Adobe Patents an AI System That Converts Webpages Into Custom Code
Imagine taking any existing webpage and instantly getting clean, platform-ready code for your CMS — no copy-pasting, no manual reformatting. That's the core idea behind Adobe's latest patent filing.
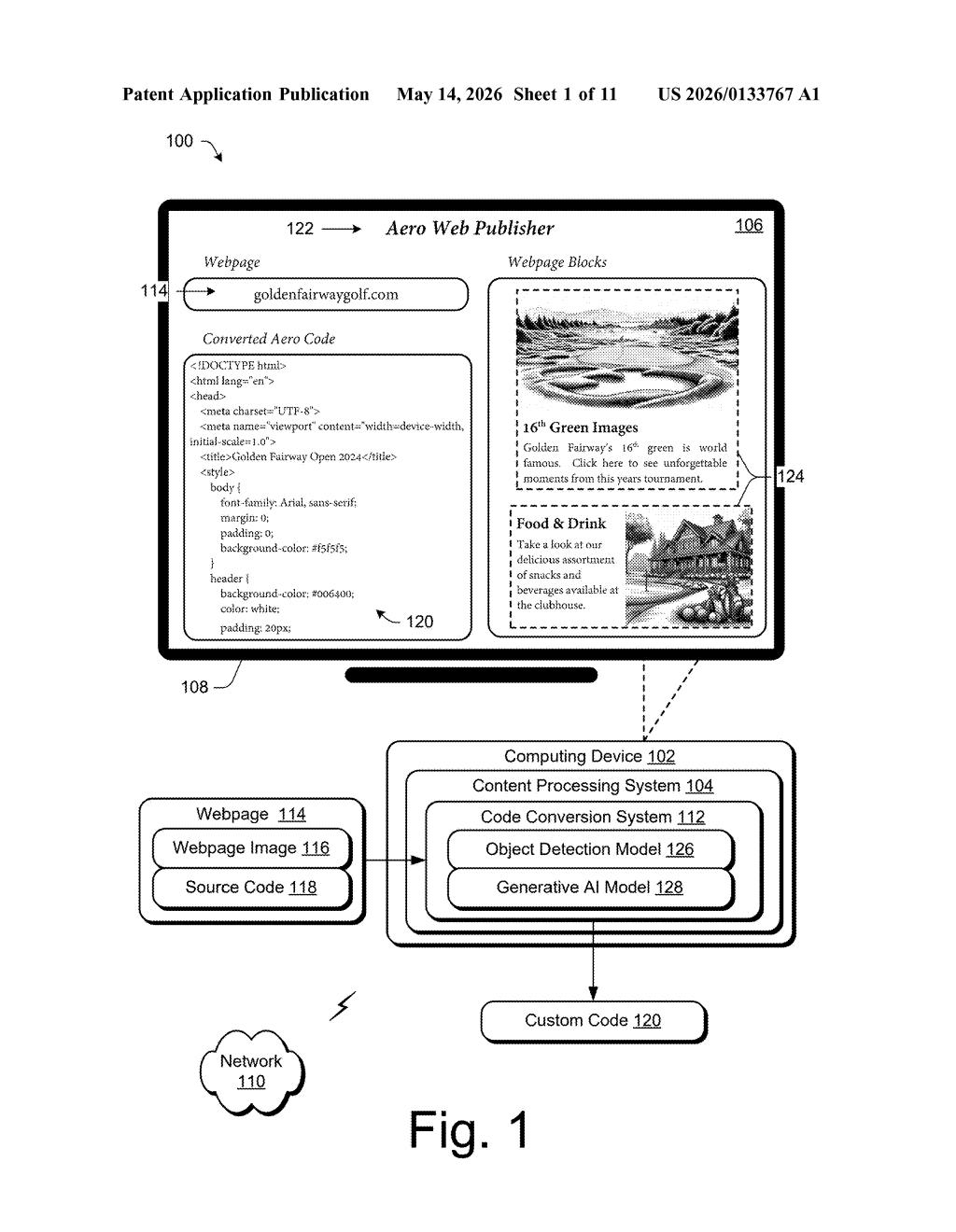
What Adobe's AI webpage converter actually does
Picture this: you find a webpage you love and want to rebuild something similar in your own content management system. Right now, that means hours of manually dissecting the layout, copying text, and rewriting code by hand. Adobe's patent describes a system that automates most of that grunt work.
The system takes a screenshot or digital image of a webpage and uses an AI model to identify its building blocks — things like headers, image galleries, or text sections. It figures out what type of block each one is, then pulls the actual content (text, links, images) from the original page's source code.
With all that context in hand, a generative AI model produces fresh code formatted specifically for your target publishing platform. Think of it like a smart translator that doesn't just move words — it understands the structure and rebuilds it natively for wherever you're publishing.
How object detection and generative AI split the work
The patent describes a code conversion system with two AI-powered stages working in sequence.
First, an object detection model analyzes a digital image of a webpage (essentially a screenshot). It identifies discrete webpage blocks — self-contained layout units like a hero banner, a navigation bar, or a content card — and assigns each one a block class (a semantic label like 'image-gallery' or 'text-column'). This is computer vision doing layout parsing, essentially teaching a machine to read a page the way a designer would.
Second, the system extracts the actual webpage content — text, links, metadata — directly from the page's underlying HTML source code. This keeps the content accurate rather than relying on OCR from the screenshot alone.
Finally, a generative AI model takes all three inputs — the visual block, its class label, and the extracted content — and produces custom code formatted for a specific webpage publication system (the patent references something called 'Aero Web Publisher' in its diagrams). The output isn't generic HTML; it's structured code tailored to the target platform's conventions and components.
What this means for Adobe's web publishing tools
For Adobe, this fits neatly into its broader push to make Adobe Express and its web publishing tools more attractive to non-developers. If you can point at any webpage and get platform-native code out the other end, migration and rapid prototyping become dramatically faster.
The bigger picture: this is essentially automated design-to-code migration. Agencies that rebuild client sites, developers who port legacy pages to modern CMS platforms, and no-code users who want to replicate a layout without starting from scratch all stand to benefit. Whether Adobe ships this as a standalone feature or folds it into an existing product like Adobe Experience Manager isn't clear from the filing — but the use case is real and the demand is obvious.
This is a genuinely practical patent — not flashy AI for its own sake, but a clear workflow problem with a sensible two-stage solution. The combination of object detection for layout parsing and generative AI for code synthesis is a clean architecture. The real question is whether the generated code is actually production-quality or just a rough scaffold, and the patent doesn't settle that.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.