IBM Patents an ML System That Writes Requirements Documents Automatically
Writing requirements documents is one of the most tedious — and error-prone — parts of any software project. IBM is filing a patent for a system that uses generative AI to do it for you, pulling from a knowledge base of past project checkpoints.
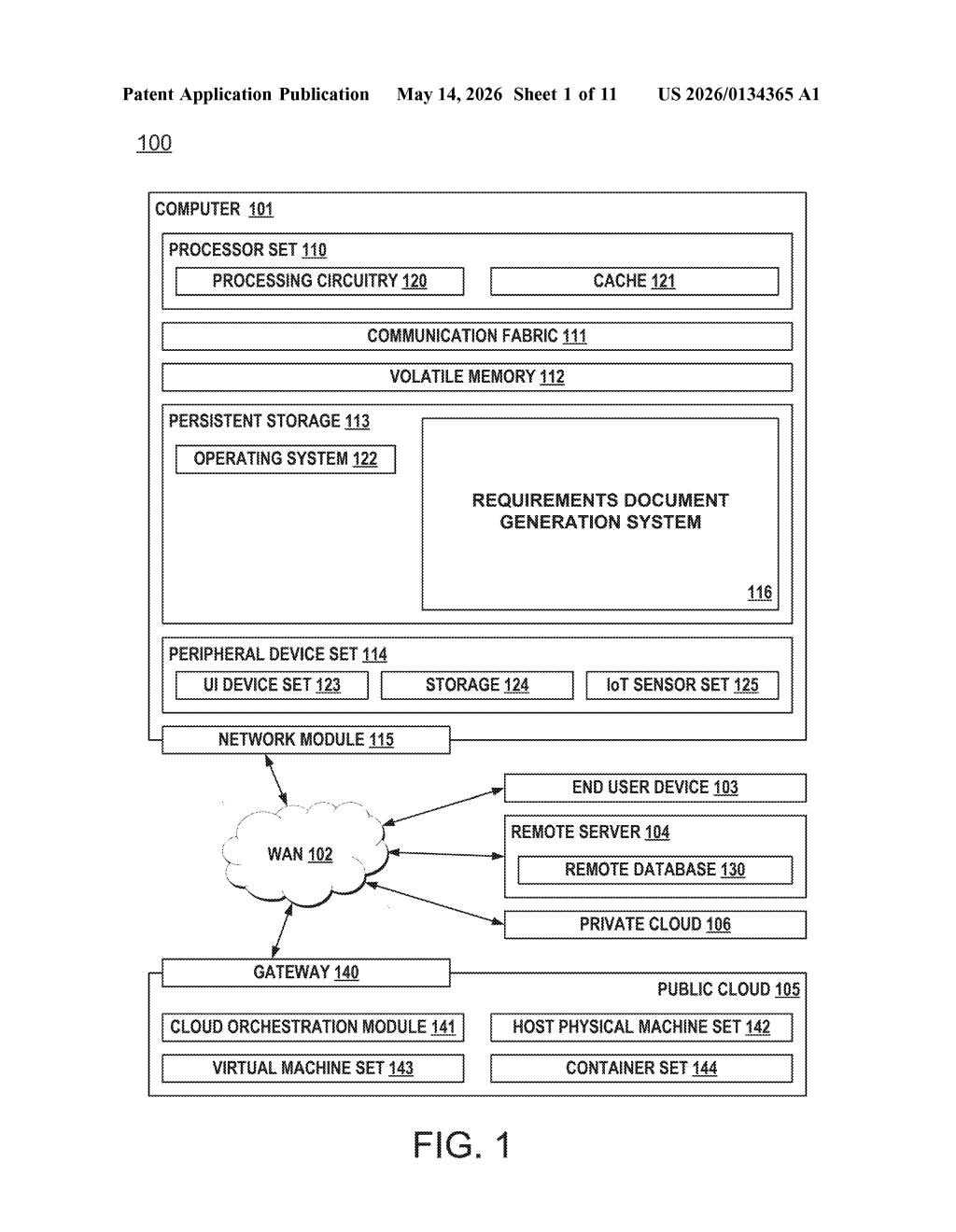
What IBM's auto-requirements generator actually does
Imagine your team just kicked off a new enterprise software project. Before anyone writes a line of code, someone has to produce a requirements document — a formal write-up of what the system needs to do, who it serves, and what tools are recommended. That document usually takes days and relies heavily on whoever wrote the last one remembering the right things.
IBM's patented approach automates a big chunk of that work. The system pulls in a list of checkpoints — think standard questions or criteria that projects are evaluated against — along with answers to those checkpoints drawn from a domain knowledge base (basically, a library of institutional knowledge from past projects). It then filters that pool of checkpoints down to just the ones relevant to your specific system.
From there, a generative AI model refines the answers to make them more precise and context-aware, then produces an actual document with objectives and recommendations tailored to your system. The example in the patent shows output that looks like a real requirements doc — complete with personas, objectives, and tool recommendations.
How IBM's pipeline filters checkpoints and refines answers
The system operates as a four-stage pipeline:
- Extraction: The system pulls checkpoints (structured criteria or evaluation questions applied to projects) and their corresponding answers from a domain knowledge base — a curated repository of past project outcomes and institutional know-how.
- Filtering: Not all checkpoints are relevant to every system. A filtering criteria layer trims the full set down to a subset of checkpoints and answers that apply to the target system being documented.
- Answer refinement: A generative ML model (think a large language model or similar) takes the filtered subset and refines the answers — essentially improving their quality, coherence, and specificity relative to the checkpoints.
- Document generation: The same generative model then synthesizes everything into a structured requirements document that includes objectives (what the system should achieve) and recommendations (which tools, approaches, or architectures to use).
The patent's example output shows a document section covering real-time customer data integration, with a persona tag (Sales and Marketing Team), stated objectives, and a specific tool recommendation — suggesting the output is meant to be production-ready, not just a rough draft.
The claim is intentionally broad about what the generative ML model looks like, which means the architecture could accommodate a range of underlying models.
What this means for enterprise software delivery teams
For large enterprises — IBM's core customer base — requirements documentation is a genuine bottleneck. Projects stall, scope creeps, and institutional knowledge walks out the door when experienced architects move on. A system that can tap a structured knowledge base and produce consistent, tailored documents could meaningfully reduce that friction.
The deeper play here is probably IBM Consulting or IBM's software delivery toolchain. Watson-era IBM spent years trying to encode enterprise knowledge into AI systems; this patent reads like a more pragmatic, LLM-era version of that ambition. If IBM can plug this into its existing project delivery workflows, it's not just an automation trick — it's a way to retain and reuse hard-won institutional knowledge at scale.
This is a narrow but genuinely useful idea — the kind of unglamorous enterprise AI work that actually ships and saves real hours. It's not trying to solve a research problem; it's trying to automate a document that every project needs and almost nobody enjoys writing. The interesting technical question is how well the filtering step works in practice, because garbage in still means garbage out regardless of how good the generative model is.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.