Microsoft Patents a Pipeline That Extracts Fact-Checkable Claims from AI Text
When an AI writes a paragraph, which sentences are actually checkable facts — and which are vague fluff? Microsoft is filing patents on a system designed to answer exactly that question, automatically.
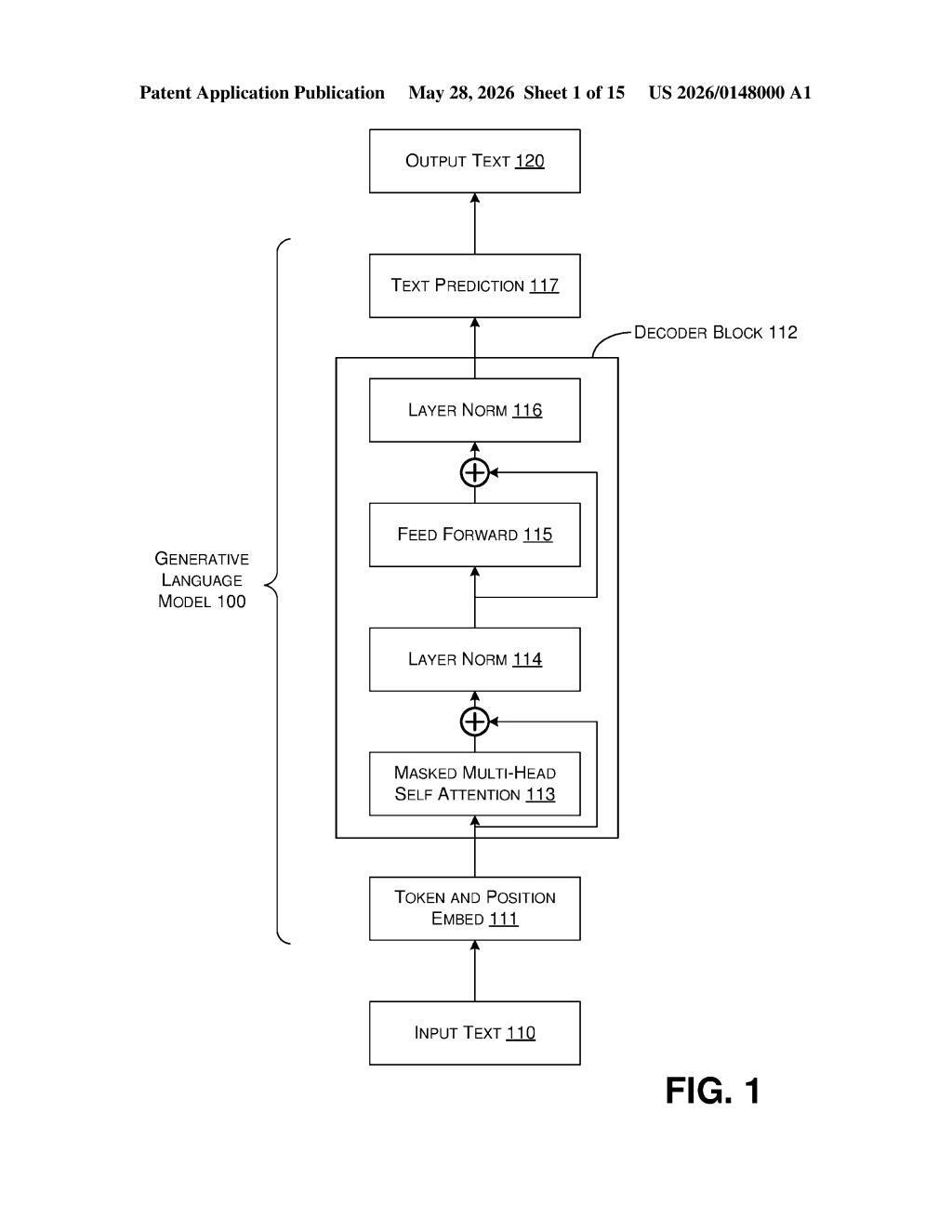
What Microsoft's proposition-extraction pipeline actually does
Imagine you ask an AI assistant to summarize a research report, and it hands you back several paragraphs. Some of those sentences make specific, checkable claims — "Company X reported $4 billion in revenue last quarter." Others are too fuzzy to verify — "Things have been challenging recently." Right now, there's no easy way to automatically sort those two types apart.
Microsoft's patent describes a multi-stage pipeline that does exactly that sorting. It takes a block of text — whether written by a human or generated by an AI — breaks it into segments, and then uses a generative language model to filter out anything that can't be cleanly verified. Segments that are too ambiguous or can't be broken into standalone facts get dropped along the way.
What's left is a clean list of verifiable propositions: atomic, fact-checkable statements that downstream tools can then assess, label, or feed into a fact-checking API. Think of it as a quality-control layer sitting between an AI's raw output and anything you'd actually want to trust.
How the filter stages isolate clean, verifiable claims
The system takes incoming text and runs it through a multi-stage processing pipeline with three main filtering gates before anything gets labeled a verifiable proposition.
- Segmentation: The text is first split into discrete chunks — sentences or clause-level segments — each carrying surrounding context so meaning isn't lost.
- Filtering stage: A generative language model is prompted to evaluate each segment against one or more filtering criteria (e.g., "Is this an objective, checkable claim?"). Segments that don't qualify — opinion, vague language, hedged statements — are discarded.
- Ambiguity filtering: Segments that pass the first filter but are still ambiguous (i.e., the meaning shifts depending on context) get flagged and removed if they can't be disambiguated.
- Decomposition stage: Compound claims that can't be reduced to a single verifiable unit are either broken apart or dropped if decomposition fails.
What survives all three stages are clean, atomic propositions — think "The Eiffel Tower is 330 meters tall" rather than "Paris has some very tall structures." The patent also describes a mapping layer that tracks which propositions came from which segments of the original text, and a labeling layer that can attach metadata. The whole thing is exposed via an API, so other services — fact-checkers, content moderation tools, grounding systems — can call it programmatically.
What this means for AI hallucination and content auditing
The immediate use case here is AI hallucination detection. One of the biggest practical problems with deploying large language models in enterprise settings is that their output mixes genuine facts with confident-sounding fabrications. Before you can check whether something is true, you need to isolate what the model is actually claiming. That's what this pipeline does — it turns a blob of prose into a structured list of checkable statements that a retrieval or verification system can actually work with.
Beyond hallucination, there's a broader content-auditing angle here too. The same pipeline could flag legally sensitive claims in auto-generated marketing copy, surface testable assertions in scientific abstracts, or feed a grounding layer that cites sources. If Microsoft integrates this into Copilot or Azure AI services, it could become part of the plumbing that makes AI output more auditable — something enterprises are actively demanding.
This is unglamorous but genuinely useful infrastructure work. The hard part of AI fact-checking has always been the pre-processing step — isolating what a model is actually asserting before you can check it against anything. Microsoft is building that layer as a composable, API-accessible service, which is exactly the right abstraction. Whether it ends up in a product or stays a research artifact, the problem it solves is real and unsolved in most current deployments.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.