Microsoft Patents a System That Picks the Right AI Inference Trick for Every Job
Not every AI question deserves a full chain-of-thought reasoning marathon — and Microsoft is now patenting a system that figures out exactly how much horsepower each query actually needs.
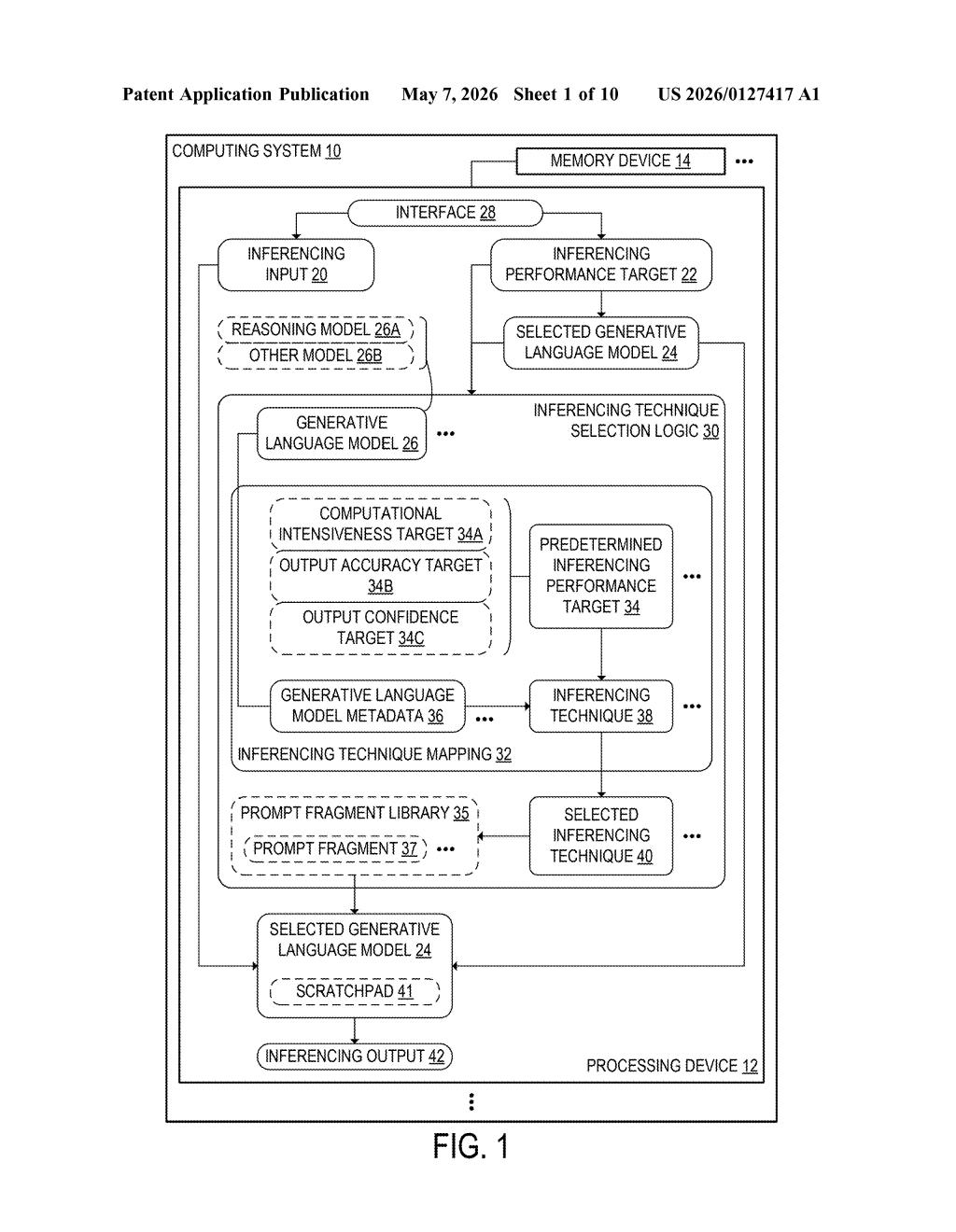
How Microsoft routes queries to the right AI model and method
Imagine asking an AI assistant to autocomplete a short email versus solve a multi-step medical diagnosis. Those two tasks shouldn't cost the same compute time or money — but today, many AI systems treat them the same way. Microsoft's patent tackles that inefficiency head-on.
The system works like a smart traffic controller. You send it a question along with a performance target — basically a hint saying whether you want a fast-and-cheap answer, a highly accurate one, or something you can trust with confidence. The system then picks both the right AI model for the job and the right technique for running it.
One key detail: the system checks whether the chosen model is a "reasoning model" (one that thinks through problems step by step) or a standard model. That distinction changes which techniques get applied. Think of it like knowing whether you're driving a sports car or a pickup truck before deciding which road to take.
How the inferencing technique mapping selects model and method
At its core, this patent describes an inferencing orchestration system — a layer that sits above a pool of generative language models and decides how to run each incoming query.
When a request arrives, it carries two things: the actual input (your prompt) and an inferencing performance target chosen from a predefined menu. That target could represent:
- Computational intensiveness — how much processing power is acceptable
- Output accuracy — how correct the answer needs to be
- Output confidence — how certain the system should be before returning a result
The system consults an inferencing technique mapping — essentially a lookup table that pairs each model with each performance target and lists which inference techniques apply. Techniques might include things like chain-of-thought prompting (where the model reasons step by step), majority voting across multiple outputs, or fast single-pass generation.
Critically, the system also reads model metadata to check if the selected model is a reasoning model (like OpenAI's o-series or similar). Reasoning models already do internal deliberation, so layering additional chain-of-thought techniques on top would be redundant — or even counterproductive. The patent's logic gates out those redundant combinations automatically.
What this means for LLM deployment costs and reliability
For anyone building or using AI-powered products, compute cost is a real constraint. Running a heavyweight reasoning model with extra inference techniques on every query — even trivial ones — burns money and adds latency. Microsoft's system tries to solve this by making the routing decision automatic and systematic, rather than leaving it to developers to hardcode per use case.
This is especially relevant as Microsoft deploys AI across Azure, Copilot, and enterprise tools where query volume is massive and workload types are wildly varied. A smarter dispatch layer could meaningfully reduce infrastructure costs while keeping response quality where it needs to be — and that's a compelling operational advantage at scale.
This is solid, pragmatic infrastructure work — the kind of thing that doesn't make headlines but quietly saves millions in cloud compute. The most interesting technical claim is the reasoning-model awareness: the system knows not to double-apply deliberation techniques when the model already does that internally. That's a real insight, not just plumbing.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.