OpenAI Patents a Way to Make Its AI Actually Think Before Refusing You
Most AI guardrails are more like a lookup table than a conscience — the model pattern-matches your request against a list of banned topics and blocks it. OpenAI is filing a patent for something different: an AI that actually reasons through its own rules before deciding what to say.
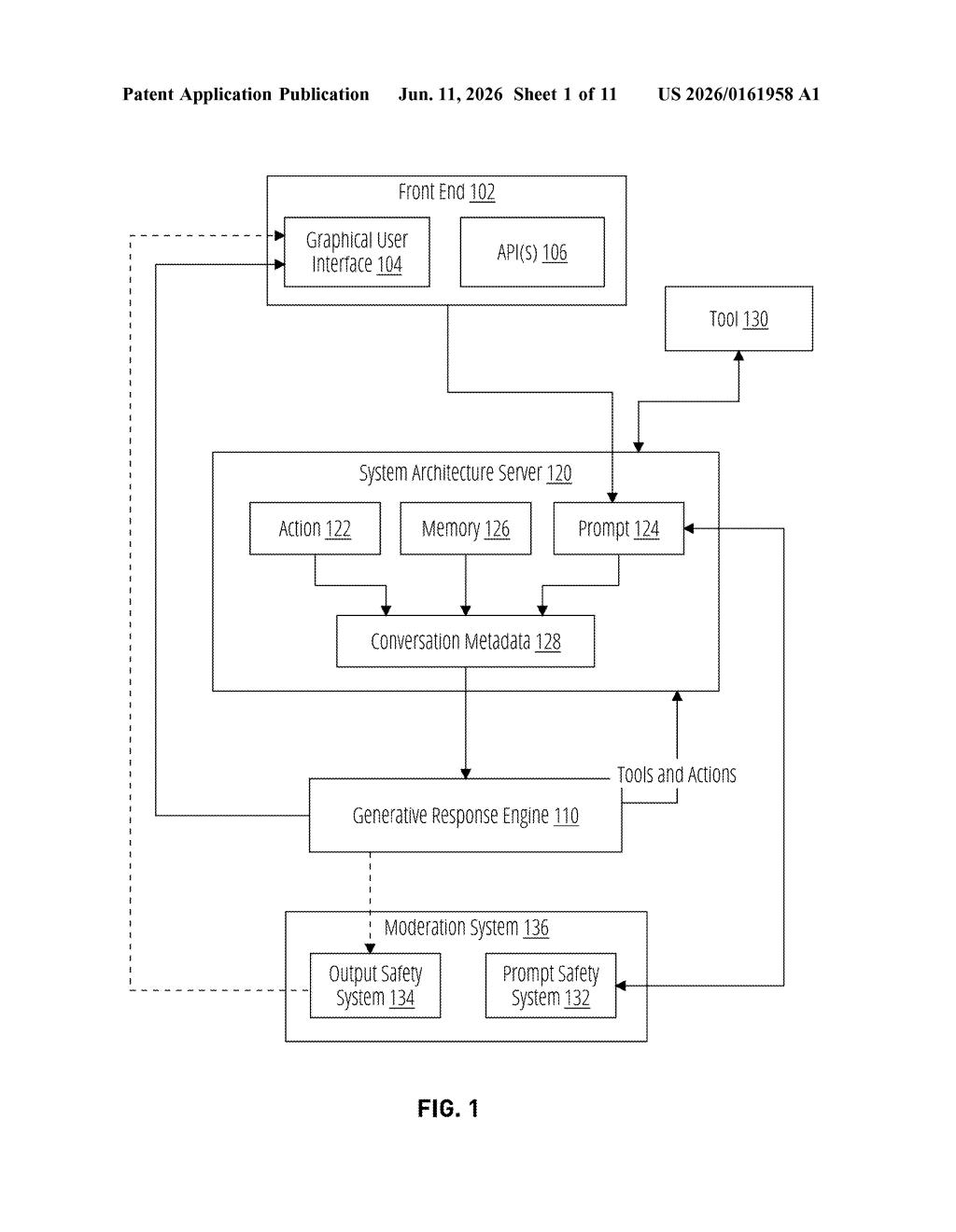
What OpenAI's policy-reasoning AI actually does
Imagine a customer service rep who, instead of following a printed script of dos and don'ts, has actually internalized the reasoning behind the company's policies. They can handle edge cases, gray areas, and unusual requests — because they understand why the rules exist, not just what they say. That's what OpenAI is trying to build here.
This patent describes a training method where the AI learns to reason step-by-step through a policy before it decides how to respond to you. It's given thousands of examples showing the full thought process — the question, the internal deliberation about applicable rules, and the final answer. Over time, the model internalizes that deliberative habit.
The result is a model that, when you ask it something borderline, doesn't just reflexively block you or blindly comply. It works through the relevant policy context the way a thoughtful person would — and then either responds or explains why it won't.
How the model reasons through rules before responding
The patent describes a post-training process — meaning training that happens after the base AI model already exists — designed to teach a reasoning-capable language model to consult a policy framework before generating any response.
The key ingredient is a training dataset made up of three-part examples called (prompt, chain-of-thought, response) tuples. The chain-of-thought piece is the novel part: it's a written-out reasoning trace that explicitly works through the relevant policy before landing on a response. The model is trained via supervised fine-tuning (a technique where the AI learns to reproduce expert-labeled examples) on thousands of these annotated triplets.
At inference time — when you're actually talking to the model — it applies that same deliberative habit:
- Receive a prompt from the user
- Reason internally about the prompt within the context of applicable policy
- Decide whether to respond, how to respond, or whether to decline and cite the specific policy reason
Critically, the model isn't just retrieving a blocked-keyword list. It's performing a contextual judgment — which means the same surface-level request could get different responses depending on the surrounding context, who's asking, and what purpose the deployment policy specifies.
What this means for AI safety and content moderation
Current AI safety approaches often feel blunt: the model either blocks something it shouldn't, or lets through something it should catch. That's partly because rule-following and reasoning are handled separately. This patent tries to close that gap by baking policy reasoning directly into how the model thinks — not bolting it on afterward as a filter.
For you as a user, this could mean fewer frustrating false-positive refusals on legitimate requests. For OpenAI's enterprise customers, it could mean deployable models that reliably follow their specific policies — not just OpenAI's defaults — without needing a separate moderation layer on top. That's a meaningful commercial differentiator in a market where every AI vendor is competing on trustworthiness.
This is one of the more substantive AI alignment patents to come through in a while — it addresses a real, widely-complained-about failure mode of current models. Whether it actually works at scale is a separate question the patent can't answer, but the approach of training on explicit policy-reasoning traces rather than outcome labels is a credible direction that serious researchers are actively pursuing. Worth watching.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.