Nvidia Patents a Text-to-3D Pipeline for Simulation-Ready Virtual Characters
Nvidia is patenting a pipeline that takes a plain-English description — say, 'a hooded medieval tunic' — and spits out a fully simulation-ready 3D object geometry, no manual modeling required. The clever part is that it's built specifically for physics simulation, not just visual rendering.
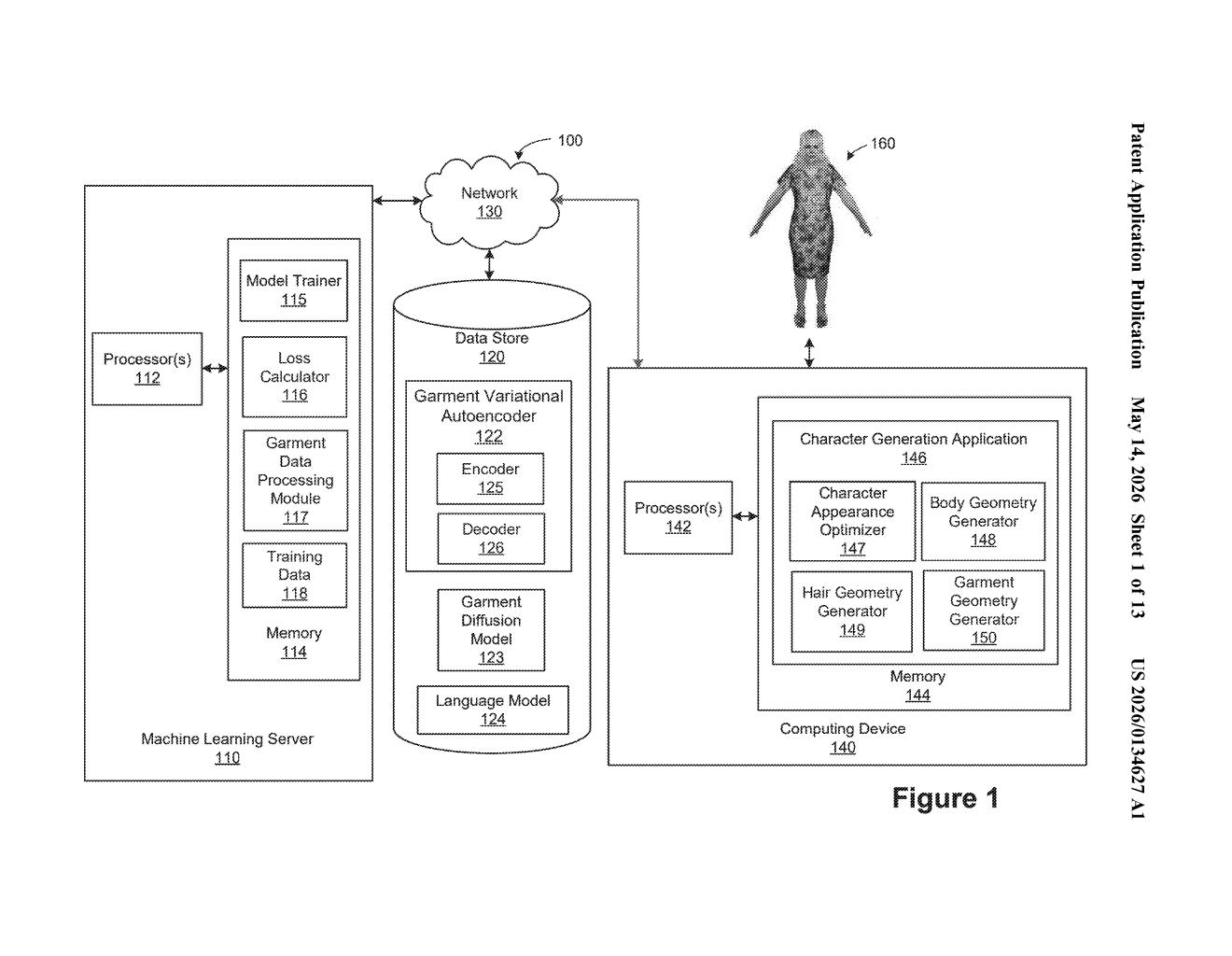
How Nvidia turns a text description into a 3D character
Imagine you're building a virtual world and you need a character wearing a specific outfit. Normally, you'd either hire a 3D artist or spend hours in modeling software. Nvidia's patent describes a system where you just describe what you want in plain English and the software generates the 3D geometry automatically.
The system is designed so the resulting objects aren't just pretty to look at — they're ready to drop straight into a physics simulation. That means the virtual clothing can drape, collide, and move like real fabric would, without extra work from a developer or artist.
This is particularly interesting for fields like robotics training, game development, and digital twins, where you need lots of varied virtual objects fast — and you need them to behave realistically in a simulated environment, not just sit there looking nice.
How the diffusion model converts language into object geometry
The core pipeline works in three stages, each handled by a different trained neural network component.
- Language embedding: Your natural language description (e.g., "a loose linen shirt with rolled-up sleeves") is first converted into a language embedding — essentially a dense numerical representation that captures the semantic meaning of the text.
- Diffusion model to geometry embedding: That language embedding is fed into a trained diffusion model (the same class of AI behind image generators like Stable Diffusion, but here operating in 3D geometry space rather than pixel space) to produce a geometry embedding — a compact representation of the shape of the object.
- Decoder to surface representation: A trained decoder takes that geometry embedding and outputs an object surface representation — a mathematical description of the object's surface, likely in a format like a mesh or implicit surface.
Finally, the surface representation is converted into usable first object geometry — the actual 3D structure of the virtual object. The patent specifically mentions garments as a key use case, with a dedicated garment geometry branch in the training architecture, suggesting the system is tuned to handle the complex, deformable surfaces that clothing requires in physics simulations.
What this means for game dev, robotics, and virtual worlds
For anyone building simulated environments at scale — think robotics companies training manipulation policies, game studios populating open worlds, or VFX pipelines — the bottleneck has always been content creation speed. Generating physically accurate 3D assets by hand is slow and expensive. A text-driven pipeline that outputs simulation-ready geometry could dramatically cut that cost.
Nvidia's positioning here is strategic. The company already owns the dominant physics simulation platform (Omniverse) and the dominant AI training hardware. A tool that auto-generates simulation-ready content from text fits neatly into that ecosystem — and could tighten the lock-in for developers building on Nvidia's stack.
This is a genuinely interesting patent because it targets a specific, painful gap: the difference between 'looks good in a render' and 'actually works in a physics sim.' Most text-to-3D research stops at visual fidelity. Nvidia is explicitly building for simulation correctness, which is exactly what their robotics and autonomous vehicle customers need. Worth watching.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.