Microsoft's New Patent Trains Voice Assistants to Recognize Every Way You Say the Same Thing
Voice assistants often fail when you phrase a command slightly differently than they expect. Microsoft's new patent uses a large language model to automatically generate dozens of ways a user might say the same thing — so the assistant recognizes all of them.
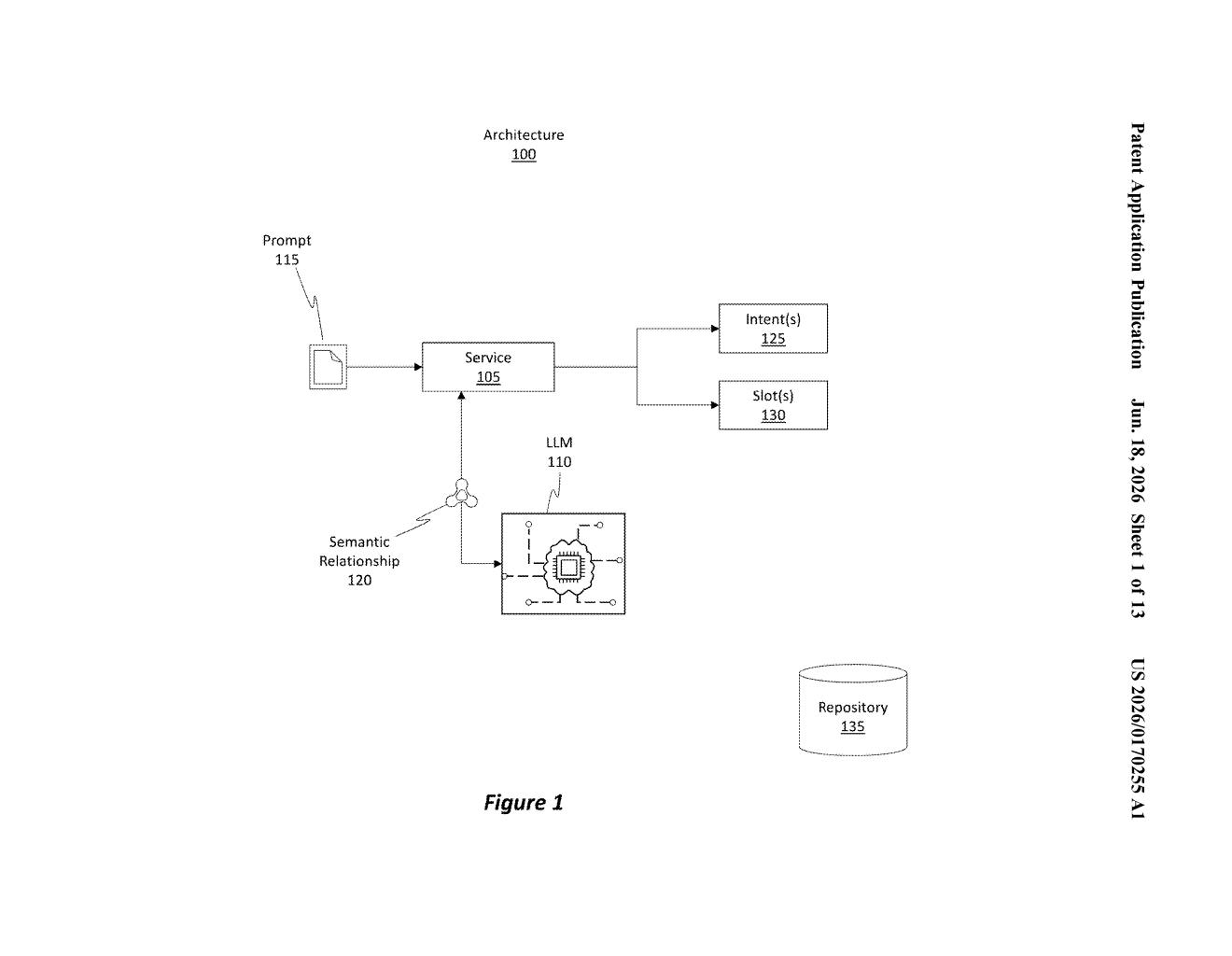
How Microsoft's phrase-expansion idea would work for you
Imagine telling your computer to "turn off the lights" and it works fine — but when you say "kill the lights" or "lights out," nothing happens. That's a real frustration with today's voice assistants. They're often trained on a narrow set of exact phrases, and anything outside that list falls flat.
Microsoft's patent describes a fix: feed a handful of example phrases for a command into an AI language model, and let the model brainstorm every other way someone might say the same thing. All those variations then get saved alongside the originals, so the assistant can respond to any of them.
The result is a voice system that doesn't force you to memorize the "right" way to ask for something. Instead, the AI does the work of anticipating how different people naturally talk — before anyone even uses the product.
How the LLM generates and stores phrase variations
The patent describes a pipeline with three main steps.
- Seed data input: A developer provides a small set of phrases (called "utterances") that all map to the same command. For example, "open a new document," "start a new file," and "create a blank page" might all trigger the same action.
- LLM augmentation: A pre-trained large language model — one trained on broad language data, not a custom-built tool — takes those seed phrases and generates additional variations that are semantically related (meaning: same intent, different wording). The model is essentially asked, "What else might someone say to mean this?"
- Storage: All the original phrases and the new AI-generated variations are stored together in a database. Any time the system receives voice or text input, it checks against this expanded library to decide which command to execute.
The key insight is that the LLM doesn't need to be fine-tuned for this task — it uses a general-purpose model's existing language understanding to do the variation work automatically, which keeps the process cheap and repeatable across many commands.
What this means for voice assistants and command recognition
For anyone building or using voice-driven software — think assistants, smart home systems, or enterprise tools — the gap between what a user says and what the system recognizes has always been a manual, labor-intensive problem. Developers typically hand-write lists of accepted phrases, which never fully covers how real people speak.
Microsoft's approach would let a language model handle that expansion automatically, reducing the engineering work and theoretically making any command-driven interface more forgiving. If this ends up in products like Cortana, Windows voice access, or Microsoft 365 Copilot features, you'd spend less time rephrasing yourself and more time getting things done.
This is a practical, unsexy piece of infrastructure work — the kind that quietly makes products feel less frustrating to use. It's not trying to do anything flashy; it's solving a known, measurable gap in how voice systems handle natural language variation. The fact that the first independent claim was canceled at publication is a flag worth noting — it may still be working through USPTO examination.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.