Nvidia Patents an AI System That Predicts Server Demand Before It Arrives
What if your cloud infrastructure could see a traffic spike coming and spin up extra servers before users even notice a slowdown? That's the core idea behind Nvidia's latest patent.
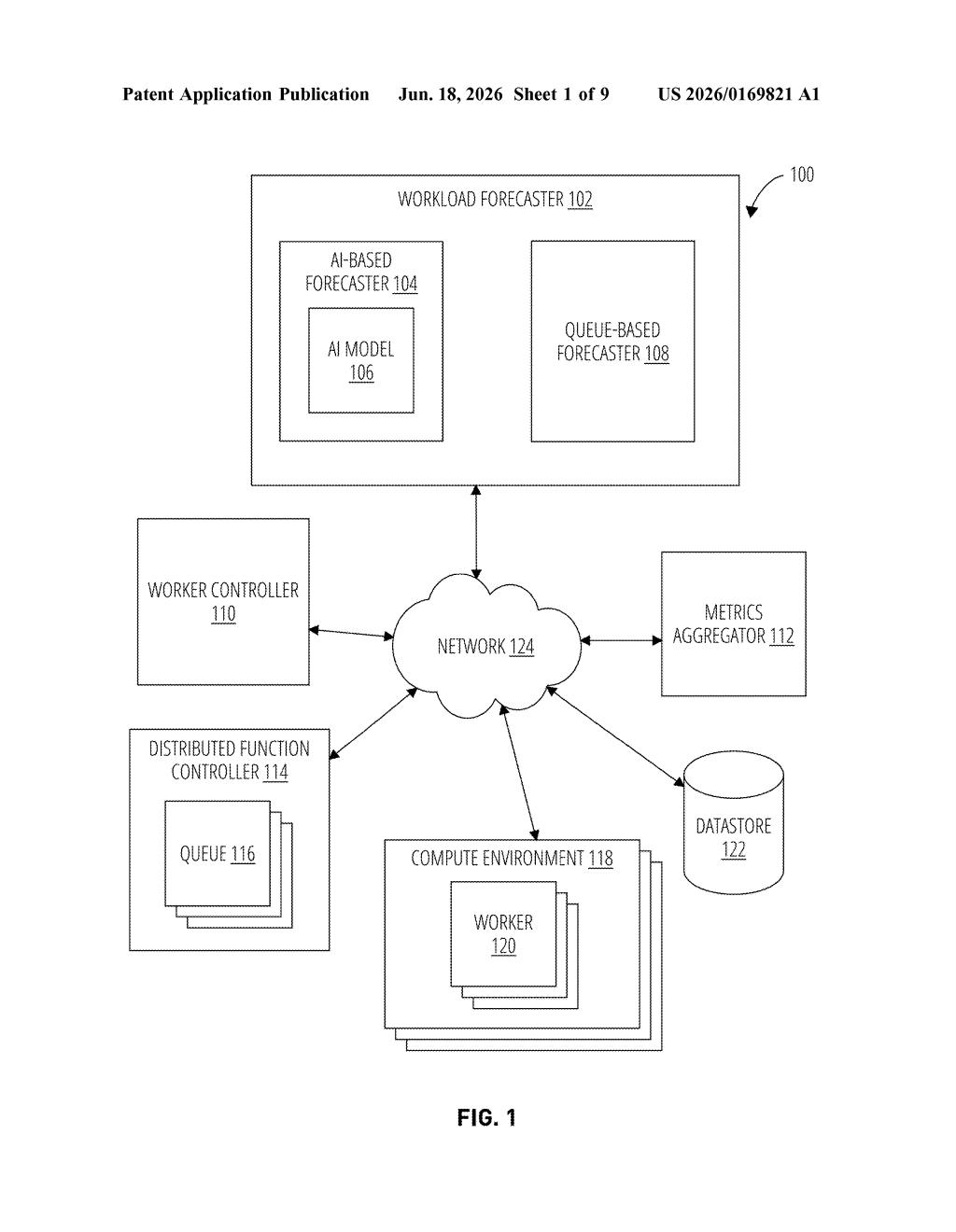
How Nvidia's workload-prediction system actually works
Imagine a restaurant that can somehow predict exactly how many customers are walking through the door in the next hour — and has the kitchen staffed accordingly before the rush hits. That's roughly what Nvidia is trying to do for computer servers.
Right now, most cloud systems wait until they're overwhelmed with requests before spinning up more computing power. By then, users already experience slowdowns. Nvidia's patent describes an AI model that watches incoming work requests in real time and forecasts how many are likely to arrive soon — then tells the system to add or remove computing workers ahead of time.
The result is that servers can be scaled up proactively instead of reactively. For a company like Nvidia, which runs AI inference services (essentially, the servers that answer your AI queries), getting this timing right means faster responses and lower wasted capacity when demand drops.
Inside the autoregressive and Fourier forecasting model
The patent describes a three-step pipeline. First, the system continuously monitors incoming work requests — think API calls to an AI model, rendering jobs, or database queries — counting how many arrive within a set time window.
Second, it feeds that count into an AI forecasting model that combines two mathematical tools:
- Autoregressive terms — the model looks at recent history to predict near-future demand (similar to how weather forecasting uses yesterday's data to inform tomorrow's prediction)
- Fourier series terms — a technique that detects repeating patterns, like daily or weekly cycles in usage (so the model 'knows' that Mondays at 9 a.m. tend to be busy)
Third, the predicted demand number is handed off to a worker controller — essentially the orchestration layer (think Kubernetes-style infrastructure) that decides how many server processes to keep running. If the forecast says a surge is coming, the controller spins up more workers. If demand is predicted to fall, it scales back down to save resources.
The combination of cyclical pattern detection and recent-history weighting is designed to handle both predictable patterns and sudden spikes.
What this means for cloud computing costs and AI services
For Nvidia, which is aggressively building out AI cloud services and inference infrastructure, reactive scaling is a real cost problem. Every second a system is over-provisioned wastes money; every second it's under-provisioned frustrates users. A forecasting layer that stays one step ahead of demand could meaningfully cut both failure modes.
For you as an end user of AI services, the practical upside is fewer "service unavailable" moments during high-traffic periods. For enterprise customers buying Nvidia's cloud AI infrastructure, it's a direct argument for lower operating costs — you pay for compute you actually need, not a permanent buffer to absorb surprise spikes.
This is solid infrastructure engineering — not flashy, but the kind of work that actually determines whether an AI service feels fast or sluggish at scale. Nvidia filing this suggests it's thinking seriously about the operational side of running AI inference at volume, not just selling GPUs to others who figure it out themselves. The Fourier-plus-autoregressive approach is a well-established forecasting combination; the interesting question is how well it handles novel, unpredictable spikes that don't fit historical patterns.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.