Google Patents a System That Scrubs Opt-Out Content From AI Responses
What happens when an AI generates an answer using content from someone who explicitly said 'don't use my data'? Google's new patent is about catching that — and quietly fixing it before the response ever reaches you.
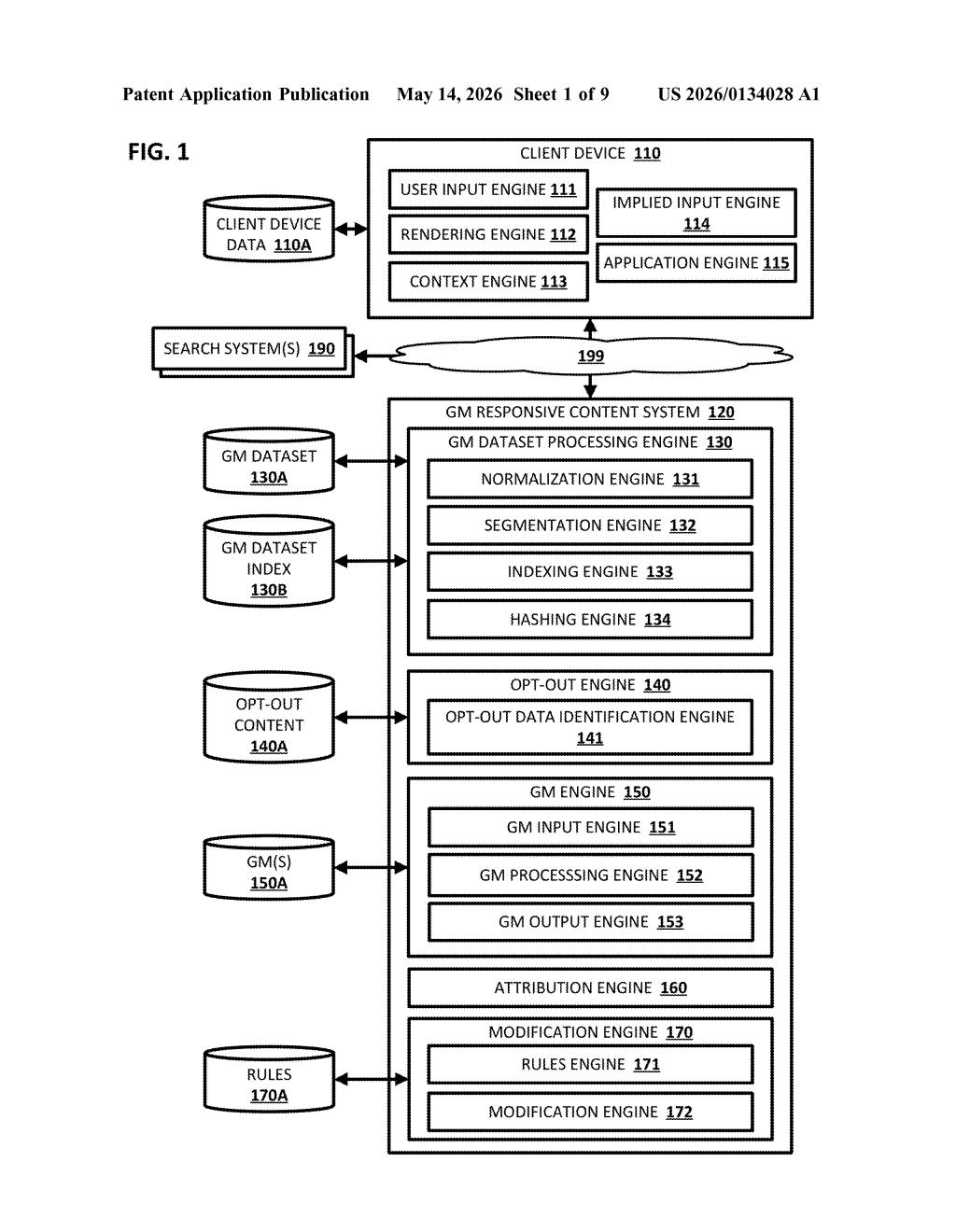
How Google's AI would honor creator opt-outs in real time
Imagine you're a writer who told Google: don't train your AI on my work, and don't let it quote me either. Google's AI might still accidentally produce something that closely mirrors your writing — because it was trained before your opt-out took effect. This patent describes a system designed to catch exactly that.
When Google's AI generates a response to your question, this system checks whether any portion of that response looks like it came from someone on the opt-out list — a creator, company, or individual who asked their data not to be used. If there's a match, the system rewrites or removes that chunk before you ever see it.
The key insight here is that opting out of training and opting out of being cited in outputs are treated as two separate but related choices — and the system tries to honor both.
How the system matches and rewrites opt-out segments
The patent describes a pipeline that runs between a generative model's raw output and the response that actually gets rendered on your screen.
Here's how it breaks down:
- Segmentation: The system splits both the AI's generated response and the known opt-out content into comparable chunks (segments).
- Hashing and indexing: Those segments are converted into fingerprints (think of a hash like a unique ID for a piece of text) and stored in a searchable index so comparisons can happen quickly.
- Matching: When new AI-generated content arrives, the system checks whether any segment matches a segment in the opt-out index — essentially looking for overlap between what the AI said and what someone asked not to be used.
- Modification: If a match is found, the offending segment is rewritten or removed, and the cleaned version is sent to the client device instead of the original output.
The opt-out list covers two distinct scenarios: data that someone didn't want used in training the model since its last update cycle, and data someone didn't want used in generating outputs at inference time. The system handles both.
Attribution rules (a separate engine mentioned in the architecture) suggest the system can also track where matched content came from — potentially useful for audit trails.
What this means for creators fighting AI training use
For content creators and publishers, this represents one of the first technically detailed patents describing a mechanism to enforce AI opt-outs after a model has already been trained — which is the hard problem. Most opt-out discussions focus on keeping data out of training sets, but this system also intercepts outputs at generation time.
For Google's AI products like Gemini and AI Overviews, this kind of infrastructure would be essential if regulatory pressure — or licensing deals with publishers — require the company to demonstrate that opted-out content genuinely isn't surfaced to users. It's less about being altruistic and more about building a defensible compliance layer.
This is a genuinely important patent, not because the underlying matching technology is novel, but because it addresses the hardest part of the AI copyright debate: what do you do when a model has already learned something it shouldn't use? Google is essentially proposing a runtime filter as a backstop. Whether it works well enough in practice to satisfy regulators or litigants is a very different question, but the architecture is thoughtful.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.