Nvidia Patents an API for Fine-Grained GPU NUMA Memory Control
On a server with dozens of CPUs and GPUs, memory location is everything — the wrong node can quietly tank performance. Nvidia is patenting an API that lets software explicitly tell a GPU exactly which memory node to use.
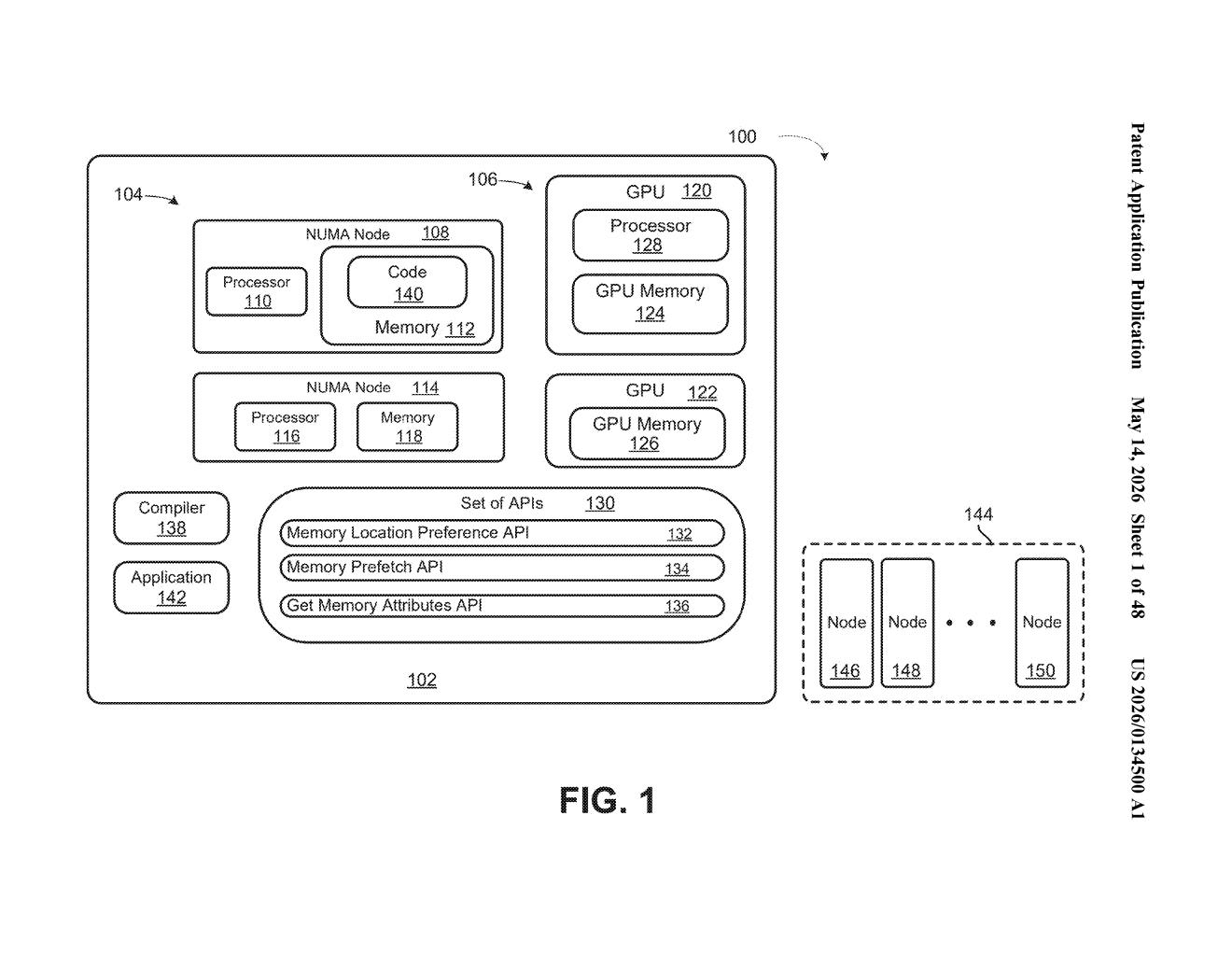
What Nvidia's GPU NUMA memory API actually does
Imagine a giant server rack with eight GPUs and 96 CPU cores spread across multiple processor chips. Not all memory is equally close to all processors — some RAM is physically wired closer to certain chips, so accessing it is faster. This architecture is called NUMA (Non-Uniform Memory Access), and mismanaging it is one of the sneakiest performance killers in high-performance computing.
Right now, developers often have limited control over which memory 'neighborhood' a GPU ends up using. Nvidia's patent describes an API call — essentially a software instruction — that lets a program explicitly say: 'allocate this block of virtual memory addresses on this specific NUMA node.' The circuitry on the processor honors that instruction and routes memory accordingly.
For you as a developer, this means less guesswork and fewer hidden bottlenecks when running large AI training jobs or scientific simulations across multi-GPU systems.
How the API call maps virtual memory to a NUMA node
The patent describes a processor circuit that responds to a specific API call by binding a range of virtual memory addresses (the addresses a program sees) to a designated NUMA node (a physical cluster of memory and processors that share a fast local bus).
The key mechanism is one or more parameters inside the API call that carry an explicit indication — essentially a label — specifying which NUMA node should serve as the storage location for that memory range. The circuitry reads those parameters and configures the memory mapping accordingly.
- Virtual-to-physical mapping: The API bridges the gap between the logical address a GPU program uses and the actual physical RAM on a specific NUMA node.
- Parameter-driven control: The node selection isn't inferred by the hardware — it's explicitly commanded by the software caller, giving developers deterministic placement.
- GPU-aware allocation: The system is specifically designed for GPUs, meaning the NUMA node in question can be GPU-local memory, not just CPU-side RAM.
The practical effect is that a GPU workload can be pinned to its nearest memory, avoiding the latency penalty of crossing NUMA interconnects (the slower links between different processor-memory clusters).
What this means for large-scale AI and HPC clusters
In AI training clusters and HPC environments, memory bandwidth and latency are constant bottlenecks. When a GPU accidentally accesses memory on a remote NUMA node, you pay a latency tax on every single memory operation — and at the scale of billion-parameter model training, those taxes compound fast. An explicit API for NUMA control gives framework developers (think CUDA libraries, PyTorch, JAX) a reliable primitive to build smarter memory schedulers on top of.
This also signals that Nvidia is pushing NUMA awareness deeper into its GPU software stack. As multi-GPU and multi-host configurations become the norm for AI infrastructure, fine-grained memory topology control stops being a niche HPC concern and becomes a mainstream developer need. If this API lands in a future CUDA release, it could meaningfully simplify how data-center-scale jobs manage memory affinity.
This is a quiet but genuinely useful piece of infrastructure work — not flashy, but the kind of low-level primitive that unlocks real performance gains in exactly the workloads Nvidia cares most about right now. If you're building or tuning large AI training jobs on multi-GPU nodes, an explicit NUMA-binding API is exactly the kind of control you wish you had.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.