AMD Patents a Chip That Picks Its Own Math Engine Based on AI Number Formats
AI models chew through matrix math constantly, and the 'precision' of those numbers, how many decimal places you keep, is a major lever on both speed and accuracy. AMD's new patent describes a chip circuit that figures out which math engine to use on its own, without the programmer having to manually route each calculation.
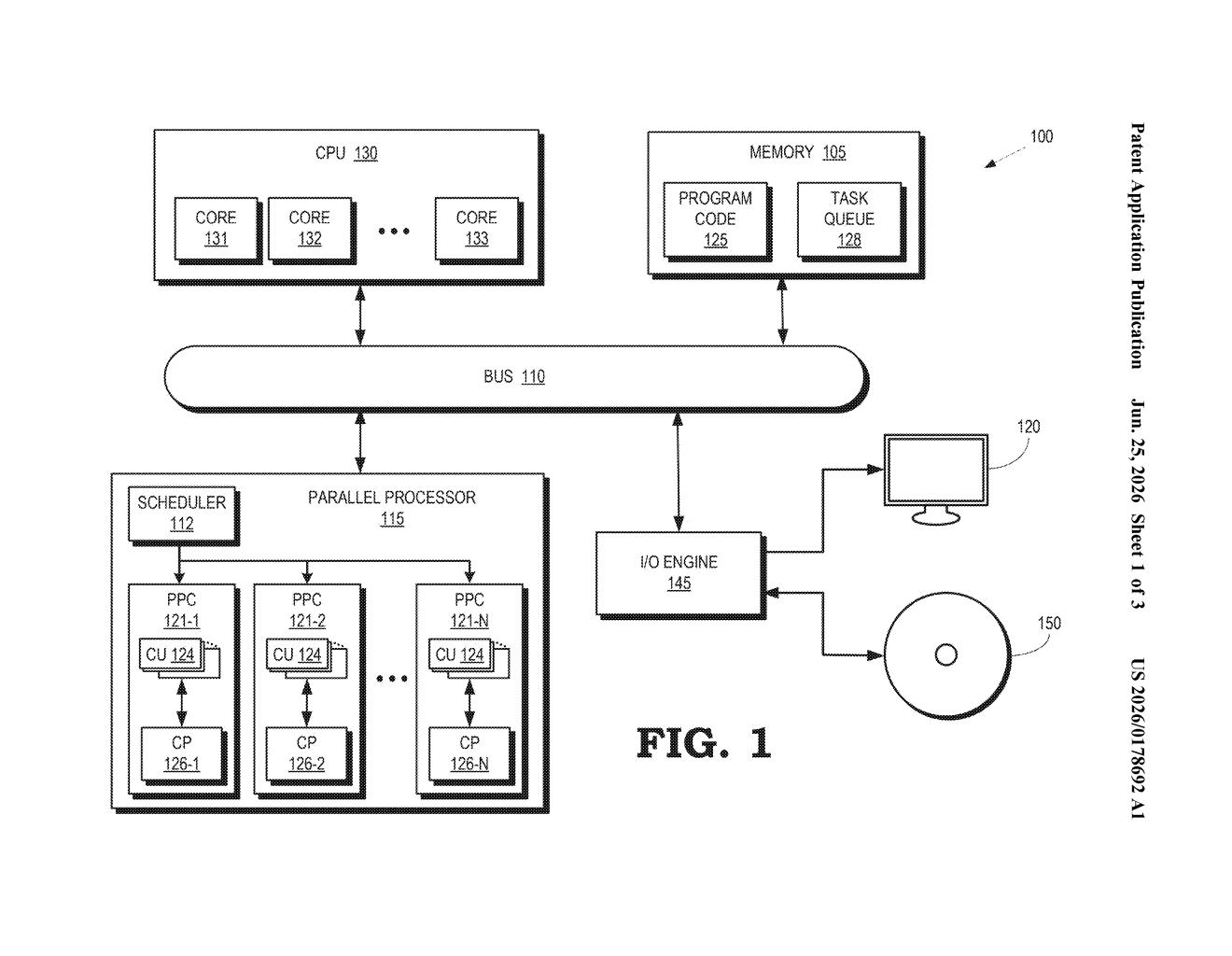
What AMD's auto-precision matrix hardware actually does
Imagine a kitchen where some recipes need precise measurements to the milliliter and others only need a rough cup estimate. Using the fine-grain scale for every single step wastes time, but mixing them up manually is error-prone. AI chips face the exact same trade-off with numbers.
When your GPU runs an AI model, it's constantly multiplying giant tables of numbers called matrices. Those numbers can be stored at different levels of precision: high precision keeps more decimal places and is more accurate but slower; low precision is faster and uses less power but rounds off some detail. Typically, a programmer has to manually tell the chip which mode to use for each operation.
AMD's patent describes a circuit that reads what precision format the incoming matrices are in and automatically routes the math to the right internal engine. The programmer just sends the matrices over; the hardware handles the rest. That's a meaningful quality-of-life shift for the people writing AI software, and it could make the chip more efficient by always using the leanest appropriate engine.
How the circuit selects a multiplication chain at runtime
The patent covers a parallel processor (the kind found in GPUs and AI accelerators) that contains multiple distinct multiplication chains, each optimized for a specific numerical format.
A multiplication chain here means a dedicated hardware pipeline for performing matrix multiplication in a particular precision format. Common precision formats in AI include FP32 (32-bit floating point, high accuracy), FP16 (16-bit, faster and smaller), BF16 (a Google-originated 16-bit format popular in AI training), and INT8 (8-bit integers, very fast for inference). Each format has different hardware requirements, so rather than one general-purpose unit, AMD's design provides a separate chain per format.
The key claim is a selection circuit that inspects the precision of the two input matrices and automatically routes the operation to the matching chain. The system can identify format either from explicit parameters attached to the instruction or from the memory addresses where the matrices are stored.
- Multiple hardware chains, one per supported precision format
- Automatic format detection from instruction parameters or memory location
- No manual chain selection required from the programmer's side
The result is a chip that can handle mixed-precision workloads (where different layers of an AI model use different number formats) without software overhead for routing decisions.
What this means for AI chip efficiency and programmer workload
Modern AI models almost never run at a single precision level throughout. Training might use FP32 for stability while inference layers drop to INT8 for speed. Today, managing those switches often falls on the software stack or the programmer, adding complexity and potential for mistakes.
AMD's approach bakes the routing logic into silicon, which means the decision happens at hardware speed with no software detour. For you as an end user, this could show up as faster AI inference on AMD-powered hardware, whether that's a data-center GPU or eventually a laptop chip. For developers building AI frameworks, it simplifies the code they need to write to squeeze performance out of AMD hardware.
This is firmly an infrastructure patent, not a headline product feature, but it addresses a real friction point in AI chip programming. The trend toward mixed-precision AI workloads is well established, and putting automatic format routing in hardware rather than software is a sensible architectural direction. Whether AMD ships exactly this circuit or uses the patent defensively, it signals that the company is paying close attention to the programmability gap between its hardware and what AI developers actually need.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.