Google Patents a Method for Recycling Generative AI Models as Search Encoders
Training a powerful AI model from scratch costs millions. Google's new patent describes a shortcut: take a generative model you already have, rewire its attention mechanism, and turn it into a search engine's retrieval brain.
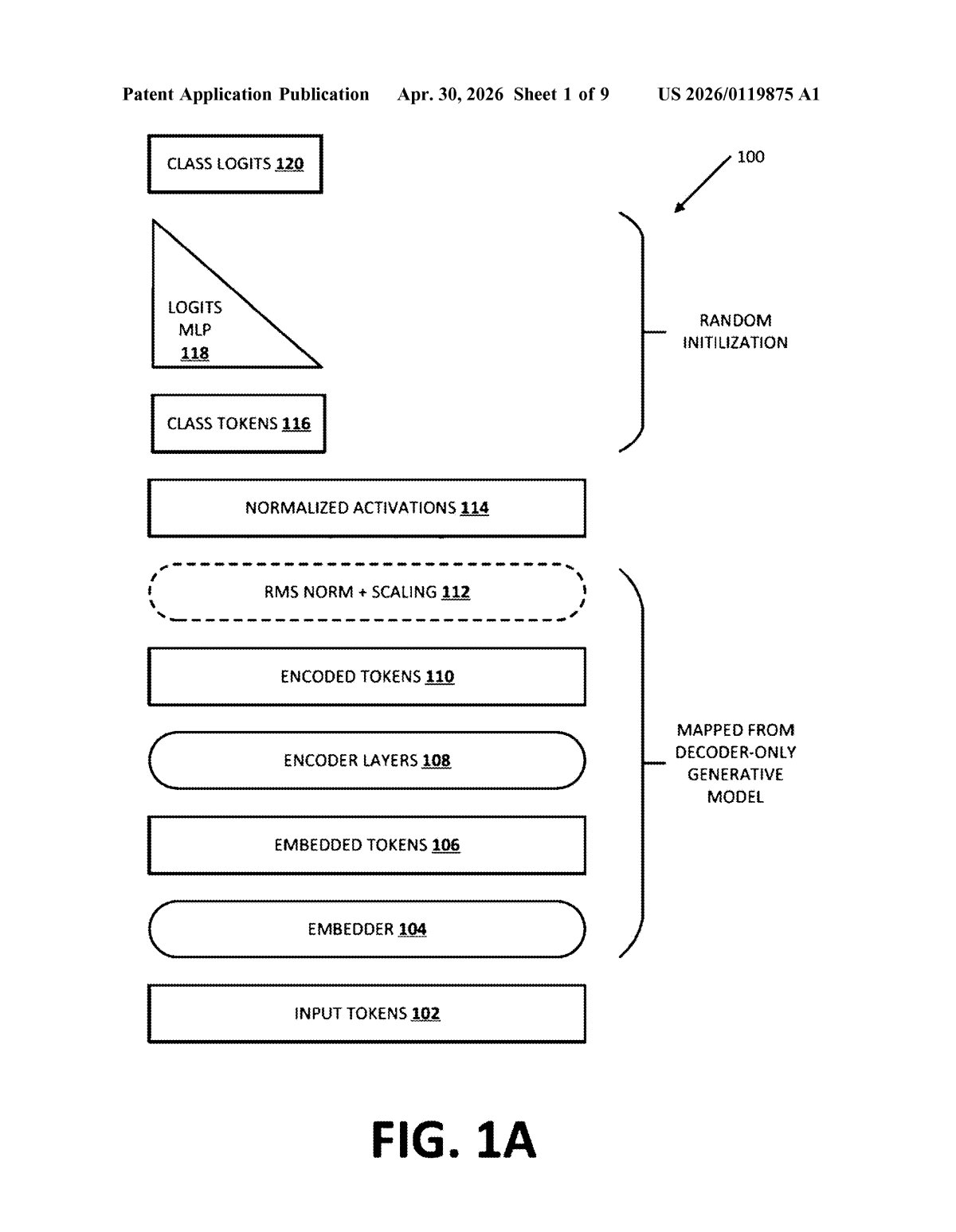
How Google repurposes LLMs for search retrieval
Imagine you trained a brilliant essay-writing assistant — it can predict the next word in any sentence and has absorbed a huge chunk of human knowledge. Now imagine you want to use that same intelligence to match search queries to relevant documents. The problem: the way it was built, it can only look backward at words it's already seen, not the full context at once.
That's the gap Google's patent tackles. Instead of building a brand-new model from scratch for search, the system takes a generative AI model (like the family of models powering ChatGPT-style tools), borrows its learned "weights" — think of weights as the distilled knowledge inside the model — and retrofits them into an encoder designed to understand full sentences all at once.
The result is a search-ready model that starts out already "smart," then gets fine-tuned specifically for retrieval tasks. That means less compute, less training time, and potentially a better search brain than you'd get starting cold.
How causal attention becomes bidirectional in Google's system
The patent describes a four-step conversion process that bridges two fundamentally different AI architectures.
Decoder-only models (like GPT-style LLMs) are trained with causal attention — a setup where each token (word fragment) can only "see" the tokens that came before it. This is great for text generation but limiting for understanding a full query or document holistically.
Encoder-only models (like BERT) use bidirectional attention — every token can attend to every other token simultaneously, giving the model full context. Encoders are what power embedding-based retrieval systems: they compress a query or document into a dense vector (a list of numbers) that captures meaning, then find matches by comparing vectors in a database.
Google's method:
- Identifies a pre-trained decoder-only generative model with causal attention layers
- Initializes a new encoder-only model by copying the weights from those attention layers — seeding the encoder with the generative model's knowledge
- Reconfigures those attention layers to use bidirectional attention instead of causal attention
- Fine-tunes the resulting encoder specifically for an encoding or retrieval task
The key insight is weight initialization: instead of random starting values, the encoder inherits learned representations from a model that has already processed vast amounts of text. This gives the training process a significant head start.
What this means for Google's AI-powered search stack
Google runs one of the world's largest retrieval systems — and the quality of that system depends heavily on how well it can encode the meaning of a query and match it to documents. Retrieval-augmented generation (RAG) systems, which power many AI assistants including Google's own Gemini-based products, rely on exactly these kinds of encoders to fetch relevant context before generating an answer. Better encoders mean more accurate retrieval, which means better answers for you.
On a broader strategic level, this patent signals that Google is looking to get more mileage out of the generative models it's already invested heavily in training. Rather than maintaining entirely separate model lineages for generation and retrieval, this approach could let a single well-trained model seed both use cases — a meaningful efficiency win at Google's scale.
This is genuinely clever infrastructure work, not a flashy consumer feature. The idea of bootstrapping encoder models from decoder weights is an active area of academic research, and Google patenting a specific implementation of it tells you this is heading into production search pipelines, not a lab experiment. If you care about how AI search actually works under the hood, this is worth understanding.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.