Google Patents ML System That Packs More Workloads Onto Fewer Servers
What if your servers could safely host more workloads than they're technically 'supposed' to handle? Google is patenting a machine learning system that predicts compute usage patterns well enough to do exactly that — safely fitting extra tasks onto machines that would otherwise sit partially idle.
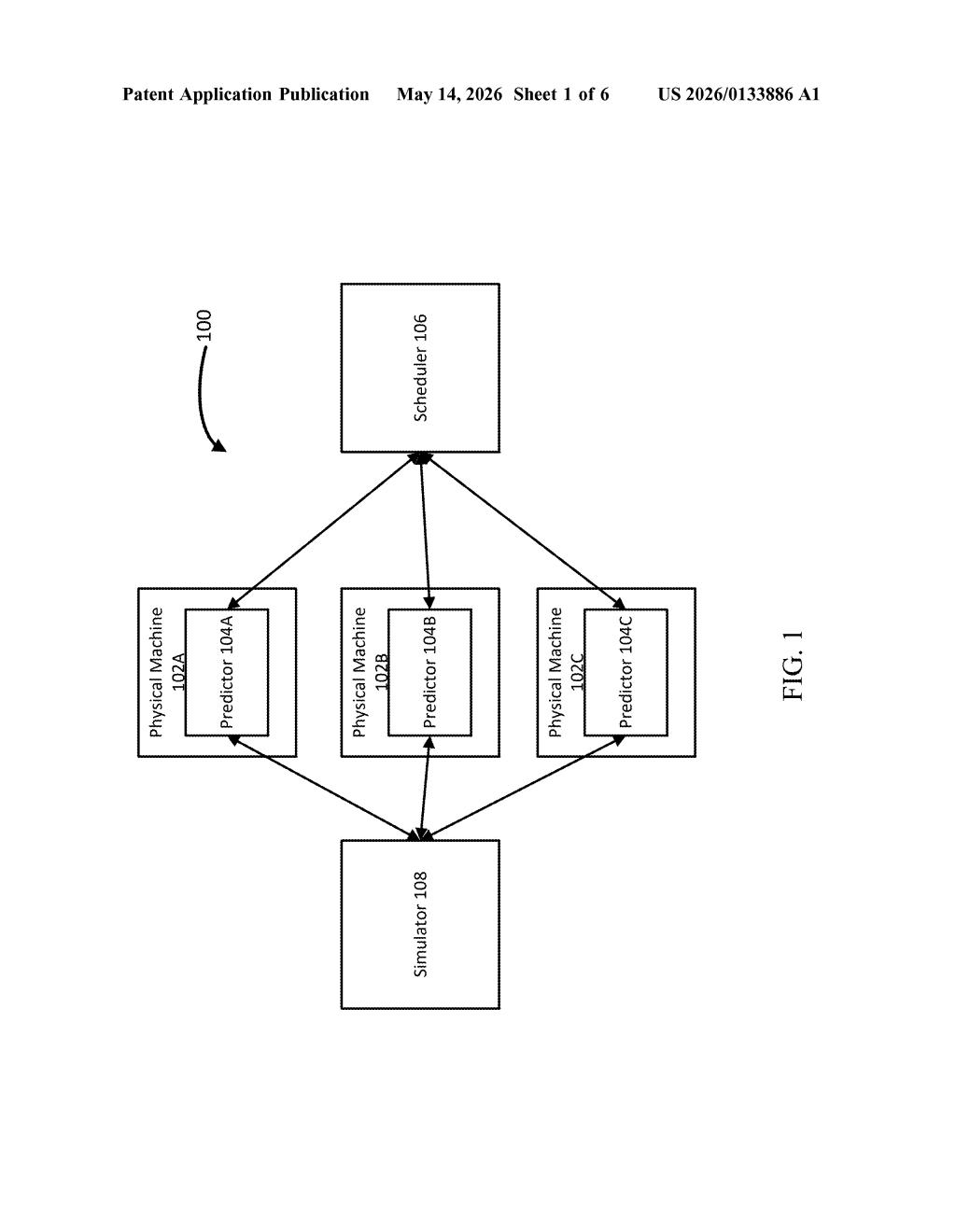
How Google's ML scheduler squeezes more from each server
Imagine a co-working space that books desks at 100% capacity, but the manager knows from experience that only 70% of people actually show up at any given moment. By tracking attendance patterns, they can let a few extra members in without anyone ever being left standing.
Google is applying that same logic to its data centers. Instead of reserving dedicated computing headroom for every task, this system uses a machine learning model to watch how much CPU and memory each job actually consumes over time. Because most workloads don't hit their peak all at once, the system can identify safe windows to slip in additional tasks.
The practical payoff: fewer physical servers needed to run the same number of jobs. That means real hardware savings at massive scale — a big deal when you're running one of the world's largest cloud infrastructures.
How the model predicts per-task usage across time intervals
The patent describes a scheduler for a multi-tenant compute cluster (a shared pool of servers running many different customers' workloads simultaneously). The core problem it solves is overprovisioning — the tendency to reserve more compute capacity than a job typically needs, just to be safe.
Here's the mechanism:
- The system continuously monitors resource usage (CPU, memory, etc.) for tasks already running on a physical machine.
- It breaks that usage history into intervals and computes statistics — things like average load, variance, and peak timing — for each interval.
- A machine learning model uses those per-interval statistics to predict what each task will consume in the near future.
- Individual task predictions are combined to estimate total machine load, then compared against available headroom before a new task is admitted.
The key insight is prediction at the task level rather than the machine level. By modeling each job's usage curve separately and then summing them, the system can account for the fact that different workloads peak at different times — making the aggregate prediction much more accurate than a simple utilization average.
What this means for cloud costs and data center efficiency
Cloud infrastructure runs on margins, and every server that can host one extra workload safely is a server Google doesn't have to buy. At the scale of Google Cloud or internal infrastructure like Borg, even a modest improvement in cluster utilization translates into enormous capital savings. This patent represents a systematic, data-driven approach to a problem that has historically been managed with conservative static buffers.
For enterprise customers, the downstream effect could be lower costs and better performance if tighter packing means fewer cold-start delays or more available capacity during demand spikes. It also signals where Google sees the frontier in infrastructure efficiency: not in better hardware, but in smarter scheduling software that treats resource prediction as a first-class ML problem.
This is unglamorous infrastructure work, but it's the kind of compounding efficiency gain that separates hyperscalers from everyone else. A few percentage points of better utilization across millions of servers adds up fast — this is worth paying attention to if you follow cloud economics or competitive dynamics between AWS, Azure, and Google Cloud.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.