Microsoft Patents a Smarter Auto-Tuning System for Large-Scale Data Clustering
Clustering millions of data points sounds simple until you realize the whole algorithm breaks if you pick the wrong radius parameter — and right now, most teams pick it by hand. Microsoft's new patent tries to automate that guesswork out of existence.
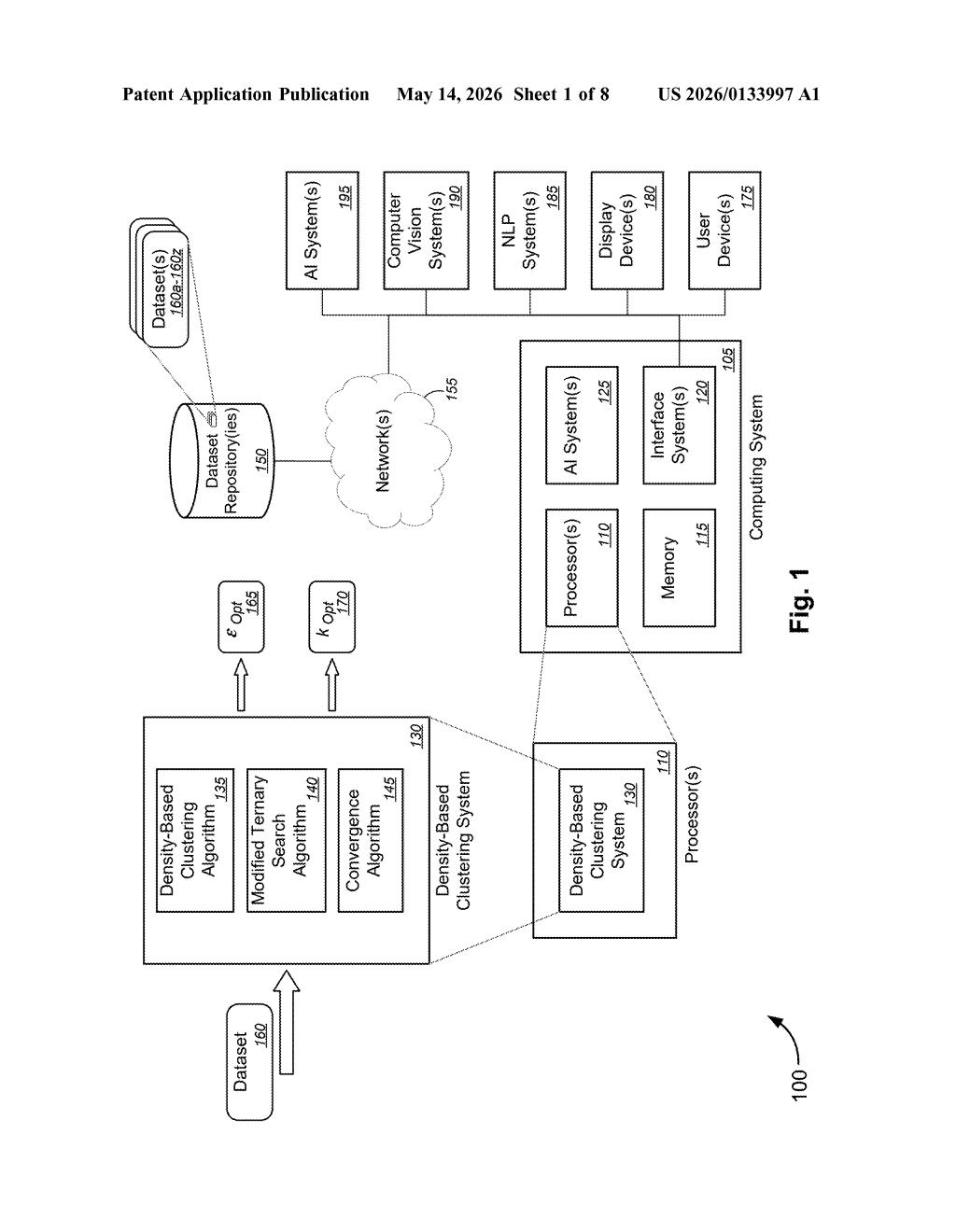
What Microsoft's auto-tuning clustering system actually does
Imagine you're trying to group millions of customer records, sensor readings, or document embeddings into meaningful clusters — like "these users behave similarly" or "these events are related." The most popular algorithms for doing that have a critical dial you have to set manually: how close two points need to be before they're considered neighbors. Pick the wrong value and your clusters are garbage.
Microsoft's patent describes a system that finds the optimal neighborhood radius automatically, even across very large datasets. Instead of brute-forcing every possible value, it uses a clever search strategy that narrows in on the best setting quickly — even when the dataset is too big to process all at once, so it works on a sample first.
The system also smartly handles the tricky relationship between your sample size and the right radius value — if you only look at 10% of your data, the right radius is different than if you look at 100%. Microsoft's approach accounts for that shift automatically, making the whole pipeline more hands-off.
How the modified ternary search finds the optimal radius
The patent targets density-based clustering — algorithms like DBSCAN that group data points by how densely packed they are in space, rather than by distance to a centroid. The critical tuning knob in these algorithms is epsilon (ε), the neighborhood radius: the maximum distance between two points for one to be considered a neighbor of the other. Getting this wrong produces either one giant blob or thousands of noise points.
Microsoft's system automates ε selection using a modified ternary search (a divide-and-conquer optimization technique that works on functions with a single peak or valley — called unimodal functions). The key insight is that the number of clusters produced by varying ε is near-unimodal — it rises, peaks, then falls — which makes ternary search a natural fit, even if the function isn't perfectly smooth.
The search operates within an automatically computed upper and lower bound:
- Upper bound: derived from the relationship between sampling rate and ε — as you sample less data, the right ε gets larger, so the system corrects for this.
- Lower bound: found via a secondary ternary search that treats the number of clusters as the input variable instead of ε directly, anchoring the search space from below.
The result is an optimal ε value (and corresponding cluster count) returned without human intervention, even on sampled subsets of very large datasets.
What this means for Microsoft's AI and data analytics stack
Manual hyperparameter tuning is one of the most tedious and error-prone parts of any data science pipeline. For enterprise customers running Azure Machine Learning, Fabric, or Synapse Analytics, a system that auto-configures clustering at scale means faster iteration and fewer specialist hours wasted on parameter sweeps. This is the kind of unglamorous infrastructure work that quietly makes cloud ML platforms stickier.
There's also a scalability angle worth noting: density-based clustering is widely used in anomaly detection, document grouping, and computer vision preprocessing — all workloads Microsoft's own AI systems (referenced in the patent's architecture diagram) depend on. A robust, automated solution here could trickle into Copilot-adjacent features where clustering happens behind the scenes without you ever seeing it.
This is solidly useful engineering rather than a flashy AI breakthrough. Auto-tuning DBSCAN's epsilon parameter is a real pain point that data scientists hit constantly, and Microsoft's ternary-search approach is an elegant solution to a genuinely annoying problem. It won't make headlines at Build, but it's the kind of patent that quietly improves the quality of every downstream ML feature built on top of it.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.