Nvidia Patents an AI System That Recreates Voices From Audio Recordings
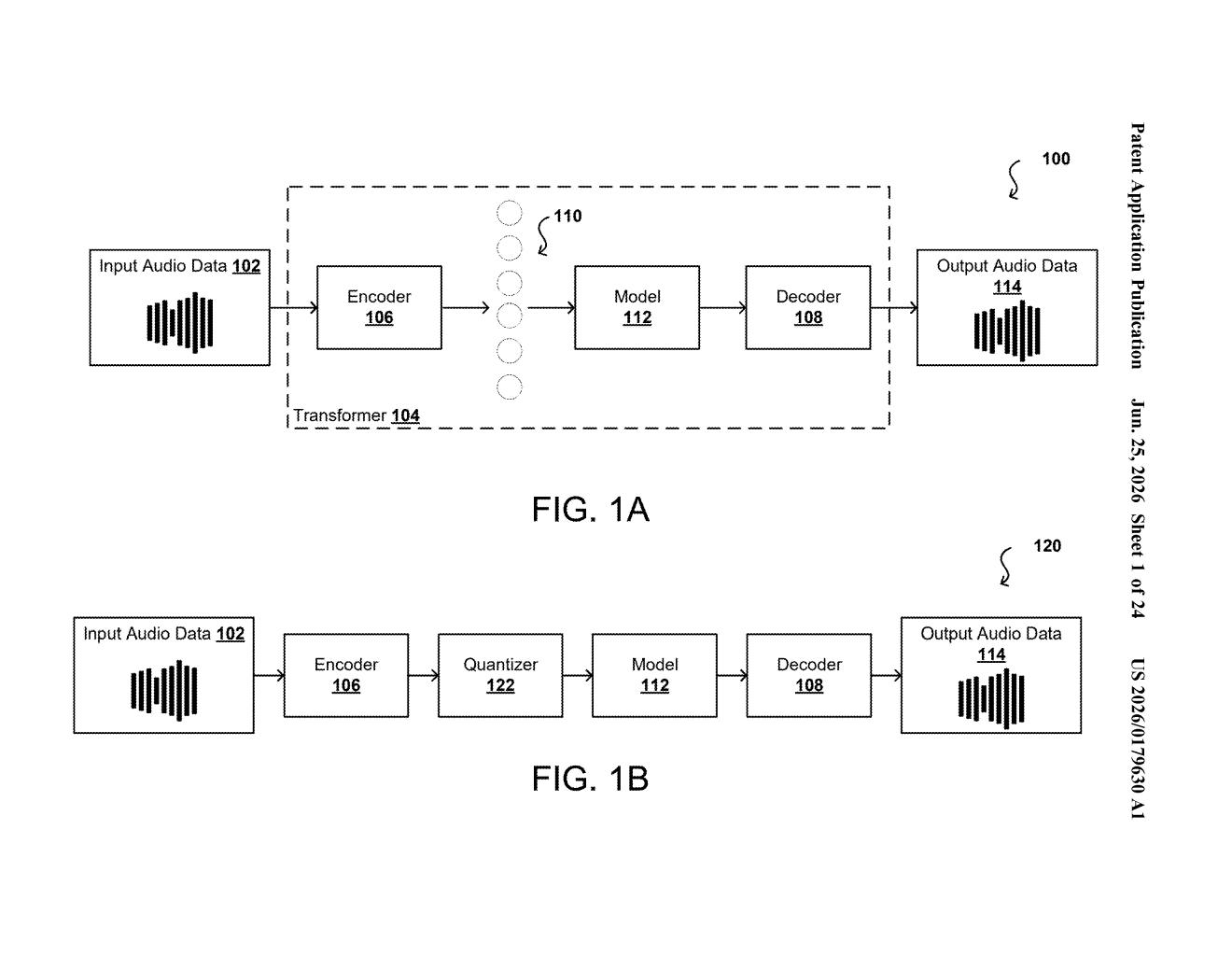
Nvidia is patenting a way to teach AI systems to think about a person's voice in three separate layers at once: who is speaking, what they're saying, and how the individual sounds are shaped. That separation is the key to building voice AI that sounds genuinely natural.
How Nvidia's voice AI breaks down and rebuilds speech
Imagine asking an AI assistant to read something aloud in your voice. Getting that right isn't just about picking the right words. The AI needs to understand who you are as a speaker, the rhythm and melody of your sentences, and the precise sounds that make up each syllable. Most systems blur those things together, which is why AI voices often sound flat or slightly off.
Nvidia's patent describes a system that keeps those three layers separate throughout the entire process. One part of the system captures your identity as a speaker. Another tracks the phrases and sentences you're producing. A third handles the fine-grained sounds inside each word. Each layer gets compressed into a compact set of tokens (small chunks of data), and the final audio is rebuilt from all of them together.
The result is a pipeline designed specifically for the kind of high-quality, flexible voice generation that powers AI assistants, text-to-speech tools, and voice cloning applications. Nvidia is building this as infrastructure for AI systems, not as a consumer product on its own.
How the three-layer token pipeline encodes a voice
The patent describes a processor architecture built around three tiers of audio representation, each encoded separately before being combined to generate output audio.
- First representation (speaker identity): The system extracts a compact profile of who is speaking. Think of this as a fingerprint for a person's voice, capturing timbre, accent, and general vocal character.
- Second representation (utterances): Built on top of the speaker identity layer, this captures the broader shape of speech, including sentence-level patterns and prosody (the rise and fall of pitch and rhythm across a phrase).
- Third representation (phonemes): Phonemes are the smallest individual sound units in speech, like the "k" in "cat" or the "sh" in "ship". This layer tracks the fine detail of each sound within the utterances.
Each of those representations gets compressed into tokens (a set of compact numerical codes, similar to how large language models break text into word fragments). The first set of tokens covers the utterance-level structure; the second set covers the phoneme-level detail, and it's conditioned on all three representations so the sounds remain consistent with both the sentence context and the speaker's identity.
A decoder then takes both token sets and reconstructs the final audio. The architecture is designed to slot into existing encoder/decoder AI pipelines at inference time, meaning it can run during live generation rather than just during training.
What this means for AI voice and speech synthesis tools
Neural audio codecs sit at the foundation of almost every serious AI voice product: text-to-speech engines, real-time translation, voice cloning, and AI assistants. The quality ceiling of those products is largely determined by how well the underlying codec separates and preserves the different elements of speech. By building a three-layer system where speaker identity, sentence structure, and phoneme detail are handled independently, Nvidia is targeting a known weak point in current architectures.
For you as an end user, this kind of work is what eventually makes AI voices sound less like a robot reading from a script and more like a real person having a conversation. Nvidia's position as a chip and AI infrastructure company means this codec is likely aimed at developers and AI model builders who use Nvidia hardware, rather than a product you'd interact with directly.
This is solid, substantive AI audio infrastructure work. The three-layer separation of speaker identity, utterance, and phoneme is a meaningful architectural choice, not just incremental tweaking. Nvidia filing this under its own name signals the company is building out proprietary AI audio tooling to pair with its GPU and inference platforms, which is a real strategic move worth tracking.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.