Google Patents a Teacher-Student Framework for Shrinking AI Models
What if you could take a massive, expensive AI model and compress its knowledge into a tiny one that runs cheaply on a phone? That's the core idea behind this Google patent on knowledge distillation — and its inventors include some of the biggest names in deep learning.
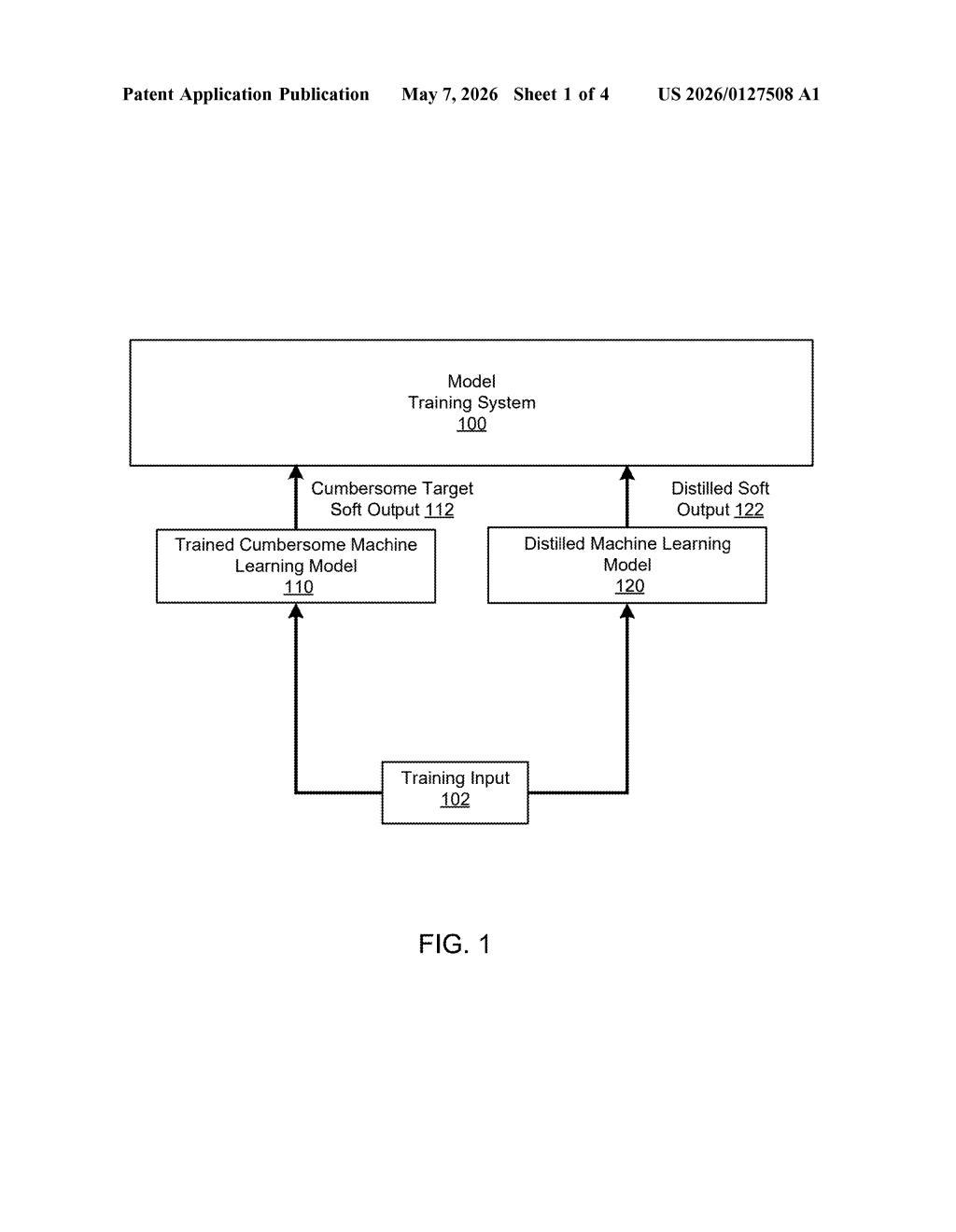
How Google's 'teacher-student' model compression works
Imagine you have a brilliant professor who's spent years studying every nuance of a subject. Now imagine having that professor tutor a younger student until the student can answer questions almost as well, but much faster and with far less overhead. That's essentially what this patent describes.
Knowledge distillation is a technique where a large, accurate — but slow and expensive — AI model (the "teacher") trains a smaller, faster model (the "student"). Instead of the student just learning from raw labeled data, it learns to mimic the teacher's full output: not just the right answer, but how confident the teacher was across all possible answers.
The trick is that those confidence distributions contain more information than a simple right/wrong label. If a teacher model says an image is 80% cat, 15% dog, and 5% fox, that nuance helps the student learn relationships between categories — and that makes the student much smarter than if it had just been told "it's a cat."
How the temperature parameter softens the teacher's outputs
The patent describes a training pipeline with two models: a large teacher model and a smaller student model. The teacher is trained first in the usual way. Then, for every training example, the teacher produces a soft output — a probability distribution across all possible classes, not just a single predicted label.
The key ingredient is a temperature parameter applied to the teacher's output layer. In neural networks, a "softmax" function converts raw scores into probabilities. Raising the temperature (a value greater than 1) makes those probabilities softer — spreading confidence more evenly across classes instead of spiking heavily on the top answer. This exposes more of the teacher's implicit knowledge about which classes are similar or related.
The student model then trains to match these soft outputs, minimizing a discrepancy term (essentially a loss function measuring how different the student's distribution is from the teacher's). This can be combined with standard training on hard labels too.
The result: a student model that is often dramatically smaller and faster than the teacher, but retains much of its accuracy — because it learned not just answers, but the teacher's reasoning patterns.
Why smaller, distilled models are a big deal for AI deployment
Distillation is one of the most practically important techniques in modern AI deployment. Large models like GPT-scale transformers or massive image classifiers are expensive to run at scale. Distilled models can deliver much of the same accuracy at a fraction of the compute cost — which means faster inference, lower cloud bills, and the ability to run capable AI on edge devices like phones or embedded hardware.
For you as a user, this is the kind of work that makes AI features snappier and cheaper to operate without noticeably degrading quality. Google applies distillation across products from Search to on-device speech recognition. The fact that this patent lists Geoffrey Hinton, Oriol Vinyals, and Jeff Dean as inventors signals this is a foundational filing — one that documents the original formalization of the technique rather than a narrow incremental improvement.
This is a genuinely historic piece of IP to see formalized as a patent: the Hinton-Dean-Vinyals knowledge distillation paper from 2015 is one of the most cited works in machine learning, and this filing appears to be its patent counterpart. Whether it's enforceable against the decade of follow-on work is a separate legal question entirely — but as a document, it's a fascinating artifact of how foundational research eventually enters the patent system.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.