Amazon Patents a System That Builds Animated Videos Straight From Plain Text
Amazon is patenting a pipeline that takes a plain-text request — like 'make a video about a dog chasing a ball in a park' — and produces a fully animated video, complete with moving characters, backgrounds, and audio, with no human animator in the loop.
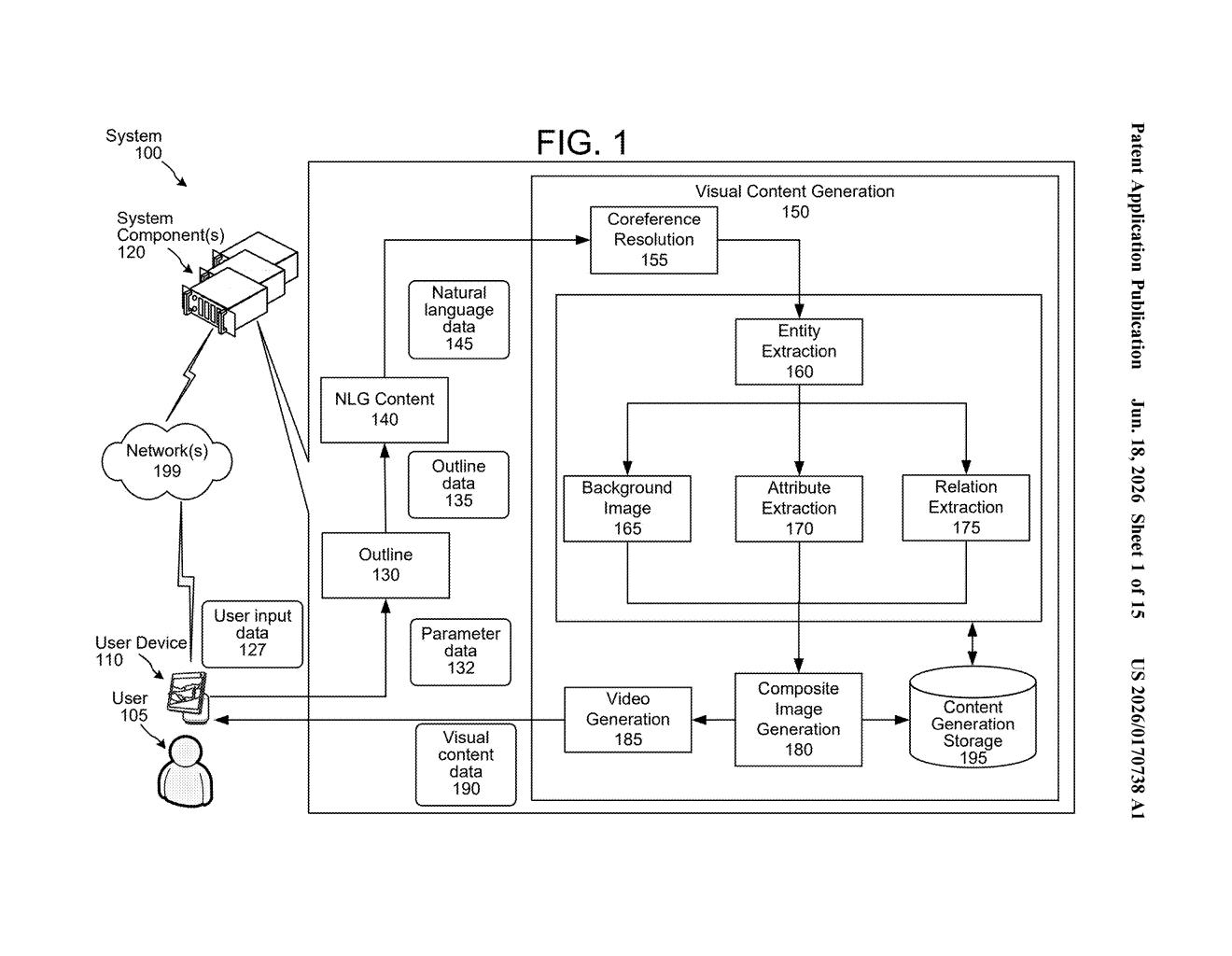
How Amazon's text-to-video pipeline actually works
Imagine typing a simple request — 'make a short video about a bear fishing in a mountain stream' — and getting back an actual animated clip with moving characters, appropriate background scenery, and narration. That's the core idea here.
Amazon's system doesn't just find stock footage. It reads your request, fills in missing details on its own (like what the background should look like, or how characters relate to each other in the scene), and then generates images, animation, and audio from scratch.
The system can also stitch multiple generated clips together into one composite video. So if you've already made a video about that bear, and you ask for a follow-up scene, the system can blend the new clip with footage from the first one — keeping your story consistent across segments.
How the ML system goes from outline to animated clip
The patent describes a multi-stage pipeline, where a text request passes through several processing steps before a video is produced.
- Outline generation: When you submit a request, the system first builds an 'outline' — a structured plan that adds details you didn't specify. If you asked for 'a video about a birthday party,' the system infers things like the number of characters, the setting, and the mood.
- Natural language expansion: The outline is then expanded into full descriptive text — essentially a written scene description with named characters, their positions, and what they're doing.
- Entity extraction and image generation: The system identifies the specific objects and characters ('entities') in the text, resolves any ambiguous references (like figuring out which 'it' refers to), extracts their visual attributes, and generates image data for each one, including a background scene.
- Video and audio assembly: Images are animated — characters move — and audio is layered in to produce the final clip.
Critically, the system also handles composite video: it can pull segments from a previously generated video and merge them with new footage, so multi-part stories stay visually coherent.
What this means for AI-generated video at Amazon scale
For Amazon, a patent like this fits squarely into its push to give AI assistants — like Alexa — the ability to produce rich, visual content on demand, not just spoken answers. A parent asking Alexa to 'tell my kids a bedtime story' could eventually get an animated short instead of a voice-only response.
More broadly, this is part of a broader race among big tech companies to automate video production. If the system works reliably, it could dramatically lower the cost of creating short-form animated content — which has implications for advertising, education, and entertainment products that Amazon already operates across AWS, Prime Video, and Alexa.
This is a genuinely interesting patent because it isn't just text-to-image — it tackles the harder problem of consistent, multi-scene video with named characters and spatial logic. The composite video feature, which lets you blend new footage with previously generated clips, is the most technically ambitious piece and the one most likely to matter if this ever ships in a real product.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.