Samsung Patents a Single Quantized Graph That Runs Multiple AI Models at Once
Running multiple specialized AI models on a phone is expensive — each one wants its own memory, its own quantization setup, and its own graph. Samsung's new patent tries to collapse all of that into a single shared structure.
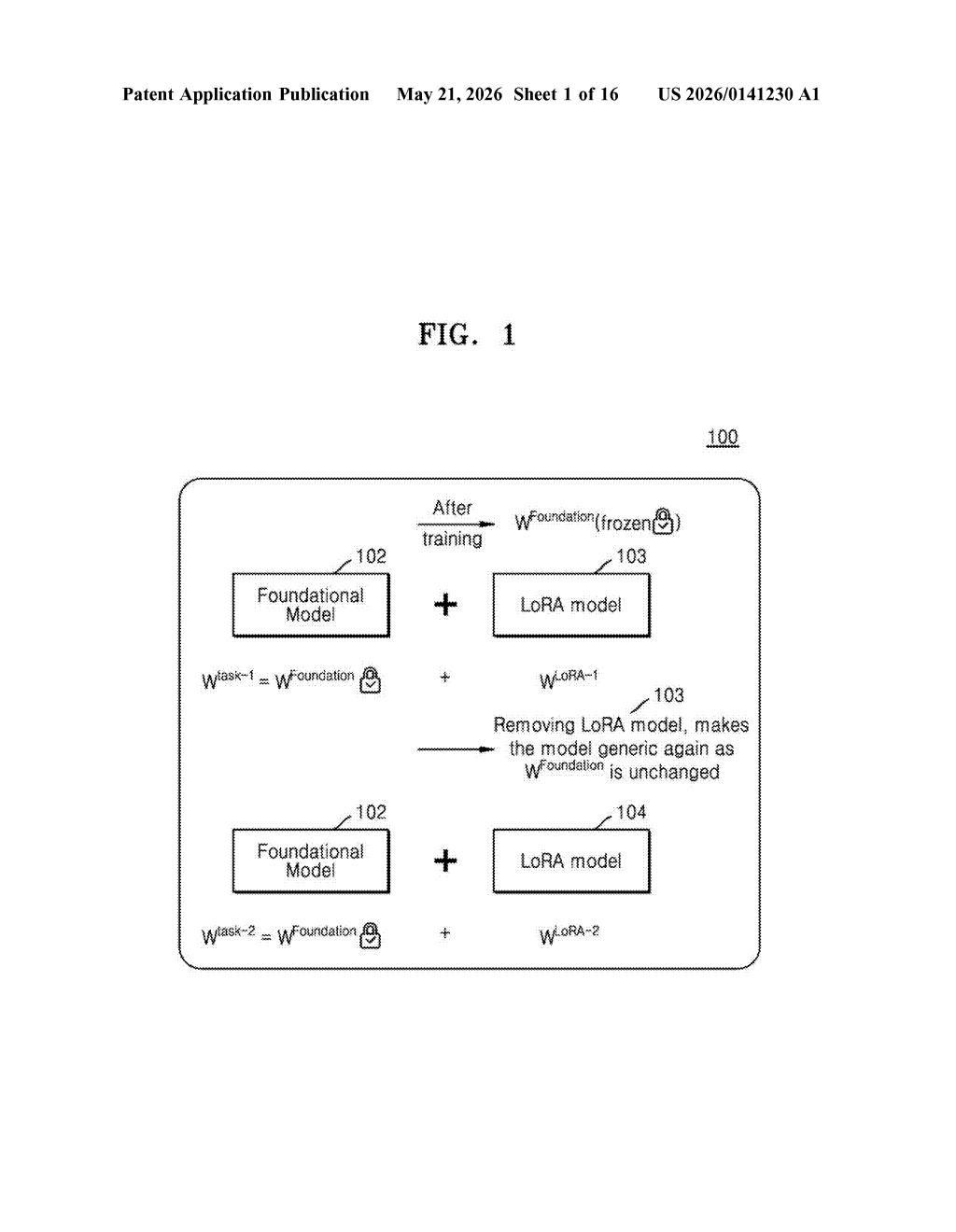
What Samsung's shared quantized AI graph actually does
Imagine you have a Swiss Army knife instead of a drawer full of separate tools. Samsung's patent is essentially trying to build that for on-device AI models.
When you run AI tasks on a phone — say, summarizing a document, generating an image caption, or drafting a reply — each task typically relies on a separately fine-tuned version of a base AI model. Keeping all of those versions loaded and ready is memory-hungry. Samsung's approach is to figure out which of those fine-tuned models is the most sensitive to compression, use that as the benchmark for how compressed everything gets, and then bake all the fine-tuned models into one shared compressed graph.
The result: your device loads one quantized model structure, and then at runtime it just picks the right fine-tuned "adapter" for whatever task you're asking it to do — without rebuilding or reloading the whole graph each time.
How Samsung picks the right quantization config for all models
The patent targets a specific pain point in deploying parameter-efficient fine-tuning (PEFT) models — lightweight adaptations (like LoRA adapters) that sit on top of a large base model and specialize it for specific tasks. Normally, if you want to run five PEFT-adapted tasks on-device, you either keep five separate quantized model copies around, or you re-quantize on the fly, both of which waste memory or compute.
Samsung's method works in three conceptual stages:
- Quantization sensitivity analysis: Before compressing anything, the system measures how much each PEFT model's output quality degrades under compression (this is the QSS — quantization sensitivity score). Think of it as stress-testing each adapter before you decide how tightly to squeeze everything.
- Worst-case calibration: The system picks the most sensitive PEFT model and uses it to define the compression parameters (scale and zero-point — the two numbers that define how floating-point weights get mapped to lower-precision integers). That way, the quantization config is conservative enough to protect every adapter, not just the robust ones.
- Single shared graph: All PEFT adapters are adjusted to fit that fixed quantization config, and they're all embedded into one unified model graph. At inference time, the system dynamically swaps in whichever adapter matches the current task — no re-quantization, no separate model loads.
The base model itself (described as something like a LoRA foundation model in the diagrams) stays frozen; removing a LoRA adapter simply reverts the graph to the generic base model behavior.
What this means for on-device AI on Galaxy hardware
For Samsung, which ships AI features across Galaxy phones, tablets, and wearables, the memory and latency costs of multi-model AI are a real hardware constraint. A system that lets you host one compressed graph and swap task-specific adapters dynamically could meaningfully reduce the RAM footprint of on-device AI — which matters a lot when you're competing with Apple Intelligence on devices with 8–12GB of RAM.
This also has implications for how Samsung structures its on-device AI pipeline going forward. If a single quantized graph can serve writing assistance, image understanding, and voice tasks simultaneously, the architecture gets simpler and potentially more power-efficient — two things that matter a lot when your AI is running on a phone battery.
This is unglamorous but genuinely useful systems work. The insight — calibrate quantization to your most fragile model, not your average one — is the kind of engineering pragmatism that actually makes on-device AI viable. It's not a research moonshot; it's the kind of patent that quietly ships inside a firmware update.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.