Intel Patents a Way to Stop AI Chips from Waiting on Their Own Memory
Every time an AI model runs, it has to move enormous tables of numbers — called weights — from storage into the chip that does the math. Intel's new patent wants to compress those numbers and quietly decompress them in transit, so the chip doing the work never has to wait.
How Intel shrinks the cost of loading AI model weights
Imagine you're downloading a large ZIP file and your computer automatically unzips it while it's still arriving — no extra step, no waiting. Intel's patent applies that same idea to AI models running on hardware.
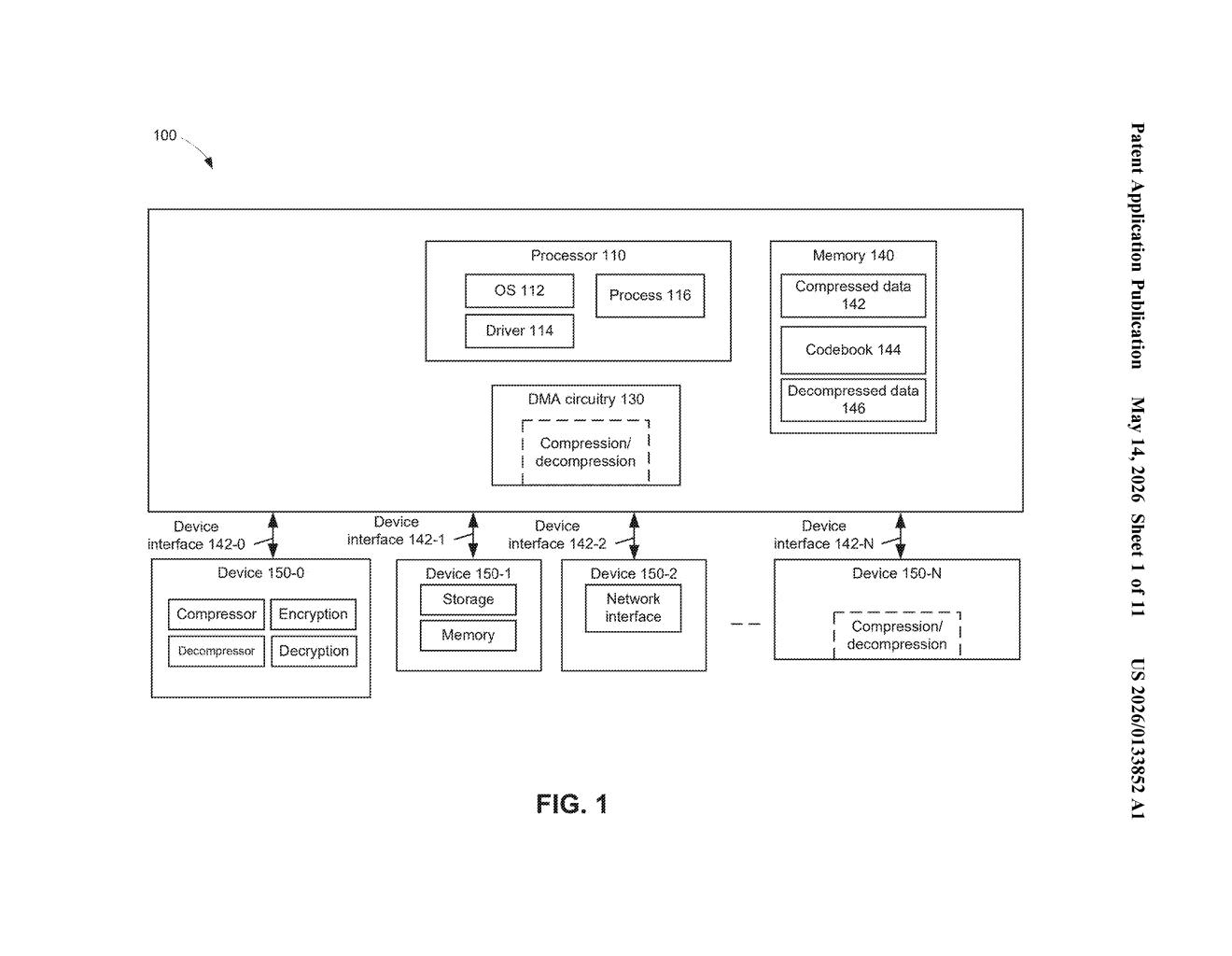
AI models are made up of billions of weight values — the numbers that define how the model thinks. Moving all those weights from memory to the compute chip is one of the biggest bottlenecks in modern AI. Intel's approach compresses those weights using a codebook (a lookup table where a short code stands in for a much larger number), then lets a DMA engine — a dedicated chip component that handles memory transfers — decompress them on the fly as they move.
The result is that your AI accelerator receives ready-to-use weights without ever seeing the compressed format, and the memory bandwidth needed to move data drops significantly. It's an efficiency trick that happens invisibly, below the level of software.
How the DMA engine decompresses weights mid-transfer
The patent describes a system where codebook compression is applied to weight data — the parameters stored in neural network models. In codebook compression, each original value is replaced by a short code value (like an index number) that points to an entry in a lookup table. Because the code values are much smaller than the original floating-point numbers, the data takes up less space in memory and requires less bandwidth to move around.
The key innovation is where decompression happens. Rather than storing weights in decompressed form or making the matrix-multiplication accelerator handle decompression itself, Intel routes that work through a DMA (Direct Memory Access) engine — a dedicated hardware block whose sole job is moving data between memory regions. The DMA engine is extended here to also decompress data inline, during the copy from one memory location to another.
The claim flow looks like this:
- A command is issued to copy codebook-compressed weight data from a first memory to a second memory.
- The DMA engine performs the copy and decompresses the data in the same pass.
- The decompressed weights land in the destination memory, ready for matrix operations.
The patent also mentions that the decompression work can be handed off to other devices — including dedicated decoder chips or AI accelerators — depending on what's available in the system.
What this means for on-device AI inference performance
The memory bandwidth wall is one of the most pressing constraints in AI inference today. Large language models and vision models have billions of parameters, and feeding those weights to compute units fast enough is often the bottleneck — not the raw compute. By compressing weights and decompressing them mid-flight via a DMA engine, Intel's approach reduces the effective bandwidth required without adding latency at the accelerator.
For you as an end user, this could translate to faster AI responses from devices running Intel silicon — whether that's a laptop doing local inference, a server running cloud AI, or an edge device. It also reduces the memory footprint needed to store model weights, which is increasingly important as models grow larger and hardware memory stays expensive.
This is genuinely useful systems-level engineering, not a flashy AI concept. The idea of pushing decompression into the DMA layer is a smart way to hide latency and reduce bandwidth pressure without changing the software stack. Intel is clearly thinking about making its accelerator ecosystem more competitive for AI inference workloads, and this kind of under-the-hood optimization is exactly the kind of thing that compounds into real-world performance wins.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.