Nvidia Patents an AI System That Chooses How Your Car Sees Around Itself
Parking cameras already stitch together a bird's-eye view of your car — but Nvidia wants a language-capable AI model to decide in real time which visualization style to use and how to configure it, rather than locking drivers into one fixed mode.
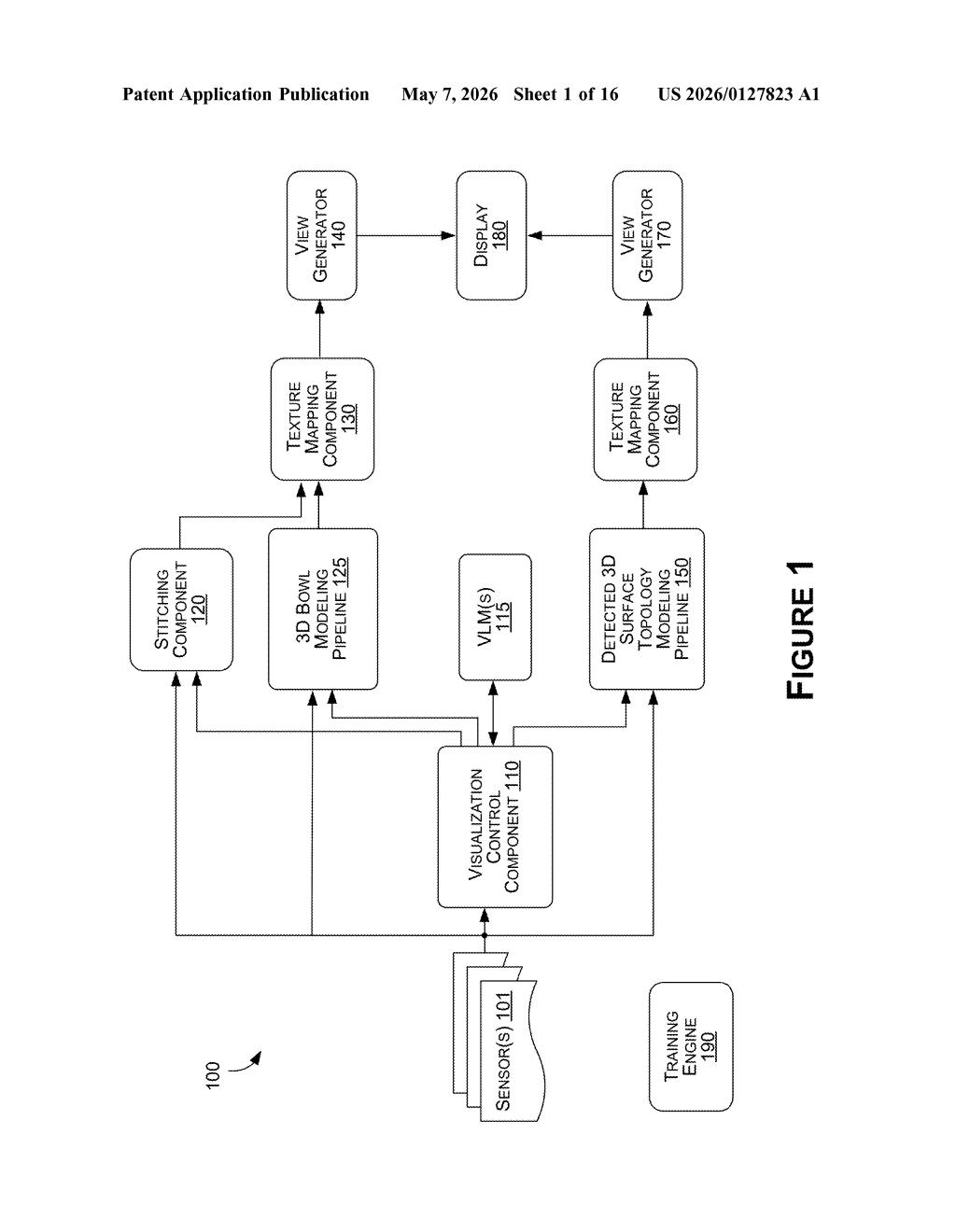
What Nvidia's VLM-driven surround view actually does
Imagine backing into a tight parking spot. Your car's cameras kick in, but instead of always showing the same flat overhead mosaic, the system looks at what's around you — a sloped driveway, a narrow garage, a crowded lot — and automatically picks the best way to show it to you.
That's the core idea in this Nvidia patent. A vision-language model (VLM) — the same kind of AI that can describe what's in a photo — gets shown the camera feeds and then picks which 3D visualization mode fits the scene. It might choose a smooth bowl-shaped view that curves the surroundings into a single panorama, or a mode that maps the actual ground topology if the surface is uneven.
The AI doesn't just pick a mode; it also dials in the finer settings: where the stitching seams between camera images go, how wide the blending zone is, and where the virtual camera is positioned. You'd get a view that's tuned to your actual environment rather than a one-size-fits-all default.
How the VLM picks and configures the 3D view pipeline
The patent describes a processing pipeline where a vision-language model (VLM) — an AI that reasons about visual content using natural language — acts as a high-level controller for surround-view rendering.
The system supports at least two visualization modes:
- Bowl visualization pipeline: models the area around a vehicle as a 3D bowl shape, giving that classic curved bird's-eye parking view
- Surface topology pipeline: detects the actual 3D geometry of the ground and maps camera textures onto it, useful for uneven terrain
When the cameras capture the environment, the VLM is prompted (given a structured query, not just raw images) to produce a response indicating which pipeline to use, what parameters to apply (seam placement, blend width, virtual camera position/orientation), and how to render the final viewport. The response from the VLM feeds directly into the chosen pipeline, which then composites the camera textures into the final 3D visualization shown on the vehicle's display.
A training engine component is also mentioned, suggesting the VLM can be fine-tuned specifically for this task — meaning it isn't just a general-purpose model bolted on, but one that could be trained on labeled surround-view scenarios.
What this means for next-gen parking and robotics displays
Today's parking and surround-view systems are largely static: an engineer picks a projection mode at design time, and every driver gets the same view regardless of context. Introducing a VLM as the decision-maker opens the door to context-aware visualization — a system that behaves differently in a sloped parking garage than in a flat lot, or that adapts when towing a trailer changes the relevant field of view.
For Nvidia, this fits squarely into its DRIVE platform strategy, where the same AI infrastructure powering perception also controls how sensor data gets presented to human drivers or autonomy stacks. If this approach ships in production, it could also apply to warehouse robots and other "ego-machines" that need real-time environmental awareness presented on a display.
This is a genuinely interesting application of VLMs — using them not to generate text or answer questions, but as a configuration selector inside a real-time rendering pipeline. It's a clever architectural move that sidesteps the brittleness of hard-coded visualization logic. Whether the latency of VLM inference fits inside a real-time parking assist loop is the obvious engineering question the patent doesn't have to answer.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.