Nvidia Patents a Self-Recovery System for AI Training Crashes
Training a large AI model can take weeks across hundreds of servers — and a single hardware crash can wipe out days of progress. Nvidia's new patent describes a system that detects the crash automatically and rolls back to a safe save point without stopping the whole run.
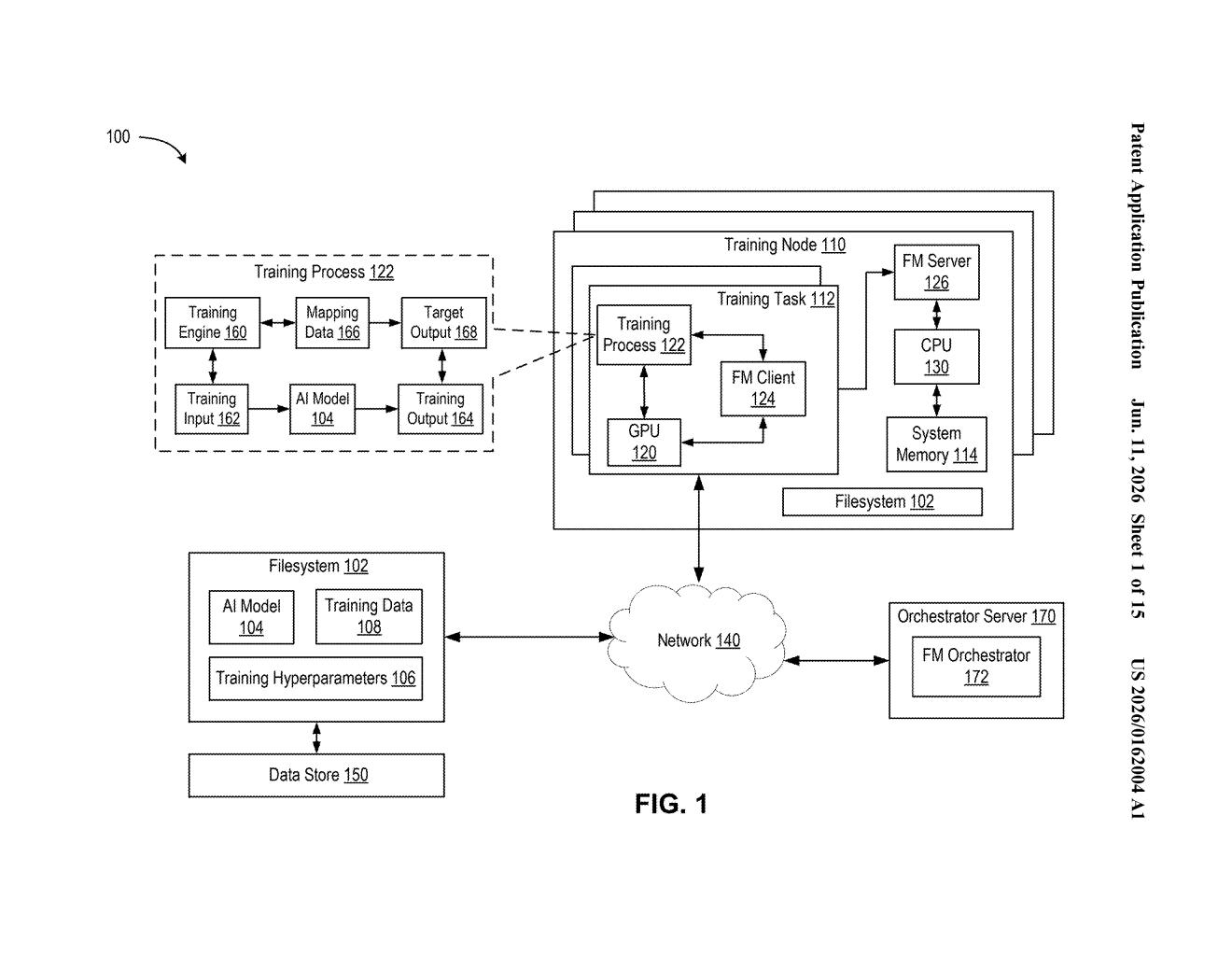
What Nvidia's crash-recovery AI training system actually does
Imagine you're playing a video game without manual saves, and the console randomly crashes. When you restart, you're back at the very beginning. That's roughly what happens when one server fails during a long AI training run — except the stakes are thousands of dollars of compute time, not a lost boss fight.
Nvidia's patent describes a system that watches all the servers involved in training an AI model. Each server sends a small "I'm done with this round" signal after completing its portion of the work. If any server goes silent, the system treats that as a crash and automatically rolls training back to the most recent clean snapshot — called a checkpoint — pulled from one of the healthy servers still in the cluster.
The key word here is automatically. Right now, engineers often have to manually notice a failure, diagnose it, and restart the job. Nvidia's approach turns that into a self-healing loop, which matters a lot when training runs can last days or weeks on expensive hardware.
How the fault-detection and checkpoint retrieval loop works
The patent describes a distributed AI training setup where many parallel training processes (PTPs) — essentially software workers running on separate machines — each handle a slice of the overall job simultaneously.
During normal operation, every process sends a reference signal after finishing each training iteration (a single pass through a batch of data). A coordinating system collects these signals. If the expected signal from any process fails to arrive, the system flags that iteration as faulty and treats the missing process as crashed or hung.
When a fault is detected, the system doesn't wait for a human to intervene. Instead, it:
- Identifies which processes are still healthy
- Pulls the most recent saved training state (model weights, optimizer values, and progress metadata) from a healthy process's memory
- Uses that state to restart the entire training run from the last clean point
The training state is kept in memory associated with each healthy process — meaning the system doesn't necessarily have to hit slow external storage to recover. This makes the rollback faster than traditional disk-based checkpointing, which can itself take minutes on large models.
What this means for the cost of training large AI models
Training frontier AI models is staggeringly expensive — a single run on a large cluster can cost millions of dollars. Hardware failures at that scale aren't rare; they're expected. The difference between detecting and recovering automatically in seconds versus having an engineer diagnose and restart a job manually can mean hours of wasted compute.
For Nvidia, whose GPUs are the dominant hardware for AI training, a patent like this signals investment in the full training stack, not just chips. If this kind of fault tolerance becomes standard in training frameworks, it also makes Nvidia's hardware look more reliable end-to-end — which matters to cloud providers and enterprises buying thousands of GPUs at a time.
This is genuinely useful infrastructure work. It won't make headlines the way a new GPU architecture does, but automatic fault recovery for distributed AI training is a real pain point with real dollar consequences. The in-memory checkpoint approach — avoiding slow disk reads during recovery — is the technically interesting bit, and worth watching as training clusters keep scaling up.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.