Nvidia Patents a Configurable Neural Network Document Transcription System
Nvidia is patenting a smarter way to turn document images into structured text — one where you can dial up exactly what kinds of annotations you want the AI to produce, rather than getting a one-size-fits-all output.
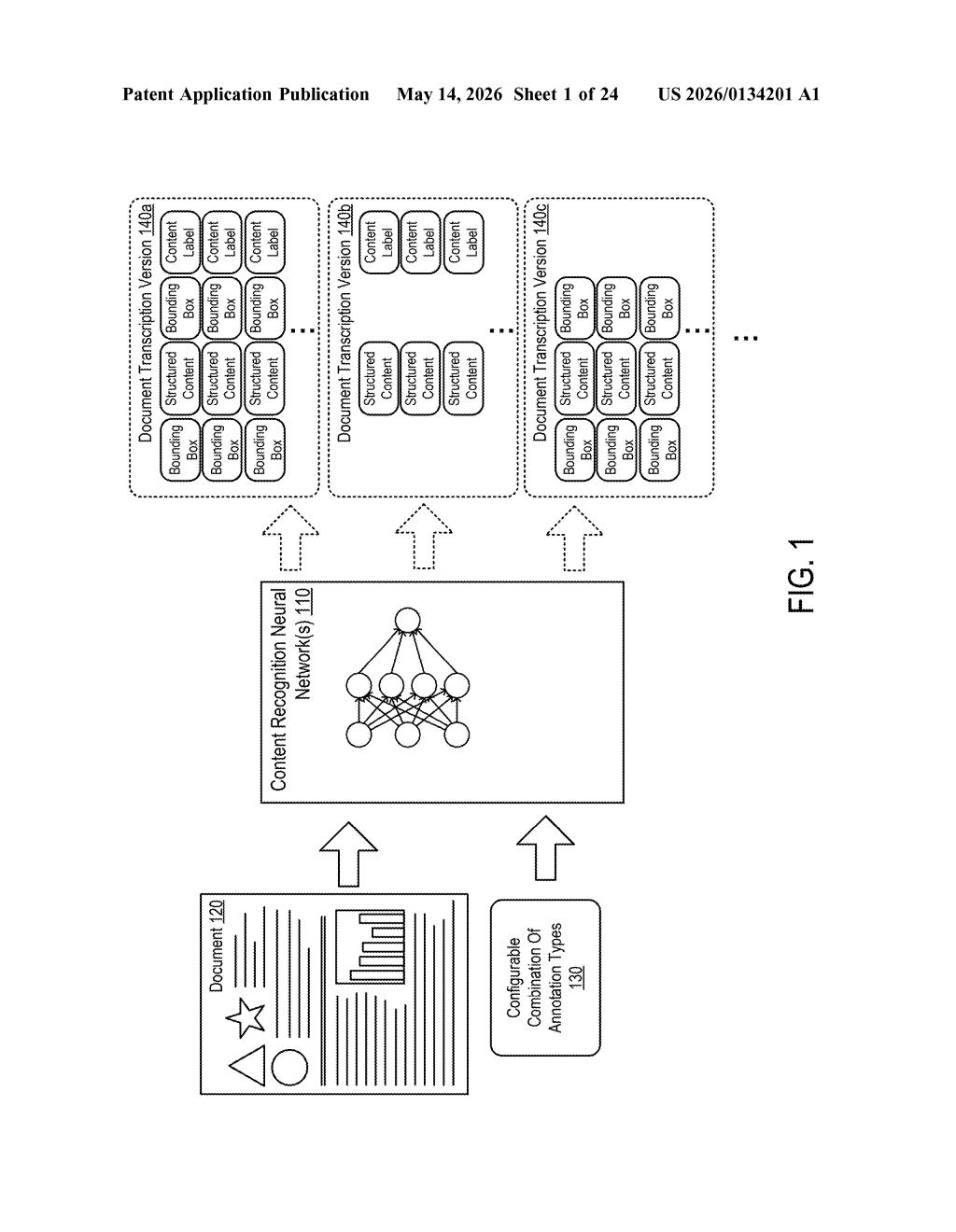
What Nvidia's annotation-driven document AI actually does
Imagine scanning a stack of contracts and wanting the AI to simultaneously pull out the text, flag the tables, identify headings, and mark up any signatures — all in one pass. Today, most document AI tools are rigid: you get what you get, and mixing annotation styles often means running multiple models.
Nvidia's patent describes a neural network system where you can configure a combination of annotation types as an input before the transcription even starts. The model then produces a structured output that includes all the requested annotation categories applied to the right parts of the document.
Think of it like ordering a custom sandwich instead of choosing from a fixed menu. You tell the system what you care about — layout, entity types, formatting markers, whatever — and it bakes all of that into a single transcription pass. That's a meaningful efficiency gain for anyone processing documents at scale.
How the encoder-decoder handles configurable annotation types
At its core, this patent covers a processor and associated circuits that feed a configurable combination of annotation types as input to one or more neural networks. The network then generates a document transcription — a structured digital representation of a document image — where each relevant portion of content carries the requested annotations.
The system uses an encoder-decoder architecture (a two-stage neural network design where the encoder compresses the visual input into a rich representation, and the decoder generates the structured text output). What's novel here is that the annotation configuration is baked into the input, not hardcoded into the model weights — meaning the same trained model can produce different flavors of output depending on what you ask for.
Annotation types could include things like:
- Text bounding boxes or layout structure
- Named entity labels (dates, names, dollar amounts)
- Document element types (heading, paragraph, table cell)
- Reading order or hierarchical structure markers
Downstream systems receive the transcribed documents with all requested annotations intact, making it easier to plug results into search indexes, databases, or compliance workflows without post-processing gymnastics.
What this means for enterprise document processing pipelines
For enterprise document processing — think legal, finance, healthcare, or government — the ability to get a single AI pass that produces exactly the structured output your pipeline needs is a real workflow accelerator. Most current approaches require chaining multiple specialized models or running the same document through several annotation stages separately, which adds latency and cost.
For Nvidia, this fits neatly into its push to make its hardware and software stack the backbone of agentic AI and document intelligence workloads. A configurable transcription model that runs efficiently on Nvidia GPUs is a useful showcase for its AI Enterprise platform — and a patent like this helps protect the architectural approach that makes it work.
This is solid, practical AI infrastructure work rather than a headline-grabbing moonshot. The configurable annotation idea is genuinely useful for enterprise document pipelines, and it's the kind of patent that quietly ends up inside cloud AI services without much fanfare. Worth watching if you're building in the document intelligence space.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.