Waymo Patents an On-Board Vision-Language Model That Answers Questions About the Road Ahead
Waymo is patenting a system that lets different parts of a self-driving car ask a vision-language model focused questions about specific patches of the camera feed — not the whole scene at once, but a targeted region. It's like giving each subsystem of the car its own magnifying glass, plus the ability to ask a question about whatever it's looking at.
What Waymo's on-board VLM actually does for self-driving
Imagine your self-driving car's planning system notices something odd in the upper-left corner of the road ahead. Instead of re-processing the entire camera image from scratch, it can highlight just that patch and ask: "Is that a pedestrian stepping off the curb?" — and get a direct answer in plain terms.
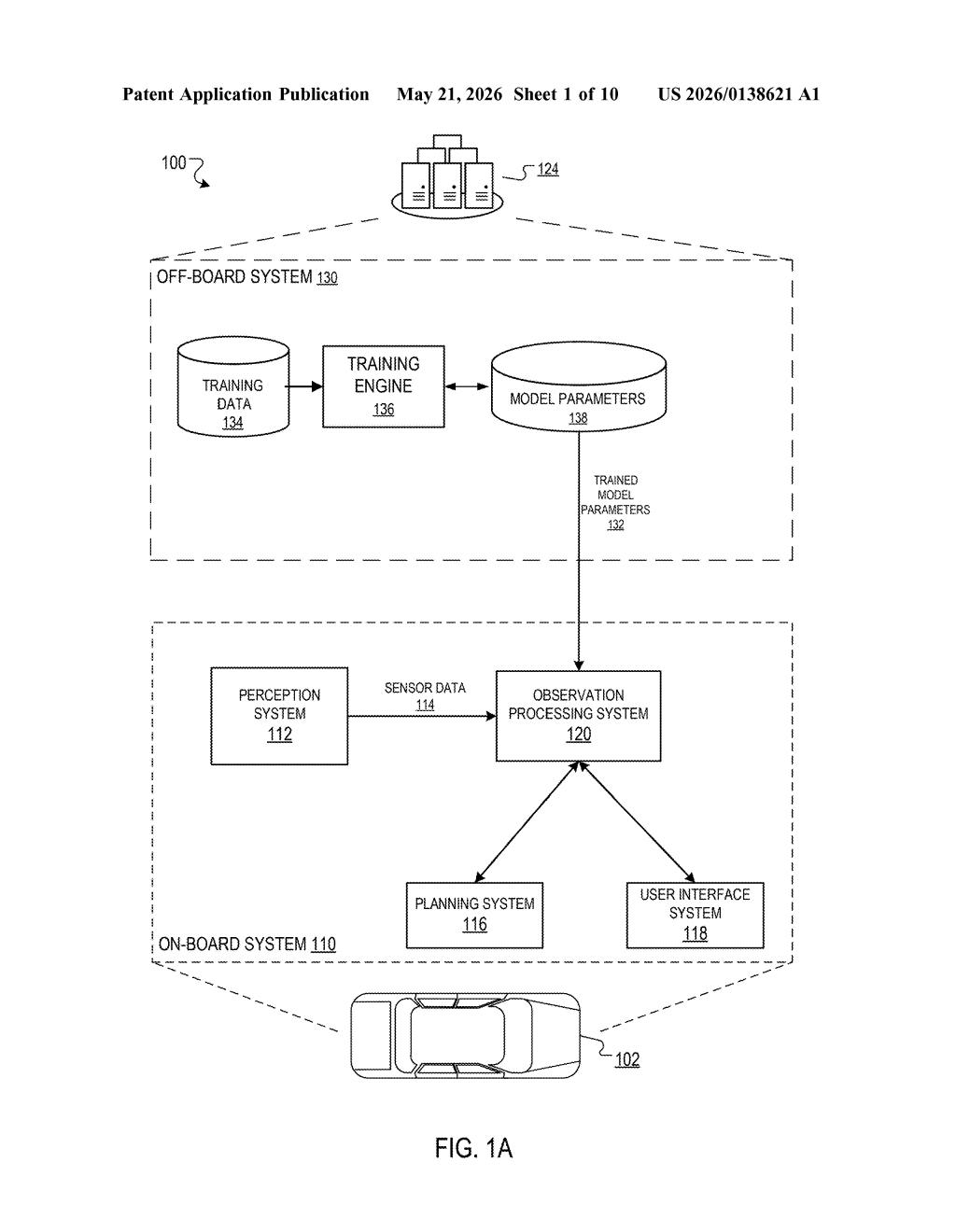
That's the core idea here. Waymo's patent describes a single neural network that sits on the vehicle and processes incoming camera data into a rich feature map covering every point in the scene. Different subsystems — the planner, the perception stack, whatever else — can then submit a region proposal (basically a bounding box or spatial query) along with a task description, and the model returns a focused prediction for just that area.
The practical upside is efficiency: you're not running a full scene-understanding pass every time a downstream system needs one specific answer. You encode the scene once, then query it repeatedly. For a real-time driving system where milliseconds matter, that kind of architecture could make a meaningful difference.
How the region proposal pipeline focuses the model's attention
The patent describes a three-stage pipeline running entirely on the vehicle's onboard hardware:
- Observation embedding: Raw sensor data (camera frames, and potentially other inputs) are fed through an observation embedding neural network — think of it as a single pass that converts the scene into a dense grid of features, one feature vector per spatial location. This is done once per frame.
- Region proposal intake: A subsystem (say, the motion planner or a perception module) sends two things: a region proposal specifying a spatial area of interest within that scene, and a task description expressed as data — likely text or a tokenized query, consistent with how vision-language models work.
- Region feature extraction + prediction: The system crops or pools the pre-computed feature map down to just the specified region, generating region features. Those region features are then combined with the task description and passed through a final network to produce the output prediction — a structured answer to the subsystem's question.
The architecture mirrors patterns from large vision-language models (VLMs — models that understand both images and text together), but is designed to run on-board rather than in a cloud server. The region-proposal mechanism is similar in spirit to ROI pooling used in object detection networks, but here it's generalized to support arbitrary natural-language-style prediction tasks rather than just bounding-box classification.
Why a queryable scene model changes autonomous vehicle design
The traditional approach to autonomous vehicle perception is a pipeline of specialized models — one for lane detection, one for pedestrian tracking, one for traffic sign reading, and so on. That's expensive to maintain and hard to generalize. A single queryable scene model that any subsystem can interrogate changes the architectural calculus significantly: you get shared compute, shared representations, and a more flexible interface between perception and planning.
For you as a rider or observer, the implication is a system that can handle more nuanced or unusual situations — the ones that don't fit neatly into a predefined detection category. If Waymo can make this work reliably at inference speed on vehicle hardware, it's a meaningful step toward perception systems that reason about the world rather than just classify it.
This is one of the more architecturally interesting autonomous vehicle patents in recent memory. The idea of separating scene encoding from task-specific querying — and doing it all on the vehicle — is a clean engineering insight that reflects how the broader AI field has moved toward foundation models. Whether Waymo can actually run something like this at the latency and reliability standards required for safety-critical driving is the real question, but the patent signals they're seriously investing in the direction.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.