Microsoft Patents a Way to Turn Vague AI Ratings Into Precise Diagnostic Scores
When users say an AI answer was 'not helpful,' that's almost useless data for engineers trying to fix it. Microsoft's new patent describes a pipeline that converts those fuzzy thumbs-up/thumbs-down signals into structured, ranked diagnostics showing exactly which factors made a response good or bad.
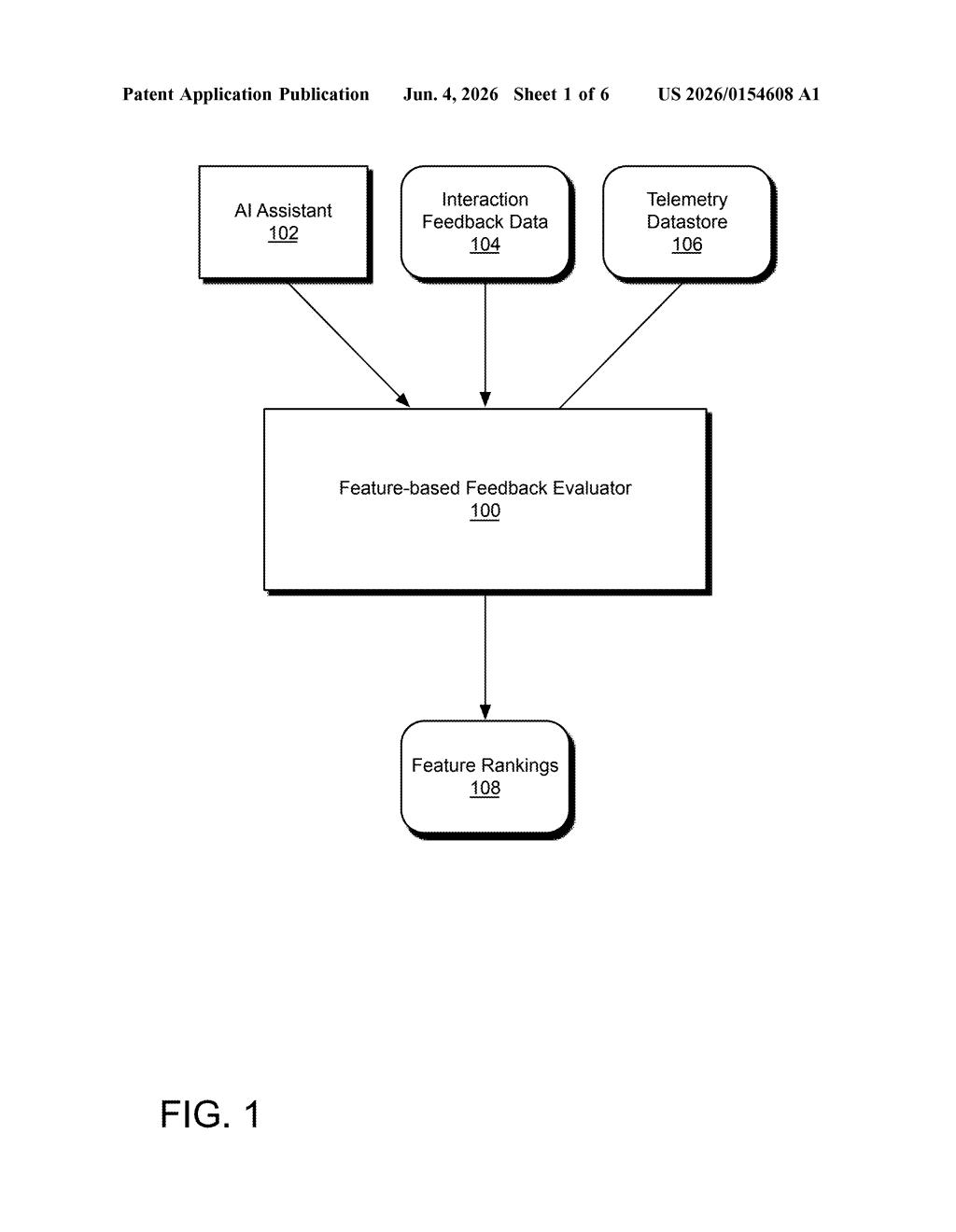
What Microsoft's AI feedback scoring system actually does
Imagine you're using a work chatbot and you click 'bad answer' after it gives you a confusing response. That click tells the team almost nothing — was the answer too vague? Off-topic? Just factually wrong? Right now, qualitative feedback like that gets lost or requires humans to manually sort through thousands of examples.
Microsoft's patent describes a system that automates the translation of that vague feedback into something measurable. It takes your question, the AI's answer, and your reaction, then uses a classifier to tag each interaction with a set of specific features — things like whether the answer addressed the right topic, how confident it sounded, or whether it matched the question's intent. Those tagged features are then combined with other data points and fed into a model that learns which features are actually driving user satisfaction or dissatisfaction.
The result is a ranked list of what's going wrong — and by how much. Instead of 'users don't like our AI,' you get 'topic misalignment is the top predictor of negative feedback on financial queries.' That's the kind of signal engineers can actually act on.
How the attribution model ranks each feature's impact
The system operates as a multi-stage evaluation pipeline. It starts by collecting feedback tuples — structured records containing a user's question, the AI assistant's answer, and the user's qualitative reaction (a rating, a comment, a thumbs-down).
Those tuples, along with a list of the AI's known topic areas, are fed into a few-shot classifier (an AI model that can categorize new inputs after seeing only a handful of labeled examples). The classifier outputs derived feature data — essentially, it tags each question-answer pair with a set of properties: Is this answer on-topic? Does it match the question type? Is the tone appropriate?
Next, those derived features are merged with metafeatures — additional context about each Q&A pair, like answer length or question complexity — and paired with a quantitative feedback target (a numeric score derived from the original qualitative feedback). This combined dataset is used to train an attribution model, which learns to predict feedback scores from features.
- The trained model then yields feature importance vectors — rankings that show how much each feature contributed to good or bad user feedback
- This tells developers not just that feedback was negative, but which specific characteristic of the answer was most responsible
- The few-shot approach means the classifier can generalize to new topic areas without needing massive labeled datasets
What this means for tuning Copilot and enterprise AI tools
For any company running an AI assistant at scale — think Microsoft's own Copilot across Office, Teams, and Azure — understanding why users dislike certain responses is genuinely hard. Human review doesn't scale, and raw thumbs-down counts don't tell you what to fix. This system creates an automated feedback loop that could dramatically accelerate iteration on AI quality.
The broader implication is that this kind of structured feedback attribution could become standard infrastructure for enterprise AI deployments. If you're an IT buyer evaluating AI tools, a vendor who can tell you 'here are the ranked failure modes and we fixed the top three' is a much more credible partner than one presenting only aggregate satisfaction scores.
This is genuinely useful infrastructure work — the kind of unglamorous plumbing that determines whether an AI product actually improves over time or just collects complaint data nobody acts on. The few-shot classifier angle is smart because it sidesteps the cold-start problem for new topic domains. If Microsoft ships this into Copilot's quality pipeline, it could be a meaningful accelerant for how fast the product gets better.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.