Nvidia Patents a Two-Stage Speech Transcription System That Handles Multiple Languages at Once
Many real conversations don't stay in one language — people switch mid-sentence, mid-meeting, or mid-call. Nvidia's new patent describes a speech recognition system built to handle exactly that, using a two-step process that first transcribes everything and then polishes each language separately.
How Nvidia's mixed-language transcription system works
Imagine you're in a business meeting where attendees drift between English and Spanish. A standard voice-to-text tool struggles — it's usually trained for one language, so switching causes errors, missing words, or garbled output.
Nvidia's patent describes a system designed to handle this naturally. First, a general-purpose speech model listens to the audio and produces a rough transcript, while also tagging each word or phrase with the language it was spoken in. Think of it like a first-pass note-taker who also labels every sentence with a flag: English, French, Hindi, and so on.
Then, a second round of refinement kicks in. Instead of one generic model trying to clean up everything, the system routes each tagged section to a dedicated language-specific AI model — one that was trained only on that language and knows its grammar, vocabulary, and quirks inside out. The result is a cleaner, more accurate transcript than a single multilingual model could produce alone.
How the STT model tags languages before the cleanup pass
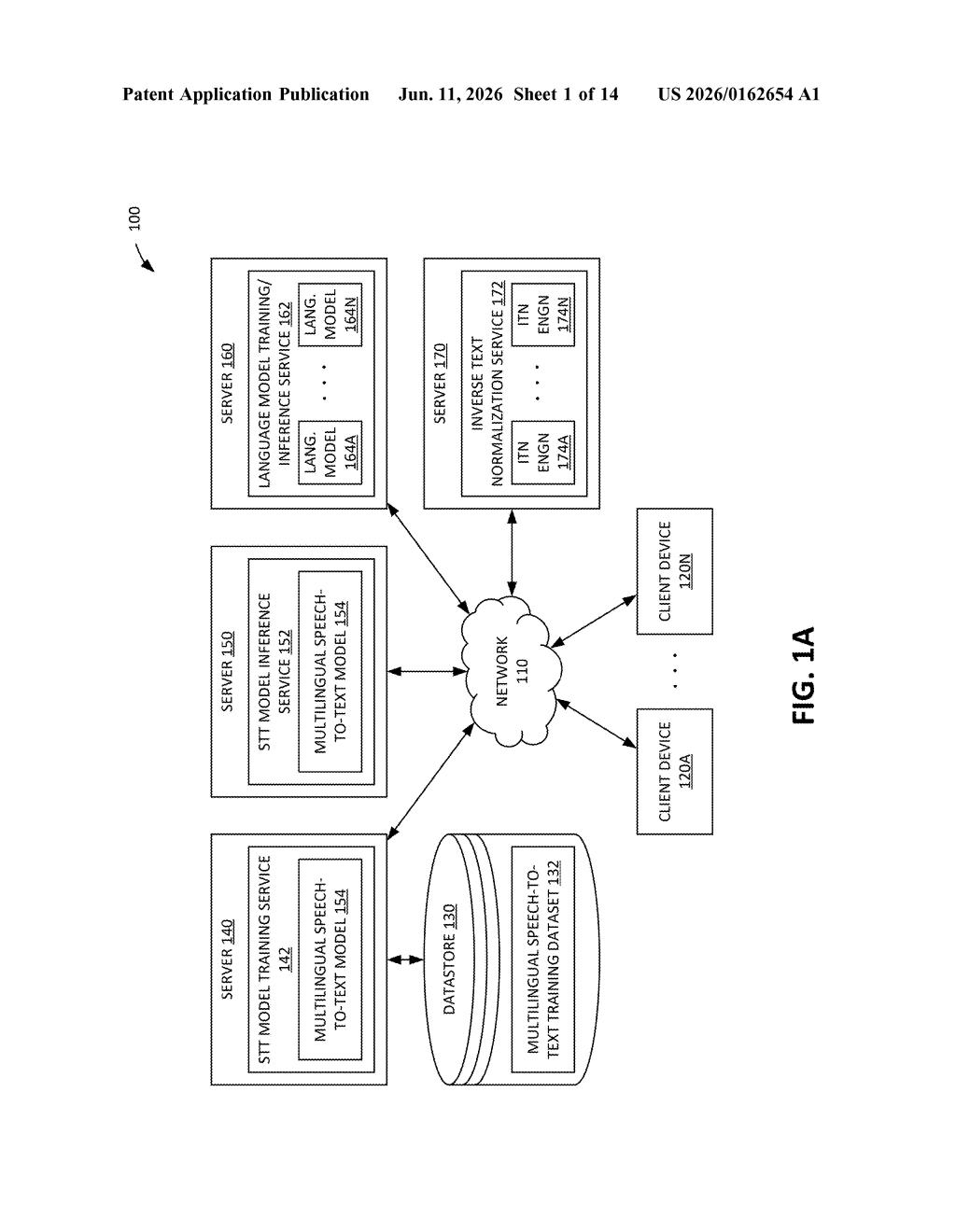
The system is built around two cooperating components inside a broader Automatic Speech Recognition (ASR) pipeline.
The first is a multilingual speech-to-text (STT) model — a single AI model that can listen to audio containing multiple languages and produce both a rough transcript and a set of language indicators. These indicators are attached to specific grammatical units (words, phrases, or clauses), essentially telling the system which language each chunk of the transcript belongs to.
The second step uses those language tags to pick from a library of monolingual language models (LMs) — smaller, specialized AI models each trained on a single language. Rather than feeding the entire transcript into one model, the system routes a relevant subset of the transcript to the matching monolingual LM for refinement. That model corrects errors, fills in gaps, and improves phrasing using deep knowledge of just that one language.
Key design choices include:
- Language detection happens at the grammatical unit level, not just per sentence or per speaker turn — enabling fine-grained code-switching support
- Refinement uses only the relevant subset of the transcript as input, keeping each specialist model focused
- The modular LM library means new languages can be added without retraining the whole system
What this means for multilingual voice applications
For developers building voice assistants, transcription services, or call-center analytics tools, getting multilingual audio right is a persistent headache. A single large model that handles all languages is a reasonable first step, but it tends to be mediocre at each one. Nvidia's approach — rough pass first, then language-specialist cleanup — is a practical way to get closer to native-level accuracy without an exponentially larger model.
For end users, this could translate to more accurate transcripts in multinational meetings, better voice assistants in bilingual households, or more reliable real-time captions in environments where language-switching is the norm rather than the exception. The architecture also hints at an industrial or enterprise use case, where Nvidia's GPU infrastructure would run the pipeline at scale.
This is solid, pragmatic engineering — not a flashy AI demo, but the kind of unglamorous plumbing that makes speech recognition actually useful in real-world multilingual contexts. The two-stage architecture (detect-then-refine with specialists) is a sensible answer to a real problem, and Nvidia is well-positioned to deploy it given its dominance in inference hardware. Worth watching, especially if Nvidia is building this into an ASR cloud service or embedding it in meeting-transcription tools.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.