Microsoft's New Patent Routes Your AI Prompts to Whichever Server Answers Fastest
Before your prompt even reaches an AI model, Microsoft wants a separate system to predict how long the answer will be — then use that prediction to decide which server should handle it, and when.
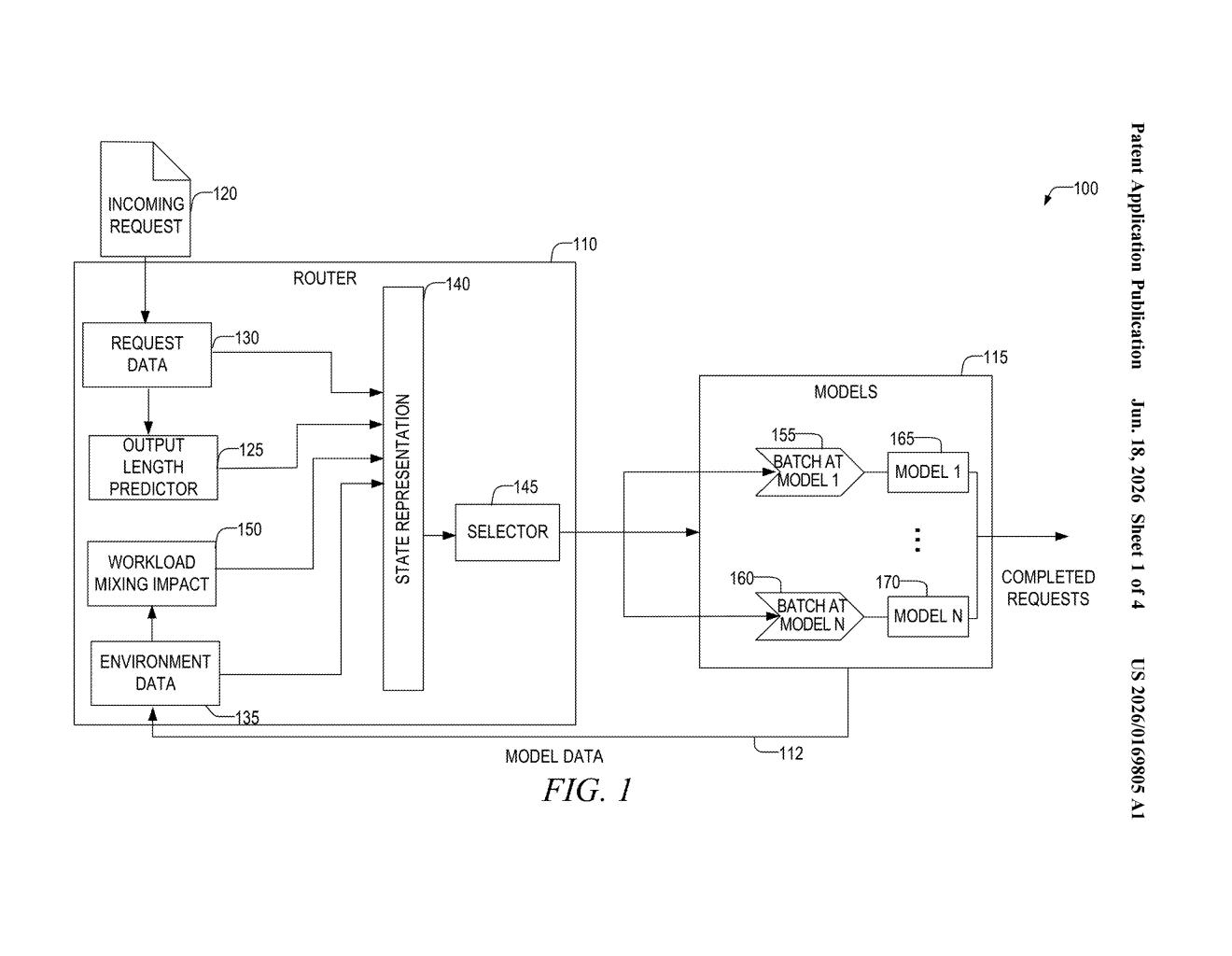
What Microsoft's AI traffic director actually does
Imagine a busy restaurant where some customers order a coffee (quick) and others order a five-course meal (slow). If the host seats everyone at the same table regardless, fast orders get stuck behind slow ones. Microsoft's patent describes a traffic director for AI services that tries to solve exactly that problem.
When you send a prompt to an AI, the system first estimates how long the response will be. It then checks which AI servers are busy, what kind of work they're already doing, and predicts how adding your request to each one would affect everyone's wait time. Based on all of that, it picks the best server — or, if conditions are bad enough, it waits a moment before sending your request at all.
The goal is to reduce two specific delays you might notice: the pause before the AI starts typing its first word, and the gaps between words as it generates the response. Both have real effects on how snappy AI tools feel to use.
How the router predicts response length before routing
The system is essentially a load balancer built specifically for generative AI workloads, which behave very differently from traditional web traffic.
Generative AI requests go through two distinct phases: a prompt phase (where the model reads your input) and a decode phase (where it generates each word of the reply, one token at a time). These two phases compete for the same hardware resources, so a server handling lots of long-output requests is a poor match for a short, quick one — and vice versa. The router tracks both the prompt and decode distributions (essentially, a snapshot of what each server is currently chewing on) for every running AI instance.
Before routing, a trained response-length predictor model estimates how many tokens (roughly, how many words) the answer to your specific prompt will require. That prediction, combined with each server's current state, feeds into a machine-learning routing model that outputs a probability score for each available server.
The key additions over a standard load balancer are:
- Predicting output length before the request is sent
- Modeling the interference between short and long tasks on the same server
- Optionally delaying routing if no server is in a favorable state
The metrics it's optimizing are TTFT (Time-To-First-Token — how long before the AI starts responding) and TBT (Time-Between-Tokens — how smoothly words flow once it starts).
What this means for AI services running at scale
For companies running AI services at scale — think Azure OpenAI, Copilot, or any enterprise chatbot — shaving even small amounts off response latency has a compounding effect across millions of requests per day. This kind of routing intelligence is the difference between an AI assistant that feels instant and one that noticeably lags.
For end users, you'd likely never see this system directly — it operates entirely in the background. But you'd feel it: faster first-word responses and smoother text generation in AI-powered tools. The decision to sometimes deliberately delay a request rather than send it to a bad server is the most interesting design choice here, and it reflects a real engineering tradeoff between queuing theory and user perception of speed.
This is unglamorous infrastructure work, but it's the kind of thing that separates production-grade AI platforms from research demos. The decision to predict response length *before* routing — rather than just balancing by queue depth — is a genuinely thoughtful design choice that reflects hard-won operational experience. Microsoft is almost certainly building this because they've watched naive load balancing hurt Copilot and Azure AI performance at scale.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.