Google Patents a Speech Recognition System That Understands Multiple Languages Simultaneously
Getting a voice assistant to accurately transcribe speech in multiple languages — especially when speakers switch mid-sentence — is one of the harder unsolved problems in AI audio. Google's latest patent takes a novel training approach: instead of one giant model that learns every language equally badly, it trains a system that dynamically assigns audio signals to small specialized sub-networks depending on what's being said.
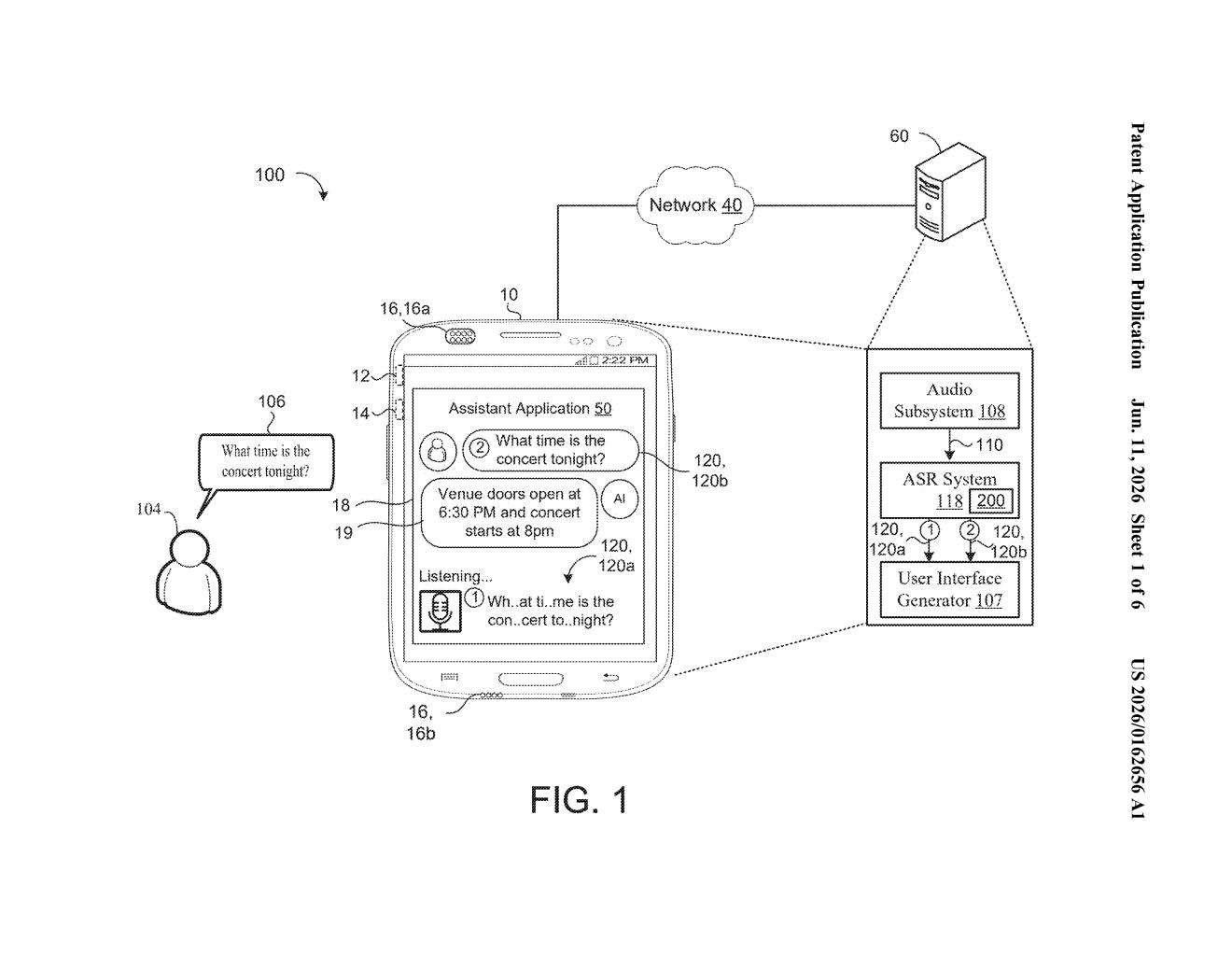
What Google's multilingual voice recognition actually does
Imagine asking your phone a question in Spanish, then finishing the sentence in English. Most voice assistants stumble here — they're trained on lots of languages but not always great at any of them, and switching mid-stream makes things worse. Google's patent describes a way to train a speech recognition model that handles this more gracefully.
The key idea is something called a "mixture of experts." Instead of one big block of the AI doing all the work, the system contains several smaller specialized sub-networks (the "experts"). A gatekeeper layer listens to each tiny slice of your audio and decides which expert is best suited to handle it — routing the signal accordingly, in real time.
The model is also trained to identify which language is being spoken at each moment, not just what words are being said. By learning both tasks at the same time, the system gets better at both — a bit like how learning to read music and play piano together tends to make you better at each than studying them separately.
How the gating layer picks the right expert for each audio frame
The patent describes a training method for a multilingual automatic speech recognition (ASR) model — the kind of system that converts spoken words into text, in multiple languages, as the audio streams in.
At its core, the architecture uses a Mixture-of-Experts (MoE) design embedded inside a Conformer encoder (a type of neural network particularly well-suited to audio). Each layer of the encoder contains multiple feed-forward expert networks — small specialized processing units — plus a gating layer that decides, at each time step, which expert or pair of experts should process the current audio signal. This dynamic routing means different parts of the model can specialize in different acoustic patterns or languages without needing entirely separate models.
The training process is notably dual-purpose. Each audio clip is paired with:
- A ground-truth transcription (what was actually said)
- A language identifier token (which language was spoken)
The model trains on both simultaneously — an ASR loss (how wrong was the transcription?) and a language identification loss (did it correctly detect the language?). The encoder's output feeds both a decoder for transcription and a separate language-prediction head. Joint training on both objectives forces the encoder to build representations that are useful for language detection and transcription at the same time, which tends to improve performance on each.
What this means for real-time multilingual voice assistants
Voice interfaces are increasingly expected to handle multilingual users without configuration — you shouldn't have to tell your assistant which language you're about to speak. Systems that detect language and transcribe simultaneously, in a streaming (real-time) context, are directly relevant to products like Google Assistant, Pixel's Live Transcribe, and Google Meet's live captions.
The mixture-of-experts approach is also computationally attractive: rather than scaling up a single monolithic model to cover dozens of languages, you get specialization without proportional cost increases. For you as a user, the practical upside would be fewer transcription errors when switching languages mid-conversation, and faster, more accurate captions in multilingual meetings.
This is solid, incremental research work — not a flashy product announcement, but the kind of architectural improvement that quietly makes Google's voice products noticeably better over time. The joint language-ID-plus-transcription training approach is a real engineering insight, and mixture-of-experts is a proven scaling technique that Google has applied successfully elsewhere (in large language models). Worth watching if you follow voice AI closely.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.