Google's New Patent Keeps AI Training Running Even When Machines Fail
Training a large AI model can take thousands of machines running in sync for weeks. When one machine fails, the whole run can grind to a halt — and Google has a patent for fixing that.
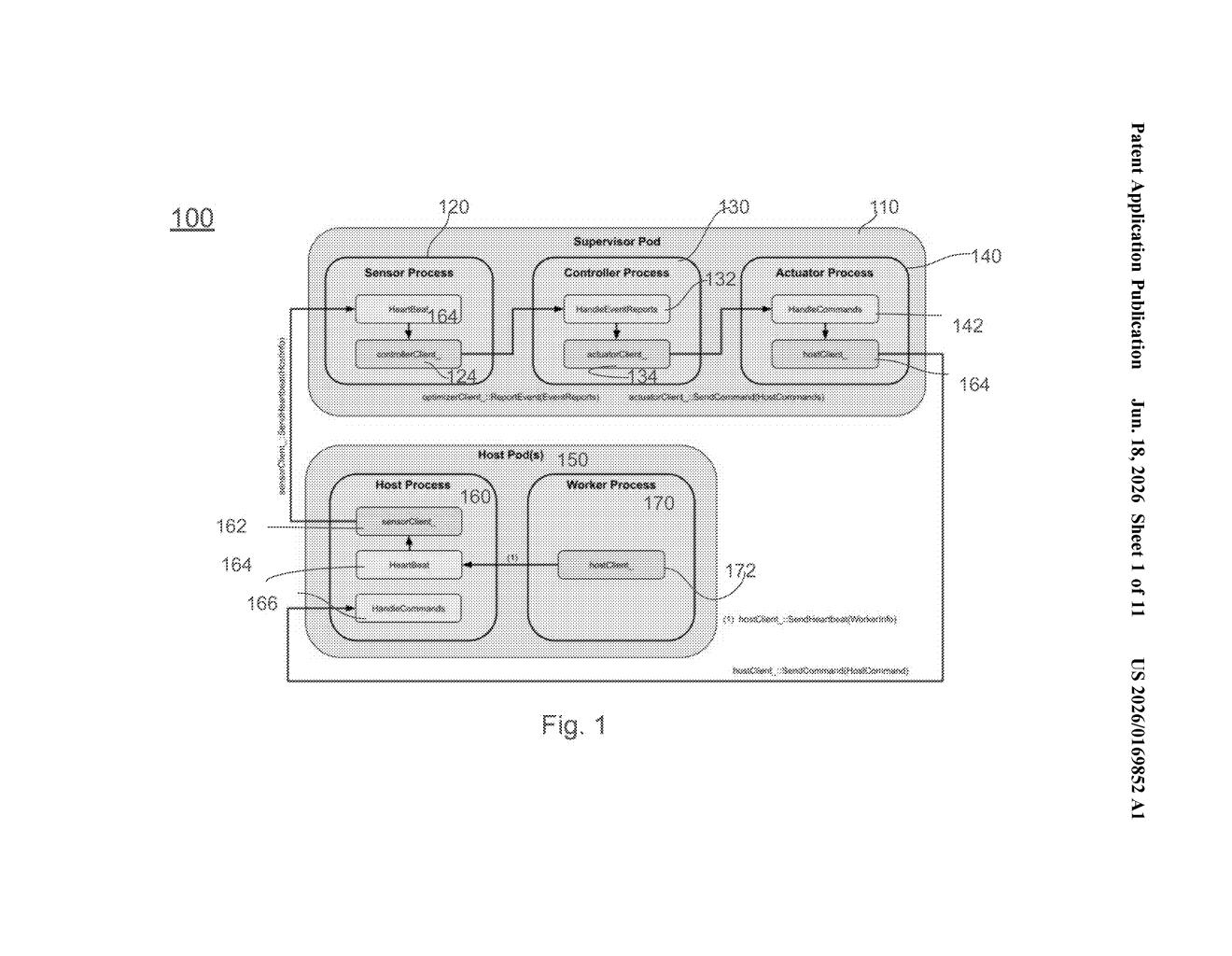
What Google's AI training crash-recovery system actually does
Imagine a factory assembly line where every worker has to stop the moment one person trips. That's roughly how training big AI models works today: when any one machine in a cluster fails, the entire job pauses, wastes time, and often restarts from scratch. The lost compute time is expensive — sometimes costing millions of dollars.
Google's patent describes a "holistic controller" — essentially a supervisor that watches every machine in a training cluster at once. When something goes wrong, the supervisor figures out exactly which machines are affected and tries to fix just those, letting the rest keep working. It picks from a menu of recovery options depending on how bad the failure is.
The goal is to maximize what Google calls "goodput" — the fraction of compute time that actually produces useful training progress, rather than being wasted on failures or restarts. Think of it as a measure of how much real work you get out of a very expensive machine fleet.
How the supervisor node picks the right fault response
The patent describes a distributed training framework built around a central supervisor node — a dedicated process that sends and receives heartbeat signals (regular, lightweight "I'm still alive" pings) from every processor in the training cluster.
When the supervisor detects an anomaly — a missed heartbeat, a slow response, or an error signal — it identifies exactly which processing units are affected and picks a response strategy tailored to the severity. The key design choice: unaffected machines keep running. Only the broken slice of the cluster gets paused or replaced.
The patent describes a "suite of resiliency mechanisms" available at multiple layers of the machine-learning stack. These likely range from simply retrying a failed operation, to hot-swapping in a spare machine, to checkpointing and rolling back just the affected portion of the training job. The controller selects whichever option causes the least disruption.
- Monitoring layer: heartbeat signals from every processing unit
- Detection layer: anomaly identification without human intervention
- Response layer: targeted, per-worker recovery without halting the whole job
What this means for the cost of training large AI models
Training frontier AI models requires thousands of GPUs or custom accelerators (like Google's own TPUs) running in tight coordination, often for weeks at a time. A single hardware failure that forces a full restart can waste days of compute worth tens of thousands of dollars. Systems that can absorb failures gracefully — without stopping the whole job — directly lower the cost of building large models.
For Google, this matters both internally and competitively. If its infrastructure wastes less time on crashes than a competitor's, it can train models faster and cheaper. It also points to where the bottleneck really is in modern AI development: not just chip speed, but the reliability of the enormous clusters those chips run in.
This is unglamorous but genuinely important infrastructure work. The race to train bigger AI models isn't just about buying more GPUs — it's about how efficiently you can use them at scale. A system that recovers gracefully from hardware failures, rather than restarting entire jobs, is the kind of operational advantage that compounds quietly over time. Worth tracking if you follow AI infrastructure.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.