Intel Patents a Query-Aware Graph Pruning System for RAG
When you ask an AI a question, the quality of the answer depends almost entirely on what context gets fed into the model. Intel's new patent tackles a surprisingly tricky part of that pipeline: figuring out which pieces of a knowledge graph to actually use — and which to throw away.
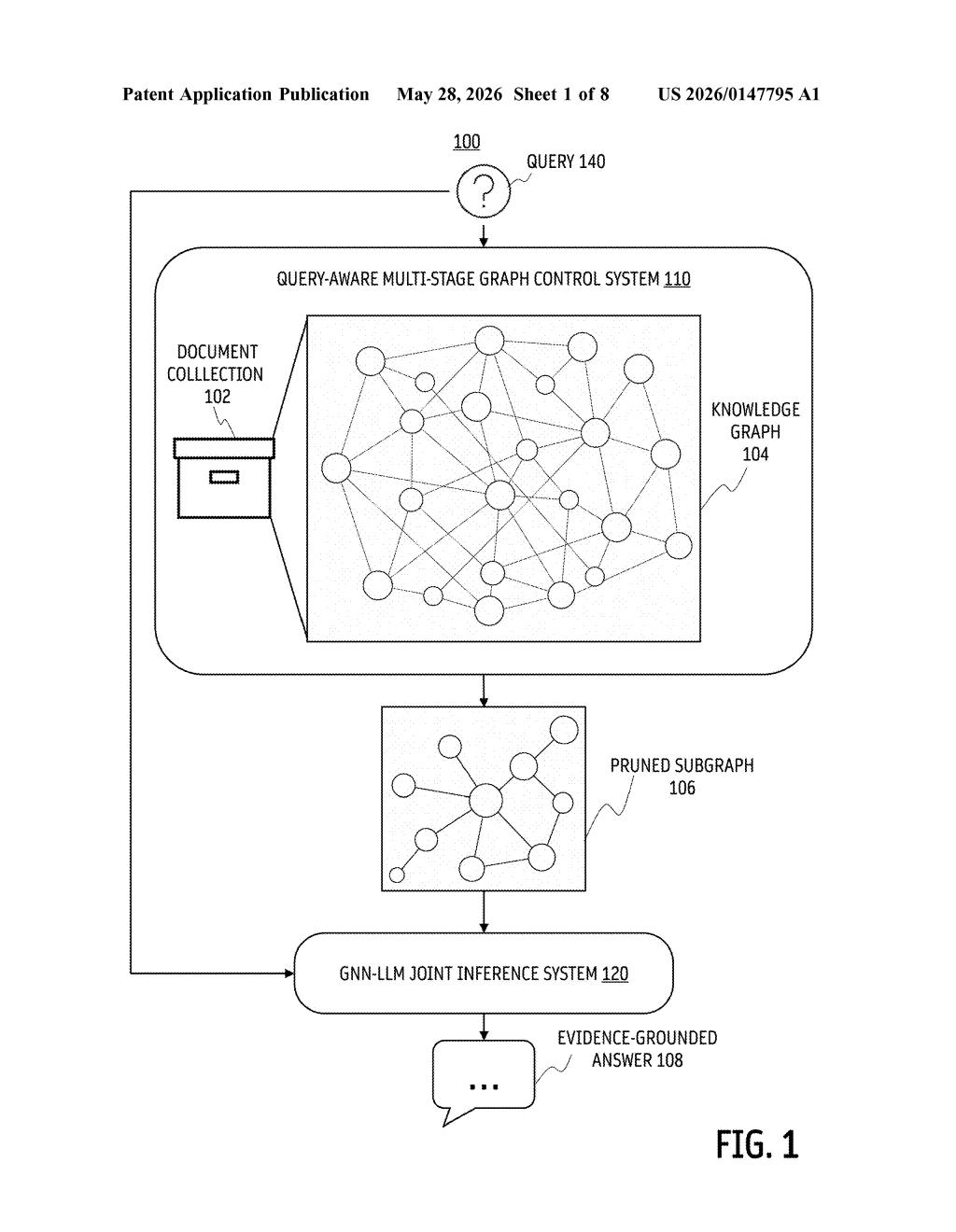
What Intel's graph-pruning RAG system actually does
Imagine asking a research assistant to answer a complex question, but their desk is buried under thousands of loosely related documents. Even if the right answer is in there somewhere, the noise makes it easy to miss. That's the core problem retrieval-augmented generation (RAG) systems face when they pull from large knowledge graphs.
Intel's patent describes a two-part fix. First, it combines two different search methods — one that looks for meaning (vector similarity) and one that looks for exact words (symbolic text search) — to find a better starting set of relevant nodes in the knowledge graph. That fusion makes the initial retrieval more reliable, even when people phrase questions in unexpected ways.
Then, instead of dumping that whole subgraph into an AI model, the system scores every node and connection based on how relevant it is to your specific query, and prunes the low-scoring pieces before passing the trimmed graph to a large language model. The result is a more focused, evidence-grounded answer.
How Intel scores and trims knowledge graph nodes
The patent describes a multi-stage RAG pipeline built around knowledge graphs — structured databases where facts are stored as nodes (entities) and edges (relationships between them).
The first stage is hybrid node retrieval. Rather than relying on a single search method, the system fuses results from two complementary approaches:
- Vector similarity search — embeds the query as a mathematical vector and finds nodes that are semantically close (meaning-based matching)
- Symbolic text search — traditional keyword or pattern matching that catches exact terminology the vector approach might miss
Combining both makes the initial node set more robust to lexical variation (the same concept described in different words).
The second stage is query-aware subgraph pruning. The system calculates prize parameters — learnable scores conditioned on the specific query — and assigns individual prizes to both nodes and edges in the subgraph. Think of it as relevance scoring: nodes and connections that matter for answering this particular question score high; tangentially related ones score low and get cut.
Finally, the pruned subgraph and the original query are fed together into a joint graph neural network and LLM inference process (a GNN encodes the graph structure, and the LLM generates the final answer). The key claim is that by the time the LLM sees the data, it's already been tightly filtered for relevance.
What this means for LLM accuracy and enterprise AI
RAG is currently the dominant pattern for grounding LLM outputs in real, verifiable data — and knowledge graphs are a particularly structured, reasoning-friendly form of that retrieval. The problem is that naive graph retrieval often pulls in too much context, which inflates token costs, muddies the model's focus, and can actually hurt answer quality. Intel's approach — scoring and trimming the graph before the LLM ever sees it — directly attacks that bottleneck.
For enterprise use cases where knowledge graphs encode proprietary data (think product catalogs, medical ontologies, or financial relationships), compact and task-relevant subgraphs aren't just a performance win — they're a cost and latency win too. If this approach works reliably in practice, it could make knowledge-graph-backed AI assistants meaningfully more accurate without requiring bigger or more expensive models.
This is a legitimately interesting systems-level contribution to the RAG space, not just a paper-filing exercise. The combination of hybrid retrieval and query-conditioned graph pruning addresses two real, well-documented failure modes in production RAG systems. Whether Intel ships this in a product or publishes it as a research direction, it reflects serious thinking about what makes LLM grounding actually work at scale.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.