Google Patents Its Wide & Deep AI Architecture Nearly a Decade After Publishing It
Google published its Wide & Deep learning architecture in a 2016 research paper — and is now, apparently, patenting it. That gap between 'we told the world' and 'we own it legally' is worth understanding.
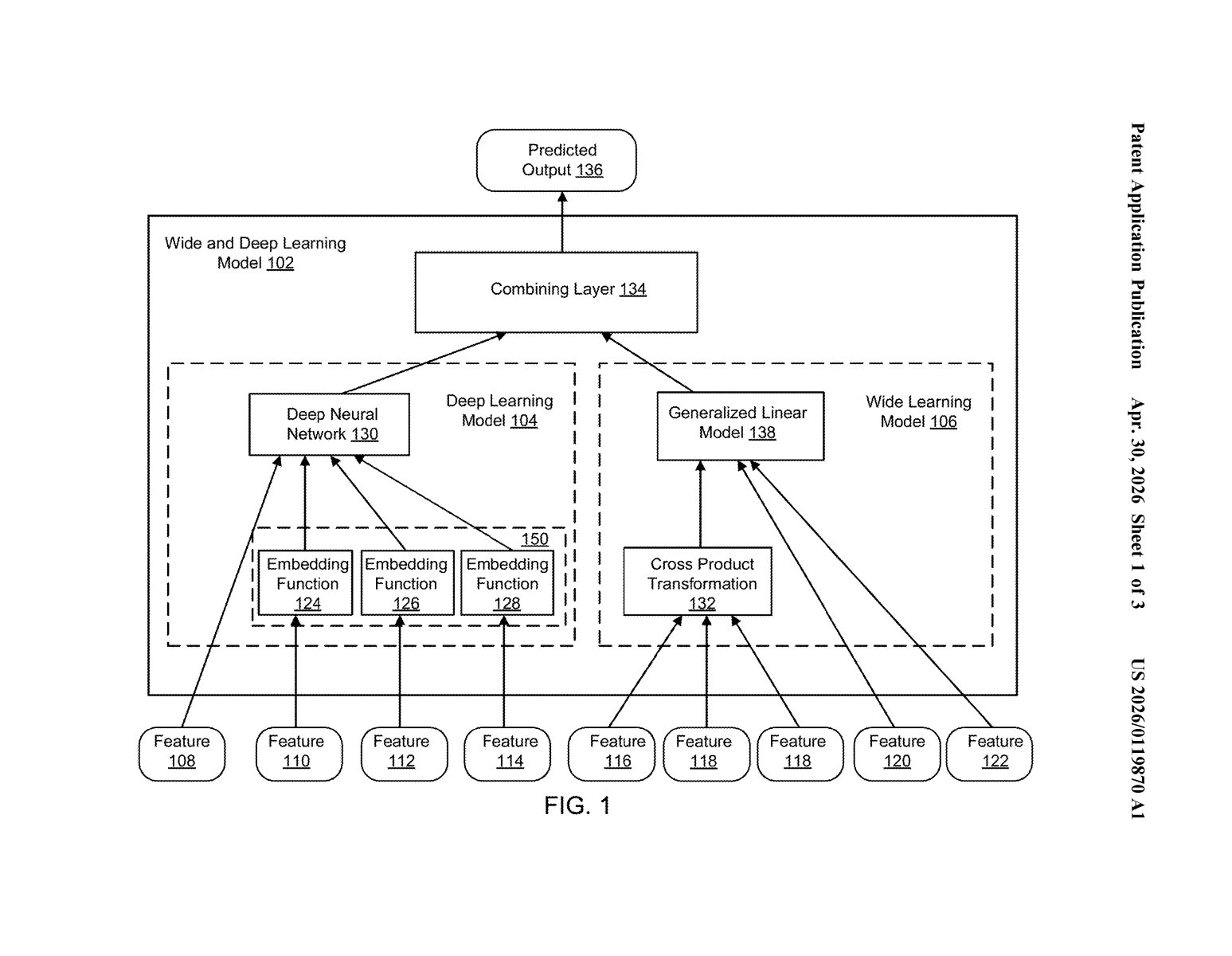
What Google's Wide & Deep model actually combines
Imagine you're trying to recommend an app to a user. One part of your brain memorizes rules: "this user always clicks puzzle games on Fridays." Another part generalizes: "people who like puzzle games also tend to enjoy word games." Good recommendations need both. That's the core idea behind Google's Wide & Deep architecture.
The wide model is essentially a lookup table — it remembers specific feature combinations from training data directly. The deep model is a neural network that learns abstract patterns by generalizing across examples. Combining them lets you get the benefit of memorization and generalization at once.
Google first described this system in a 2016 paper about Google Play app recommendations, and it became widely adopted across the industry. Filing a patent on it in 2025 — nearly a decade later — is an eyebrow-raising move, but not without strategic logic.
How the wide and deep layers split and rejoin
The patent describes a combined machine learning model that processes an input (a set of features, like user history, item metadata, or context signals) through two parallel sub-models, then merges their outputs.
The deep model is a multi-layer neural network. It takes raw features, embeds them into lower-dimensional vectors (think of embeddings as compressed numerical representations of categories), and passes them through stacked layers to learn non-obvious, generalized patterns — like cross-category user preferences.
The wide model is a generalized linear model — basically logistic regression with handcrafted or automatically generated feature crosses (i.e., multiplying features together to capture specific interactions, like "user is in the US" × "app is a game"). This component excels at memorizing rare-but-reliable patterns that neural nets might smooth over.
A combining layer then takes both outputs and produces a final prediction — in the original paper's use case, the probability a user installs a recommended app. Critically, both the wide and deep components are trained jointly, not separately, so their weights are optimized together end-to-end.
Why patenting nine-year-old research is still a move
Wide & Deep is not obscure research — it's been embedded in TensorFlow as a pre-built estimator since 2016, and derivatives of this architecture power recommendation systems at companies across the industry. Google openly shared it, which makes patenting it this late a legitimately unusual move.
Patents filed years after public disclosure face serious prior art challenges, and in this case Google itself is the most prominent prior art. Whether this patent would survive a validity challenge is a question for lawyers — but strategically, it signals Google is doing a retrospective sweep of its own research portfolio, possibly to strengthen its IP position as AI licensing disputes heat up.
This is a fascinating edge case in tech IP: Google patenting something it demonstrably published for free nearly a decade ago. The 2016 Wide & Deep paper has thousands of citations and shaped how the whole industry builds recommender systems. Filing a patent now is either defensive portfolio housekeeping or an aggressive late-play — and the gap between those two interpretations matters a lot depending on how Google chooses to enforce it.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.