Google Patents a Schema-Guided Machine Learning System for Document Entity Extraction
Pulling structured data out of unstructured documents — invoices, contracts, medical forms — is one of those problems that sounds simple but has defeated software for decades. Google's latest patent describes a machine learning pipeline that approaches the problem systematically, using a target schema to guide what to extract and spatial coordinates to verify it got the right answer.
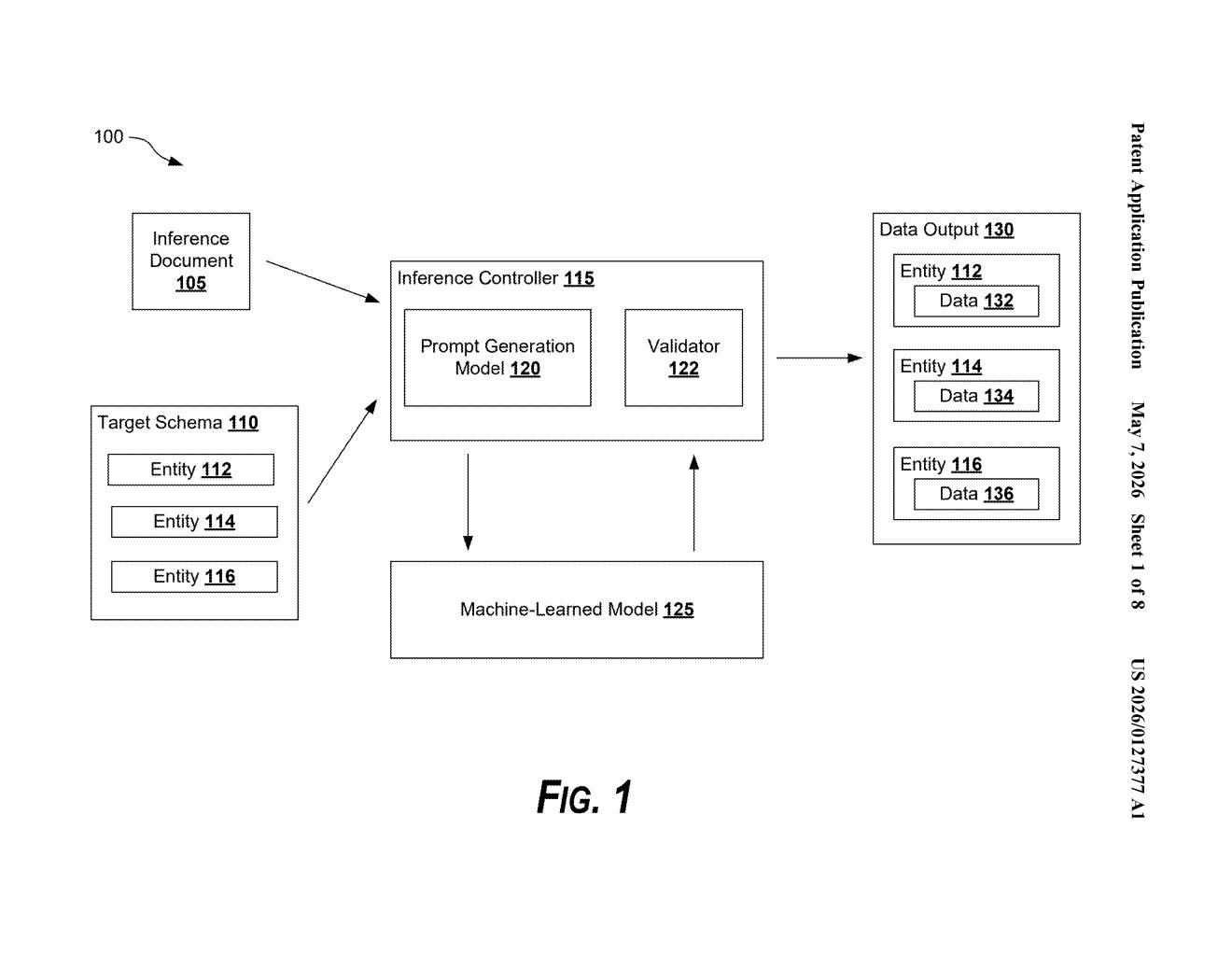
What Google's document entity extraction system actually does
Imagine you run a business that receives thousands of invoices a month, each formatted differently. You need to pull out the same fields — vendor name, date, total amount — from every single one. Right now, that's either a manual job or a brittle rules-based script that breaks whenever a vendor changes their template.
Google's patented system tackles this by pairing two inputs: the document itself and a target schema (basically a checklist of fields you want extracted). The ML model reads both together, so it understands not just what the document says, but what you're specifically looking for.
What makes it more trustworthy than a simple text grab is a validation step that cross-checks where the extracted data physically appeared on the page against where it was expected to be. If the model says a date was found in the footer when dates are always in the header, that's a red flag — and the system can flag or reject it accordingly.
How Google's schema inputs and spatial validation work together
The system takes two inputs for every extraction job: an inference document (the actual file you want to parse) and a target schema (a structured definition of the fields you want to pull out, like a form template).
From those, the pipeline generates document inputs and schema inputs separately, then pairs them into what the patent calls extraction inputs — essentially prompts that combine document context with a specific field query. Each combination is fed to a machine-learned model (the patent doesn't pin down an architecture, but the framing suggests a transformer-style encoder), which returns candidate entity data for that field.
The critical differentiator is the spatial validation layer. The system tracks two sets of coordinates:
- Reference spatial locations — where a field is expected to appear based on prior knowledge or schema metadata
- Inference spatial locations — where the model actually found the entity in the document
If those locations align within acceptable bounds, the extraction is confirmed. If they diverge significantly, the output is flagged or discarded. This guards against a common failure mode where an ML model confidently extracts the wrong piece of text that superficially matches a field.
What this means for enterprise document processing at scale
For any company processing large volumes of documents — insurance claims, legal contracts, tax forms, purchase orders — the bottleneck has always been reliable structured extraction. Rules-based OCR pipelines are fragile; pure LLM approaches can hallucinate. A system that combines schema-guided ML extraction with spatial sanity-checking sits in a practical middle ground that could make automated document processing genuinely production-ready.
This also fits neatly into Google's existing enterprise push via Document AI, its cloud product for document processing. A patent like this suggests Google is continuing to invest in the underlying extraction engine that powers those services — which means improvements here could quietly flow downstream to millions of business users.
This is solid, practical infrastructure work — not a flashy AI paper, but the kind of reliability engineering that makes automated document processing trustworthy enough to actually deploy in production. The spatial validation idea is the genuinely interesting piece here: it's a lightweight but principled way to catch extraction errors without requiring human review on every document. Worth watching if you're in the enterprise AI or document automation space.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.