Microsoft Patents a System That Translates Classic ML Models Into Neural Networks
Most companies have years of traditional machine learning models — decision trees, gradient boosters, scikit-learn pipelines — that can't easily tap into modern deep learning tricks. Microsoft's patent describes a system that automatically converts those classic models into neural networks, without a full rewrite.
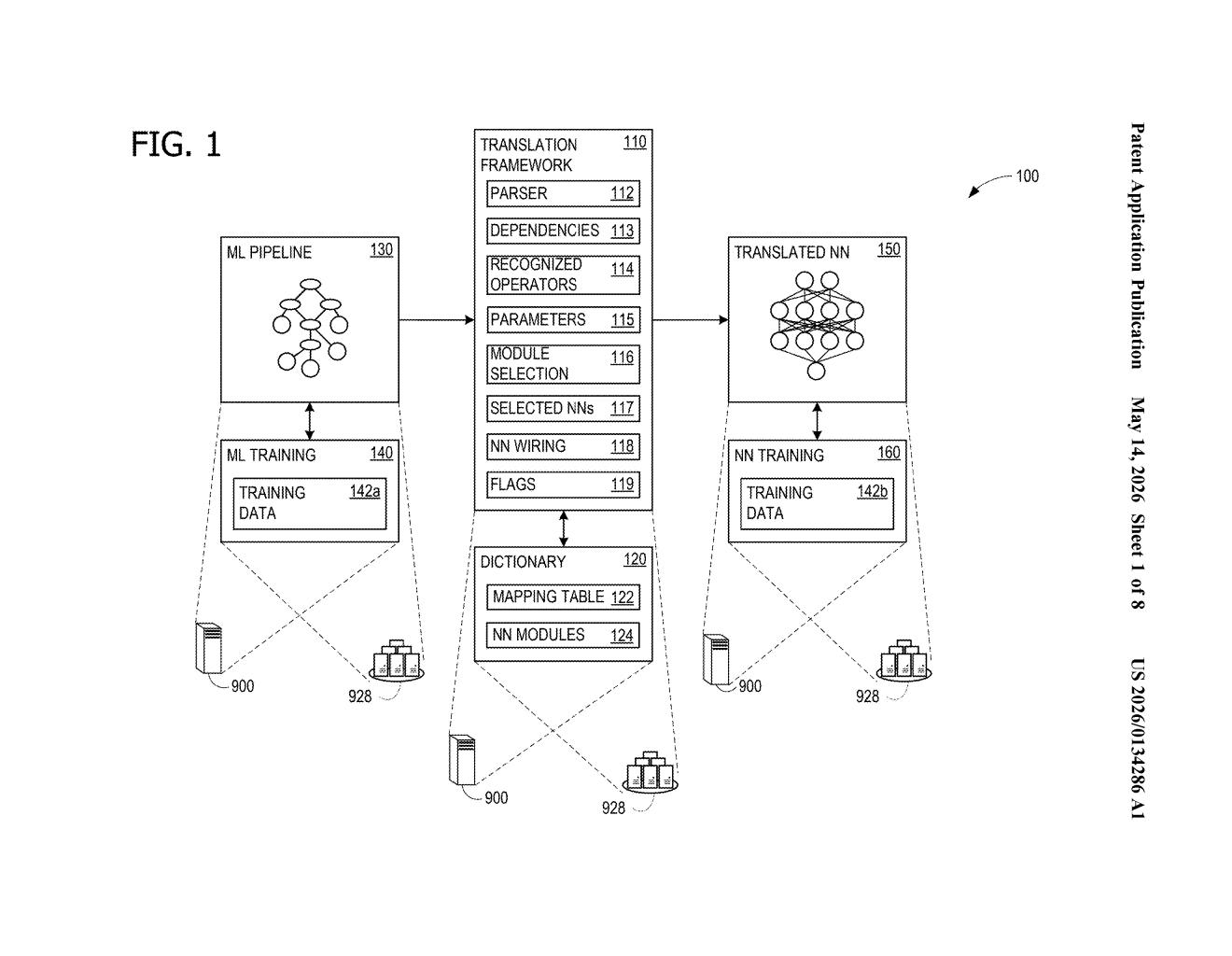
How Microsoft rewires old ML pipelines as neural nets
Imagine you've built a solid machine learning pipeline over several years — maybe it predicts customer churn or flags fraud — using classic tools like random forests or linear models. It works, but it can't be fine-tuned end-to-end the way modern deep learning models can. That's the gap this patent is trying to close.
Microsoft's system acts like a translator. It reads your existing ML pipeline, identifies each step (called an operator), looks them up in a kind of conversion dictionary, and replaces them with equivalent neural network building blocks. The whole thing gets rewired to preserve the same logical flow as your original model.
Once translated, the new neural network version of your model can be fine-tuned using standard deep learning techniques like backpropagation — the process of nudging a neural network's settings based on errors. Steps that can't be meaningfully translated are flagged and left connected as inputs, so nothing is silently dropped.
How the translation dictionary maps ML operators to NN modules
The patent describes a pipeline translation framework with a few key moving parts:
- Operator recognition: The system scans an ML pipeline and identifies which steps (operators) it knows how to convert — things like scalers, encoders, or tree-based estimators.
- Translation dictionary: Each recognized operator maps to a corresponding neural network module. Think of it like a lookup table that says "a StandardScaler becomes a BatchNorm layer."
- Dependency wiring: The system traces which operators feed into which, then connects the NN modules in the same order to preserve data flow.
- Trainability flags: Some operators have learnable parameters (like weights in a linear model); others don't (like a fixed binarizer). The system tags each translated module accordingly so downstream training knows what to update.
The system also handles partial translation — if early pipeline steps can't be converted, the translated neural network simply accepts their outputs as inputs. This keeps the system practical for messy real-world pipelines that mix translatable and non-translatable components.
After translation, the resulting NN can be fine-tuned end-to-end using backpropagation (the standard algorithm for training neural networks by propagating error signals backward through the network). This is the key payoff: your old model gains the ability to keep learning.
What this means for legacy ML codebases and AI modernization
For enterprise teams sitting on large inventories of scikit-learn, Spark ML, or similar classic pipelines, a tool like this could dramatically lower the cost of modernization. Instead of rebuilding models from scratch to use transfer learning or neural fine-tuning, you could slot your existing logic into a neural framework and start improving it immediately.
This also fits squarely into Microsoft's Azure ML and Fabric strategy — giving enterprise customers a smoother on-ramp to deep learning without forcing them to abandon prior investments. It's less about raw AI capability and more about reducing the friction that keeps organizations stuck on older approaches.
This is unglamorous but genuinely useful infrastructure work. The problem it solves — 'how do I modernize my ML pipeline without throwing it away' — is one of the most common headaches in enterprise AI. If Microsoft ships this inside Azure ML or as part of an AutoML workflow, it could quietly become one of the more practical AI tools they offer.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.