region captioning uses the full scene to describe each object
Imagine an AI looking at a photo of a sailboat on Lake Geneva with the Alps in the background. If you ask it to describe just the sailboat, it might say something generic like "a boat on water." But a good description would mention that it's a schooner, that the mountains are behind it, and that it's a sunny autumn day — details that require understanding the whole image, not just the cropped region.
That's the problem Nvidia's new patent is designed to solve. It describes a system that first generates a full, detailed caption for an entire image. Then, when it zooms into individual objects or regions, it uses that big-picture understanding to write richer, more contextually accurate descriptions for each one.
The result is a merged caption per region that draws on both what's happening locally (inside the bounding box) and globally (across the whole scene). This kind of output is especially valuable for building AI training datasets, where detailed, accurate region-level labels make the difference between a model that truly understands images and one that just pattern-matches.
How the merged-caption pipeline combines local and global signals
The system Nvidia describes works in several layered steps:
- Step 1 — Global captioning: A raw or seed caption is used alongside the input image to generate a detailed, scene-level description. Think of this as the AI writing a paragraph about the whole photo.
- Step 2 — Object detection: The system generates an object list and draws bounding boxes (rectangular regions that isolate individual objects) around things it identifies in the image.
- Step 3 — Local captioning: For each bounding box, a machine learning model generates a "first selected caption" — a description focused on just that region.
- Step 4 — Merging: A second pass generates a "second selected caption" that re-examines the bounding box through the lens of the global caption. These two local captions are then merged with the identified object name into a single, context-aware description.
The key insight is the merge step. Instead of treating each region in isolation, the model explicitly injects global scene context — like lighting, setting, or overall composition — back into the region-level caption. This prevents a captioning model from saying "a tall vertical object" when it should say "the mainmast of a schooner on Lake Geneva."
The patent specifically covers a processor-implemented system, suggesting this is designed to run at scale, likely as part of a data-generation or annotation pipeline rather than a real-time end-user feature.
What this means for AI training data and multimodal models
Detailed, region-level image captions are the lifeblood of training multimodal AI models — the kind that understand both images and text, like vision-language models (VLMs) and image-generation systems. If your training data only has coarse labels, your model learns coarse reasoning. Nvidia, which sells the GPUs that power most AI training workloads, has obvious strategic interest in improving the quality of AI training pipelines.
For you as someone who uses AI image tools, better region captioning could eventually translate into AI that understands your photos more accurately — whether that's a search engine that finds "the red umbrella in the background" or an editing assistant that knows exactly which object you're asking it to modify.
This is foundational data-pipeline work, not a flashy product feature — but that's precisely why it matters. The quality of AI training data is one of the most underappreciated bottlenecks in vision AI, and Nvidia is clearly investing in solving it at the infrastructure level. If this system feeds into their AI model training or their enterprise data annotation tools, the downstream impact could be significant even if the patent itself never makes a headline.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.