Salesforce Patents a Universal Adapter That Runs Any AI Model, Anywhere
Salesforce is patenting a middleware layer that lets companies deploy machine learning models built in any framework — TensorFlow, PyTorch, you name it — without writing custom execution logic for each one. Think of it as a universal adapter for AI models.
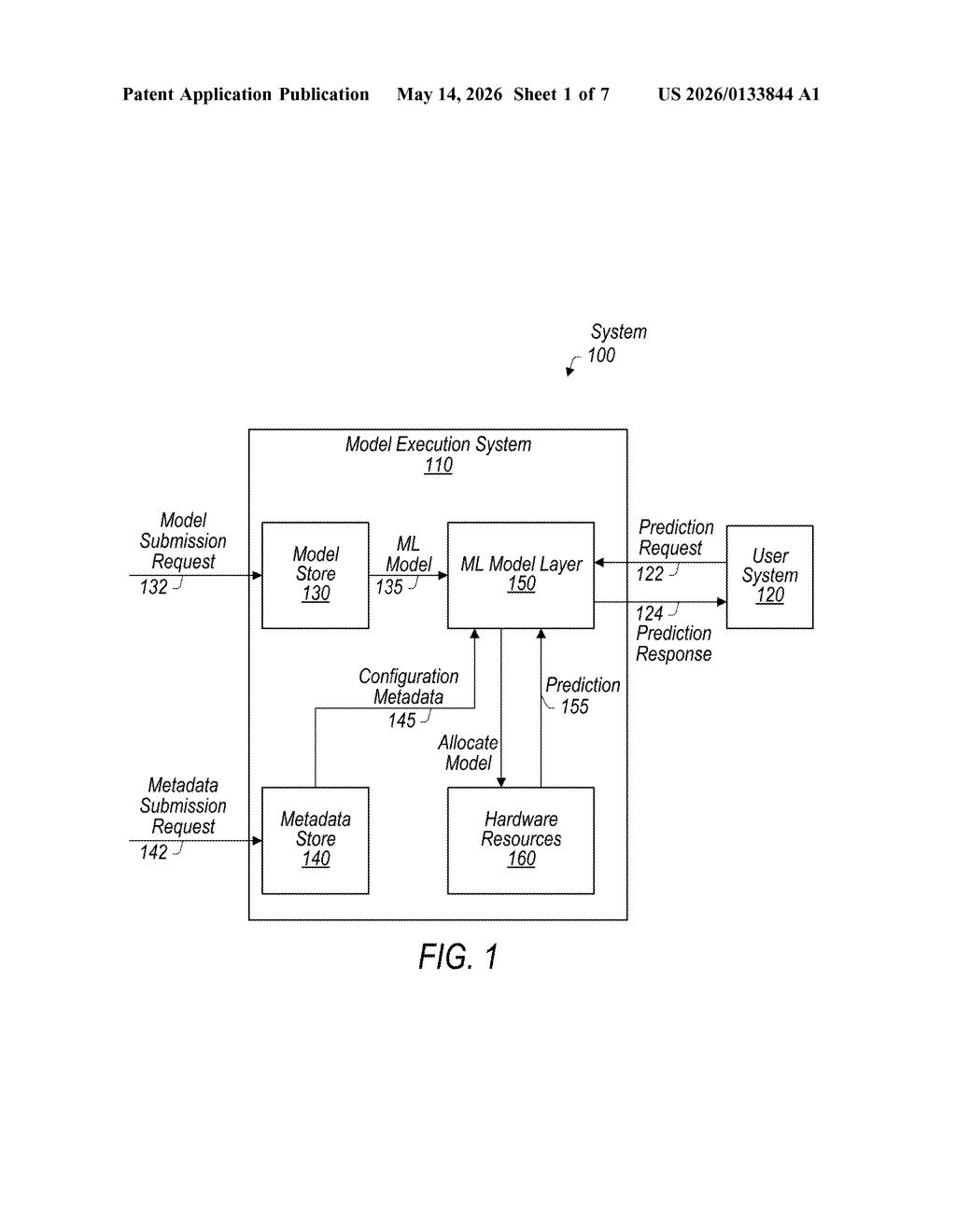
What Salesforce's ML model layer actually does
Imagine you've built an AI model using one tool, but your company's cloud platform only understands a different tool. Normally, someone has to write a bunch of glue code to make them talk to each other. Salesforce's patent describes a system that eliminates that problem entirely.
The idea is a single ML model layer — a kind of universal intake desk — that accepts models built in any framework. You submit your model along with some configuration metadata (basically a settings file describing what the model needs), and the system figures out the rest. It handles picking the right hardware, loading the model, and returning predictions back to you.
This means a data science team could hand off a model without needing to document exactly how to run it on the underlying infrastructure. The platform reads the metadata and makes those decisions automatically. For enterprise AI deployments, that's a meaningful reduction in friction.
How the layer routes models to the right hardware
The patent describes a model execution system with a dedicated ML model layer sitting between the users submitting models and the hardware that actually runs them. The layer accepts two main inputs: configuration metadata (a structured description of the model's requirements and provenance) and prediction requests from end users.
When a model is submitted, the system stores the configuration metadata separately from the model itself. Later, when a prediction request arrives, the system uses that stored metadata to make key runtime decisions — most notably, which type of hardware resource (CPU, GPU, specialized accelerator) to allocate for loading and running that specific model.
The core novelty here is that the submitting entity — a developer or data team — does not need to define execution logic. The platform infers what's needed from the metadata rather than requiring hand-crafted deployment scripts for each framework (e.g., TensorFlow, PyTorch, scikit-learn).
The flow looks roughly like this:
- Model + config metadata submitted to the ML model layer
- Metadata stored; model registered in the system
- Prediction request received from a user
- System selects hardware resources based on metadata
- Model loaded, inference run, prediction response returned
What this means for Salesforce's AI platform strategy
For Salesforce, this is squarely about making Einstein AI and its broader platform more accessible to enterprise customers who use a mix of ML frameworks. Right now, deploying a model to a production environment usually requires ops teams to write deployment wrappers — a slow, error-prone step. A universal intake layer could dramatically shorten that cycle.
More broadly, this kind of abstraction is the plumbing that makes platform lock-in work in Salesforce's favor. If your models run effortlessly inside Salesforce's infrastructure regardless of how they were built, you have less reason to move them elsewhere. It's a quiet but strategically important piece of the enterprise AI platform wars.
This is unglamorous infrastructure work, but it's exactly the kind of patent that quietly shapes how enterprise AI platforms compete. The ability to accept any framework without custom wiring is a real operational pain point for large organizations, and solving it at the platform layer is a smart move. Don't expect a press release — do expect to see something like this show up inside Einstein Platform or MuleSoft's AI capabilities.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.