Nvidia Patents a Streaming AI System That Transcribes and Reasons Over Live Audio in Real Time
Most AI voice systems wait until you stop talking before they start thinking. Nvidia's new patent describes a system that feeds live audio into a language model on the fly — processing each chunk of speech as it arrives and generating text output continuously, without waiting for a pause.
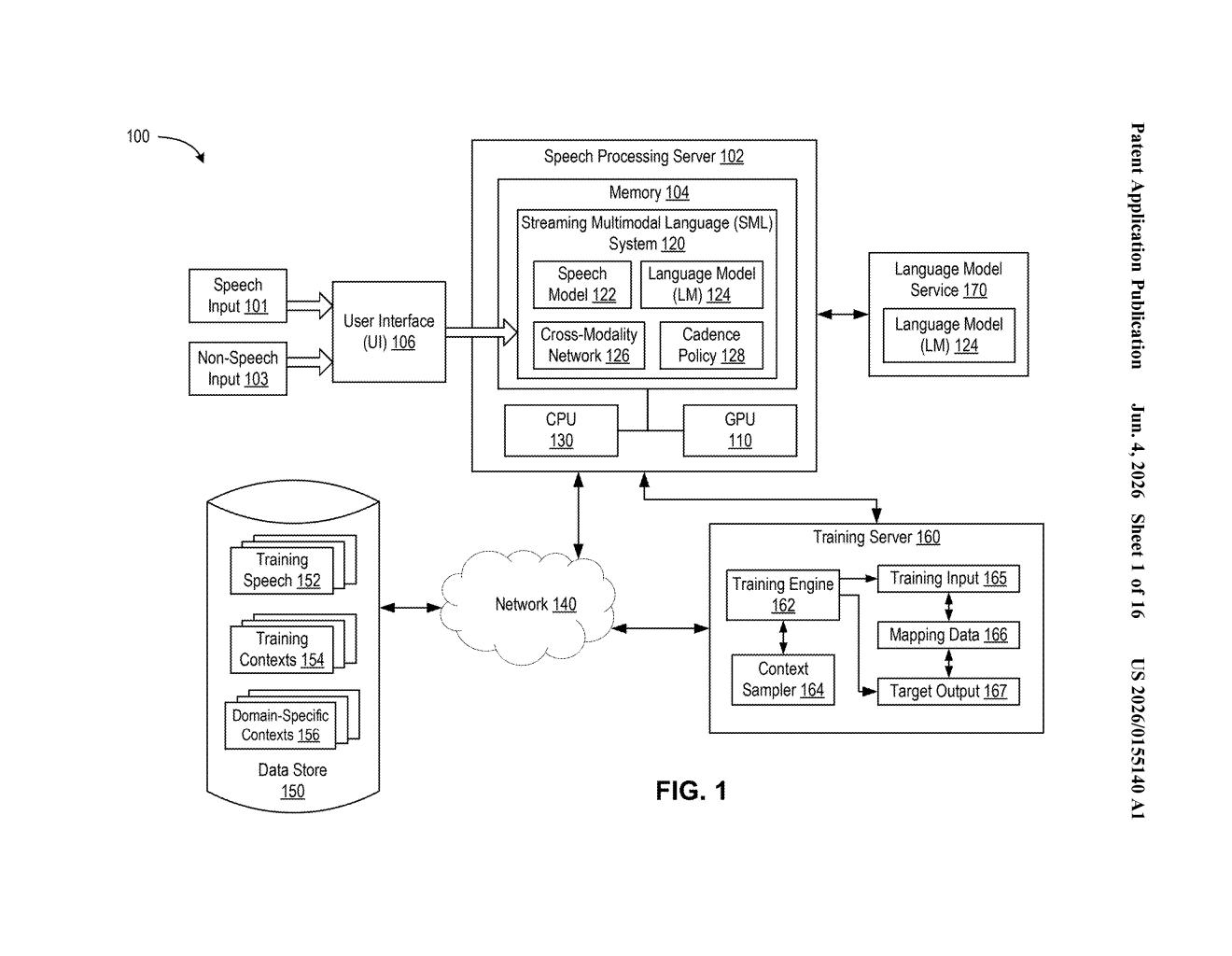
How Nvidia's live audio-to-LLM pipeline actually works
Imagine you're using a voice assistant and it starts responding while you're still speaking — not because it guessed what you'd say, but because it's genuinely processing your words in real time, chunk by chunk. That's the core idea behind this Nvidia patent.
The system listens to incoming audio in small time slices. After each slice, it updates its understanding of what you've said, combines that with any text context already in play, and asks a language model to predict the next piece of the output. The result streams out continuously — like a live subtitle feed that also reasons about what it's hearing.
This is different from the typical approach where a voice assistant records your full sentence, transcribes it, then sends it to an AI for processing. Nvidia's approach collapses those steps into a single continuous loop, which could make voice AI feel dramatically more responsive.
How the cross-modality network bridges audio and text each iteration
The patent describes a streaming multimodal language system — an AI pipeline designed to process incoming audio and generate text output simultaneously, without waiting for the audio stream to end.
At each time interval (think: a fraction of a second), the system runs through a fixed set of steps:
- Audio embedding update: New audio from that time slice is encoded into a vector representation (a numerical snapshot of the sound) and added to an ongoing buffer of audio embeddings.
- Cross-modality network processing: A dedicated bridge network takes both the accumulated audio embeddings and a set of text embeddings (representing any text context or prompt) and computes cross-attention states — essentially, a weighted blend that lets the text side of the model focus on the most relevant parts of the audio.
- LLM prompting: The cross-attention states are converted into output embeddings and fed as a prompt to a language model (LM), which then predicts one text token for that time interval.
- Token accumulation: Each predicted token is added to the output stream, building the final transcription or response incrementally.
The key architectural insight is the cross-modality network sitting between the audio encoder and the language model. Rather than concatenating raw audio features directly into the LLM's context (which is slow and expensive), this bridge compresses and aligns the two modalities at each step, keeping the LLM prompt lightweight while still giving it fresh audio information every iteration.
What this means for real-time voice AI and conversational agents
The bottleneck in today's voice AI pipelines is usually the gap between hearing and understanding. Current systems — even fast ones like Whisper-based setups — batch audio into chunks, transcribe, then pass to an LLM. Each handoff adds latency. Nvidia's architecture fuses those stages into one iterative loop, which could significantly reduce the time between someone speaking and an AI responding.
For Nvidia, this matters strategically. The company's ACE (Avatar Cloud Engine) platform and its growing push into conversational AI agents for gaming, robotics, and enterprise applications all depend on low-latency voice interaction. A patent like this suggests Nvidia is building the foundational model architecture — not just the GPU muscle — to make real-time voice AI a core part of its stack.
This is solid, non-trivial AI systems work. The cross-modality network design — as a lightweight, iteration-level bridge between an audio encoder and an LLM — is a genuinely interesting architectural choice that addresses a real latency problem. It's not flashy from the outside, but it's exactly the kind of infrastructure patent that ends up embedded in production systems quietly powering products you use every day.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.