AMD Patent Stores AI Model Data Efficiently to Speed Up Processing
Running a large AI model means constantly shuffling enormous amounts of data between storage, memory, and the chip doing the actual work. AMD's new patent describes a way to let the AI chip handle that data pipeline itself, skipping the CPU entirely.
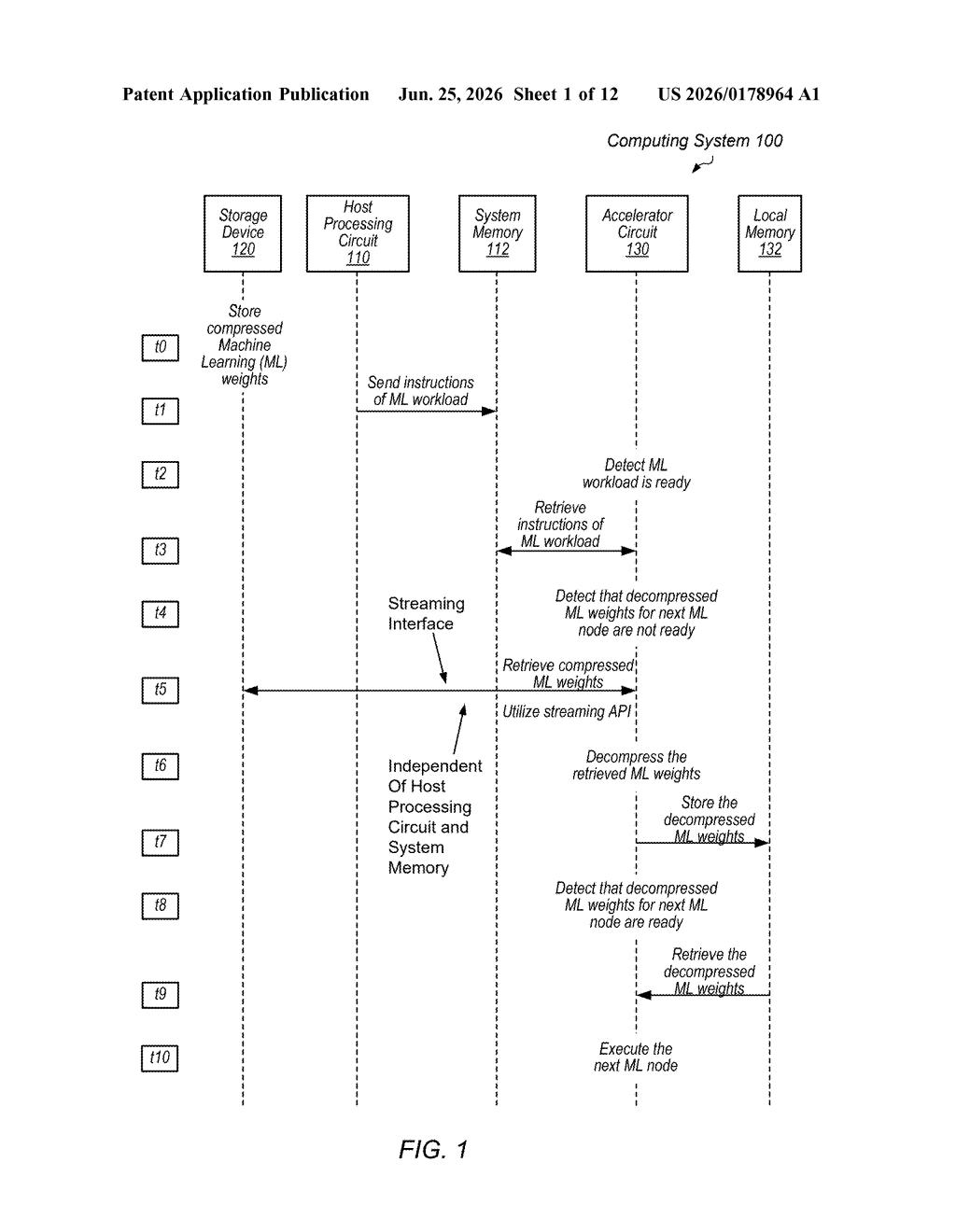
How AMD wants to feed AI chips without the CPU bottleneck
Imagine you're cooking a huge meal, but every time you need a new ingredient, you have to ask a single assistant to walk to the pantry, get it, and bring it to you. That assistant becomes the bottleneck. AMD's patent is the equivalent of giving the chef direct access to the pantry.
When an AI model runs, it depends on billions of stored values called weights that tell it how to behave. Normally, the main processor (the CPU) has to orchestrate fetching those weights into memory before the AI chip can use them. AMD's approach lets the AI accelerator chip pull the weights directly from storage on its own, in compressed form, and unpack them locally.
The result is that the CPU is no longer a traffic cop between storage and the AI chip. For systems running large AI models continuously, that could mean faster responses and less memory strain, since you only load what you need, when you need it.
How the accelerator fetches, decompresses, and runs weights on its own
The patent describes an accelerator circuit (think: AMD's GPU or a dedicated AI chip) that takes on the job of managing its own data supply. Here's the flow:
- The host CPU translates an AI application's instructions into commands the accelerator understands, then largely steps aside.
- The accelerator uses a streaming API (a direct software channel to storage, bypassing the CPU and system RAM) to fetch only the model weights it needs for the next set of calculations.
- Those weights arrive in compressed form, reducing how much data has to travel across the system bus.
- The accelerator decompresses them on-chip and executes the relevant part of the AI model immediately.
The system uses a computational graph (a map of the AI model's operations in execution order) to predict which weights will be needed next, allowing it to preload them before they're actually required.
This design targets inference workloads, meaning AI models that are already trained and just running predictions, which is the most common real-world scenario for deployed AI today.
What this means for AI inference speed and memory costs
The size of AI models has grown faster than the memory inside most chips. Keeping an entire model in local memory is increasingly impractical, so systems need to stream data in as they go. AMD's patent addresses that directly by making the accelerator the active agent in that process rather than a passive recipient waiting on the CPU.
For data centers running AI inference at scale, this kind of architecture could reduce the cost of high-bandwidth memory by relying more on cheaper storage, while keeping the chip fed at the speed it needs. For AMD, which competes with Nvidia for AI chip market share, demonstrating this kind of system-level efficiency is a meaningful part of the argument for choosing their hardware.
This is genuinely useful infrastructure work, not a flashy AI feature. The core problem AMD is addressing, getting large model data to the chip fast enough without blowing your memory budget, is one of the real limiting factors in deploying AI today. Whether this specific patent becomes a shipping product feature or just part of a broader driver stack, the direction is correct and the problem is real.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.