Apple Patents a System That Builds 3D Models of Real Objects Using Depth and Image Data
Apple is patenting a way to scan a physical object — say, a chair — and automatically reconstruct it as a clean, part-by-part 3D model. The trick is combining two very different kinds of sensor data to get both the geometry and the fine details right.
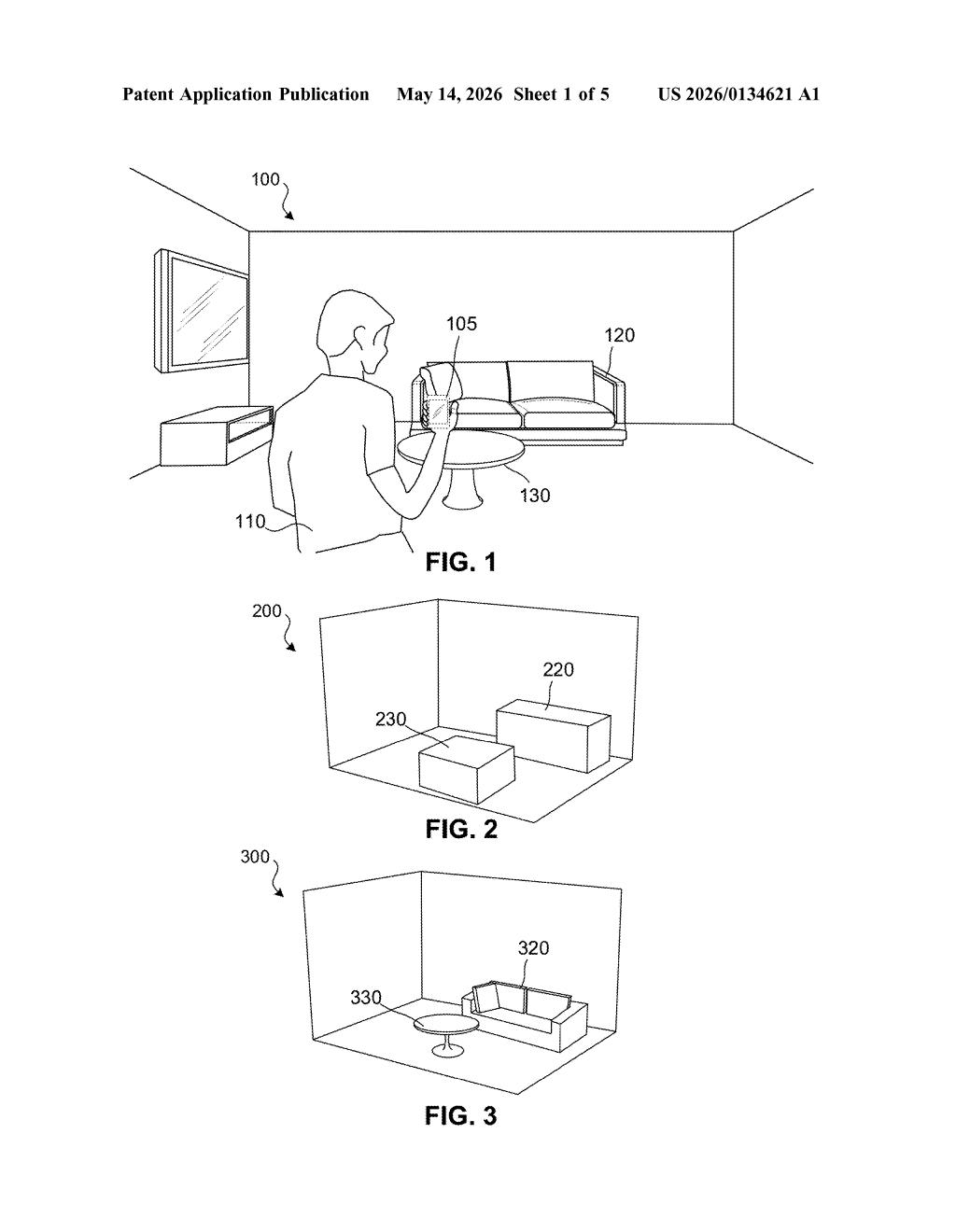
What Apple's part-aware 3D scanning actually does
Imagine you point your iPhone or Vision Pro at a chair in your living room, and it doesn't just take a photo — it builds an accurate 3D model of that chair, broken down into legs, seat, and backrest, each piece correctly shaped and positioned.
That's essentially what this Apple patent describes. It uses depth sensor data (a 3D point cloud — basically a cloud of millions of measured dots in space) to figure out where each part of an object is and how big it is. Then it uses a regular 2D camera image to recognize finer details, like whether chair legs are star-shaped, straight, or crossed.
By combining those two sources, the system can generate a compact but accurate 3D model of the object — not a raw mesh of millions of triangles, but a smarter, structured representation built part by part. That kind of model is much easier to work with in augmented reality or room-planning apps.
How Apple fuses point clouds with 2D image attributes
The patent describes a pipeline with three main stages that run on a device with a processor (think iPhone, iPad, or Apple Vision Pro).
- 3D point cloud input → part segmentation and bounding boxes: The depth sensor produces a point cloud — a spatial map made of millions of 3D coordinate dots. The system segments that cloud into individual parts of the object (e.g., the seat vs. the legs of a chair) and fits a 3D bounding box (an invisible box that snugly wraps each part) to capture its position, size, and orientation.
- 2D image input → attribute recognition: A standard camera image of the same scene is analyzed to identify part-specific attributes — qualitative descriptors like the shape type of chair legs (star-shaped, straight, or crossed). These are things that a point cloud alone might not capture cleanly due to noise or low resolution.
- Fused 3D representation: The geometry from the point cloud (where things are, how big) and the attributes from the image (what shape or style) are combined to generate a structured 3D model. Each part gets a shape representation that fits inside its bounding box and reflects its recognized attribute.
The result is a relatively lightweight, semantically meaningful model rather than a raw photogrammetric mesh — which makes it far more useful for downstream tasks like AR placement, furniture recognition, or scene understanding.
What this means for Apple's AR and spatial computing push
For Apple, accurate real-world 3D reconstruction is core infrastructure for spatial computing on Vision Pro and for AR features on iPhone and iPad. If your device can scan a room and build clean, part-aware 3D models of the furniture in it, you get much more convincing AR overlays, better object interaction, and smarter scene understanding — things like knowing a chair has wheels, or that a table has a glass top.
This also ties into the broader trend of semantic scene understanding: moving beyond raw geometry to models that know what objects are and what their parts do. That's the foundation for features like room planning in the Home app, virtual try-before-you-buy furniture placement, or future robotics applications where a device needs to interact with real objects intelligently.
This is solid, unglamorous computer vision infrastructure — the kind of foundational work that quietly enables the demos Apple loves to show on stage. The dual-modality approach (point cloud for geometry, 2D image for semantics) is a well-established research pattern, but patenting it in this specific configuration signals Apple is building a proprietary pipeline for on-device spatial understanding. Worth watching if you follow Vision Pro or ARKit development.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.