Google Patents an AI System That Builds Videos Segment by Segment from Text
Most AI video generators spit out a fixed-length clip and stop. Google's new patent describes a system that keeps going — stitching new video segments onto the end, guided by a fresh text prompt each time, for as long as you want.
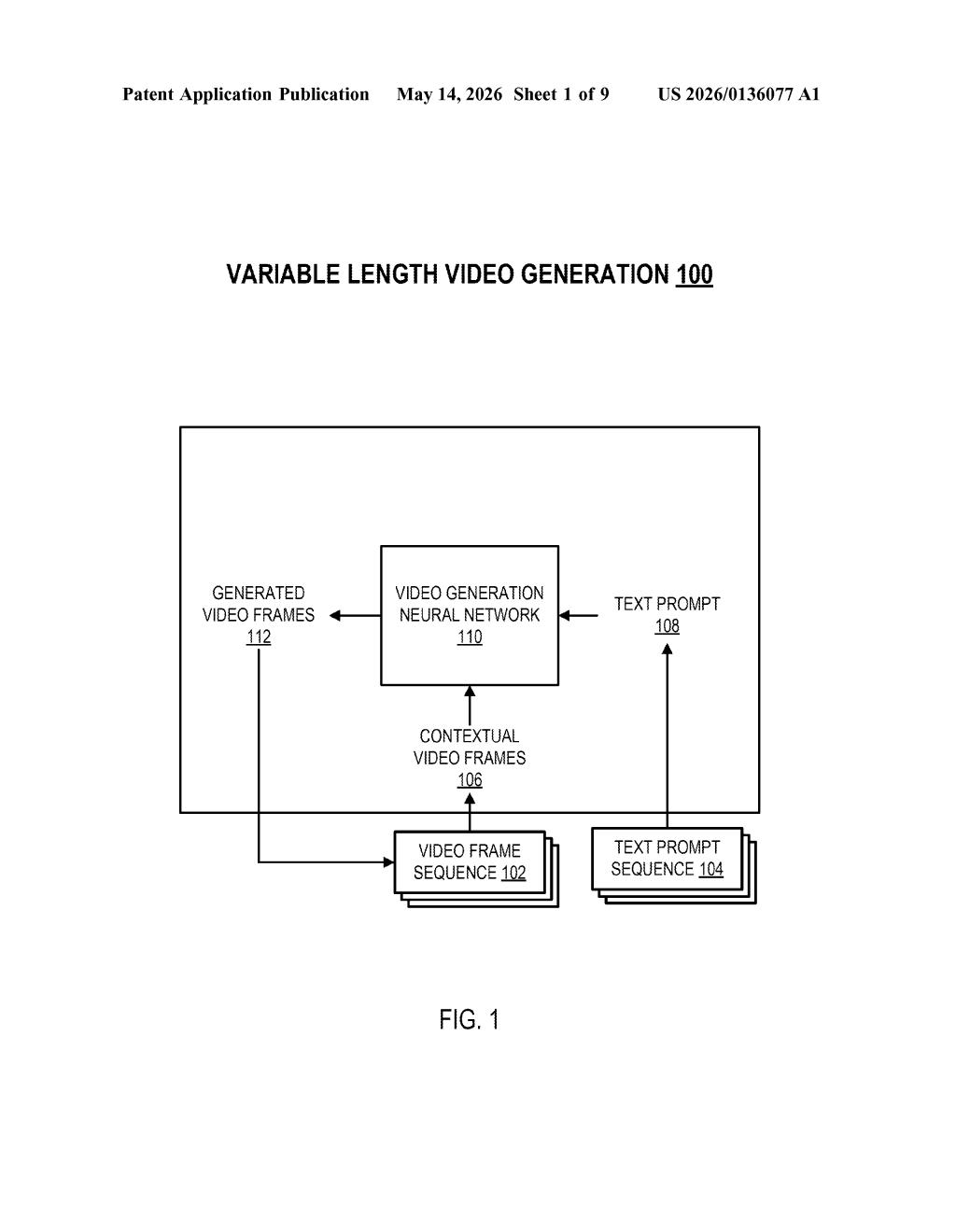
How Google's iterative text-to-video generation works
Imagine asking an AI to make you a short video of a dog running through a park. Now imagine being able to say, "now it starts to rain" and have the AI seamlessly continue that same video with a new scene — without starting over from scratch. That's the core idea here.
Google's patent describes a video generation system where you feed it an initial text description, it produces the first chunk of video, and then you can keep feeding it new descriptions to extend the video indefinitely. Each new segment picks up right where the last frame left off, so the result looks like one continuous piece of footage.
The key trick is that each new segment isn't generated in isolation — the AI looks back at the frames it already made and uses them as context, keeping things visually consistent as the story evolves. You're essentially co-directing an AI film, one prompt at a time.
How the neural network chains segments using prior frames
The system centers on a video generation neural network that operates in rounds. In round one, you provide a text prompt and the model generates an initial segment — a sequence of frames covering the first stretch of time in the video.
For each subsequent round (called an update iteration), the process repeats with two inputs:
- A new text prompt describing what should happen next
- One or more contextual video frames from the segment already generated — essentially a visual "memory" of where things left off
The model generates the next segment conditioned on both inputs, meaning the new frames are constrained to be visually and temporally consistent with what came before. The claim specifies that the new segment covers time steps immediately following the last frame of the existing video, so there are no gaps or jumps.
This iterative loop can repeat as many times as needed, producing a video of theoretically unlimited length. The architecture reuses the same neural network across all iterations rather than requiring a separate model for extensions, which matters for computational efficiency and consistency of visual style.
What this means for long-form AI video generation
Today's text-to-video tools — including Google's own Lumiere and Veo models — typically produce clips capped at a few seconds or a fixed number of frames. This patent describes the scaffolding needed to push beyond that ceiling, enabling coherent longer-form video without the jarring discontinuities you'd get from just concatenating separately generated clips.
For creators, this could eventually mean generating narrative videos — a product demo, a short film scene, an explainer — by writing a loose script of prompts rather than painstakingly editing together AI-generated fragments. The practical challenge, which the patent doesn't fully solve, is drift: keeping characters, lighting, and style stable across many iterations. But locking down the architecture for variable-length generation is the necessary first step.
This is solid foundational work, not a flashy demo patent. The iterative, prompt-chained approach to video generation is a genuinely sensible design for getting past the fixed-length bottleneck in current models. Google has been aggressive in the text-to-video space with Veo, and this patent reads like the plumbing behind a feature that's probably already in internal testing.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.